标签:受限 功能 pen cache domain grep was 很多 根据
1、安装要求在开始之前,部署Kubernetes集群机器需要满足以下几个条件:
| 角色 | IP |
|---|---|
k8s-lb |
192.168.50.100 |
master1 |
192.168.50.128 |
master2 |
192.168.50.129 |
master3 |
192.168.50.130 |
node1 |
192.168.50.131 |
node2 |
192.168.50.132 |
master1节点设置:
~]# hostnamectl set-hostname master1master2节点设置:
~]# hostnamectl set-hostname master2master3节点设置:
~]# hostnamectl set-hostname master3node1从节点设置:
~]# hostnamectl set-hostname node1node2从节点设置:
~]# hostnamectl set-hostname node2执行bash命令以加载新设置的主机名
hosts所有的节点都要添加hosts解析记录
~]# cat >>/etc/hosts <<EOF
192.168.50.100 k8s-lb
192.168.50.128 master1
192.168.50.129 master2
192.168.50.130 master3
192.168.50.131 node1
192.168.50.132 node2
EOF在master1节点生成密钥对,并分发给其他的所有主机。
[root@master1 ~]# ssh-keygen -t rsa -b 1200
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:OoMw1dARsWhbJKAQL2hUxwnM4tLQJeLynAQHzqNQs5s root@localhost.localdomain
The key‘s randomart image is:
+---[RSA 1200]----+
|*=X=*o*+ |
|OO.*.O.. |
|BO= + + |
|**o* o |
|o E . S |
| o . . |
| . + |
| o |
| |
+----[SHA256]-----+
[root@master1 ~]# ssh-copy-id -i ~/.ssh/id_rsa.pub root@master1
[root@master1 ~]# ssh-copy-id -i ~/.ssh/id_rsa.pub root@master2
[root@master1 ~]# ssh-copy-id -i ~/.ssh/id_rsa.pub root@master3
[root@master1 ~]# ssh-copy-id -i ~/.ssh/id_rsa.pub root@node1
[root@master1 ~]# ssh-copy-id -i ~/.ssh/id_rsa.pub root@node2通过下载kernel image的rpm包进行安装。
centos7系统:http://elrepo.org/linux/kernel/el7/x86_64/RPMS/
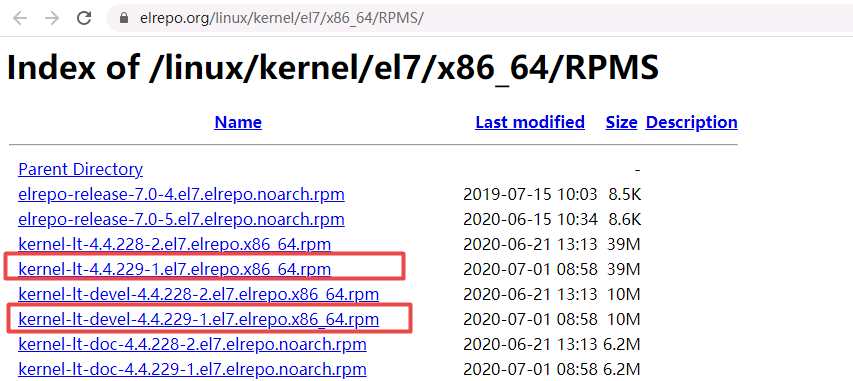
编写shell脚本升级内核
#!/bin/bash
# ----------------------------
# upgrade kernel by bomingit@126.com
# ----------------------------
yum localinstall -y kernel-lt*
if [ $? -eq 0 ];then
grub2-set-default 0 && grub2-mkconfig -o /etc/grub2.cfg
grubby --args="user_namespace.enable=1" --update-kernel="$(grubby --default-kernel)"
fi
echo "please reboot your system quick!!!"注意:一定要重启机器
[root@master1 ~]# uname -r
4.4.229-1.el7.elrepo.x86_64selinux~]# systemctl disable --now firewalld
~]# setenforce 0
~]# sed -i ‘s/enforcing/disabled/‘ /etc/selinux/config 上面的是临时关闭,当然也可以永久关闭,即在/etc/fstab文件中将swap挂载所在的行注释掉即可。
swap分区~]# swapoff -a
~]# sed -i.bak ‘s/^.*centos-swap/#&/g‘ /etc/fstab第一条是临时关闭,当然也可以使用第二条永久关闭,后者手动在/etc/fstab文件中将swap挂载所在的行注释掉即可。
~]# cat > /etc/sysctl.d/k8s.conf << EOF
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
fs.may_detach_mounts = 1
vm.overcommit_memory=1
vm.panic_on_oom=0
fs.inotify.max_user_watches=89100
fs.file-max=52706963
fs.nr_open=52706963
net.ipv4.tcp_keepalive_time = 600
net.ipv4.tcp.keepaliv.probes = 3
net.ipv4.tcp_keepalive_intvl = 15
net.ipv4.tcp.max_tw_buckets = 36000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp.max_orphans = 327680
net.ipv4.tcp_orphan_retries = 3
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog = 16384
net.ipv4.ip_conntrack_max = 65536
net.ipv4.tcp_max_syn_backlog = 16384
net.ipv4.top_timestamps = 0
net.core.somaxconn = 16384
EOF使其立即生效
~]# sysctl --systemyum源所有的节点均采用阿里云官网的base和epel源
~]# mv /etc/yum.repos.d/* /tmp
~]# curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
~]# curl -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo~]# ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
~]# yum install dnf ntpdate -y
~]# ntpdate ntp.aliyun.comshell将上面的第5-8步骤写成shell脚本自动化快速完成
#!/bin/sh
#****************************************************************#
# ScriptName: init.sh
# Author: boming
# Create Date: 2020-06-23 22:19
#***************************************************************#
#关闭防火墙
systemctl disable --now firewalld
setenforce 0
sed -i ‘s/enforcing/disabled/‘ /etc/selinux/config
#关闭swap分区
swapoff -a
sed -i.bak ‘s/^.*centos-swap/#&/g‘ /etc/fstab
#优化系统
cat > /etc/sysctl.d/k8s.conf << EOF
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
fs.may_detach_mounts = 1
vm.overcommit_memory=1
vm.panic_on_oom=0
fs.inotify.max_user_watches=89100
fs.file-max=52706963
fs.nr_open=52706963
net.ipv4.tcp_keepalive_time = 600
net.ipv4.tcp.keepaliv.probes = 3
net.ipv4.tcp_keepalive_intvl = 15
net.ipv4.tcp.max_tw_buckets = 36000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp.max_orphans = 327680
net.ipv4.tcp_orphan_retries = 3
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog = 16384
net.ipv4.ip_conntrack_max = 65536
net.ipv4.tcp_max_syn_backlog = 16384
net.ipv4.top_timestamps = 0
net.core.somaxconn = 16384
EOF
#立即生效
sysctl --system
#配置阿里云的base和epel源
mv /etc/yum.repos.d/* /tmp
curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
curl -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
#安装dnf工具
yum install dnf -y
dnf makecache
#安装ntpdate工具
dnf install ntpdate -y
#同步阿里云时间
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
ntpdate ntp.aliyun.com在其他的节点执行此脚本跑一下即可。
dockerdocker软件yum源方法:浏览器打开mirrors.aliyun.com网站,找到docker-ce,即可看到镜像仓库源
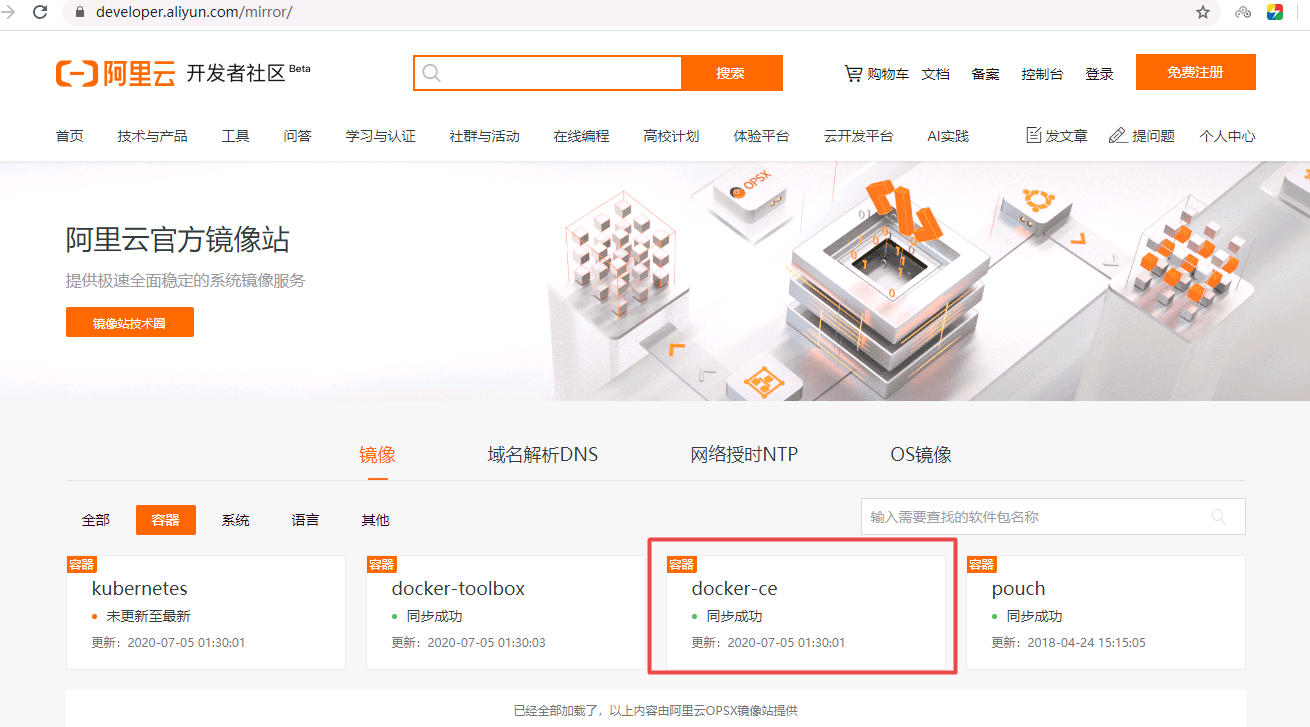
~]# curl -o /etc/yum.repos.d/docker-ce.repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
~]# cat /etc/yum.repos.d/docker-ce.repo
[docker-ce-stable]
name=Docker CE Stable - $basearch
baseurl=https://mirrors.aliyun.com/docker-ce/linux/centos/7/$basearch/stable
enabled=1
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/docker-ce/linux/centos/gpg
...
...docker-ce组件列出所有可以安装的版本
~]# dnf list docker-ce --showduplicates
docker-ce.x86_64 3:18.09.6-3.el7 docker-ce-stable
docker-ce.x86_64 3:18.09.7-3.el7 docker-ce-stable
docker-ce.x86_64 3:18.09.8-3.el7 docker-ce-stable
docker-ce.x86_64 3:18.09.9-3.el7 docker-ce-stable
docker-ce.x86_64 3:19.03.0-3.el7 docker-ce-stable
docker-ce.x86_64 3:19.03.1-3.el7 docker-ce-stable
docker-ce.x86_64 3:19.03.2-3.el7 docker-ce-stable
docker-ce.x86_64 3:19.03.3-3.el7 docker-ce-stable
docker-ce.x86_64 3:19.03.4-3.el7 docker-ce-stable
docker-ce.x86_64 3:19.03.5-3.el7 docker-ce-stable
.....这里我们安装最新版本的docker,所有的节点都需要安装docker服务
~]# dnf install -y docker-ce docker-ce-clidocker并设置开机自启动~]# systemctl enable --now docker查看版本号,检测docker是否安装成功
~]# docker --version
Docker version 19.03.12, build 48a66213fea上面的这种查看docker client的版本的。建议使用下面这种方法查看docker-ce版本号,这种方法把docker的client端和server端的版本号查看的一清二楚。
~]# docker version
Client:
Version: 19.03.12
API version: 1.40
Go version: go1.13.10
Git commit: 039a7df9ba
Built: Wed Sep 4 16:51:21 2019
OS/Arch: linux/amd64
Experimental: false
Server: Docker Engine - Community
Engine:
Version: 19.03.12
API version: 1.40 (minimum version 1.12)
Go version: go1.13.10
Git commit: 039a7df
Built: Wed Sep 4 16:22:32 2019
OS/Arch: linux/amd64
Experimental: falsedocker的镜像仓库源默认的镜像仓库地址是docker官方的,国内访问异常缓慢,因此更换为个人阿里云的源。
~]# cat > /etc/docker/daemon.json << EOF
{
"registry-mirrors": ["https://f1bhsuge.mirror.aliyuncs.com"]
}
EOF由于重新加载docker仓库源,所以需要重启docker
~]# systemctl restart dockerkuberneteskubernetes软件yum源方法:浏览器打开mirrors.aliyun.com网站,找到kubernetes,即可看到镜像仓库源
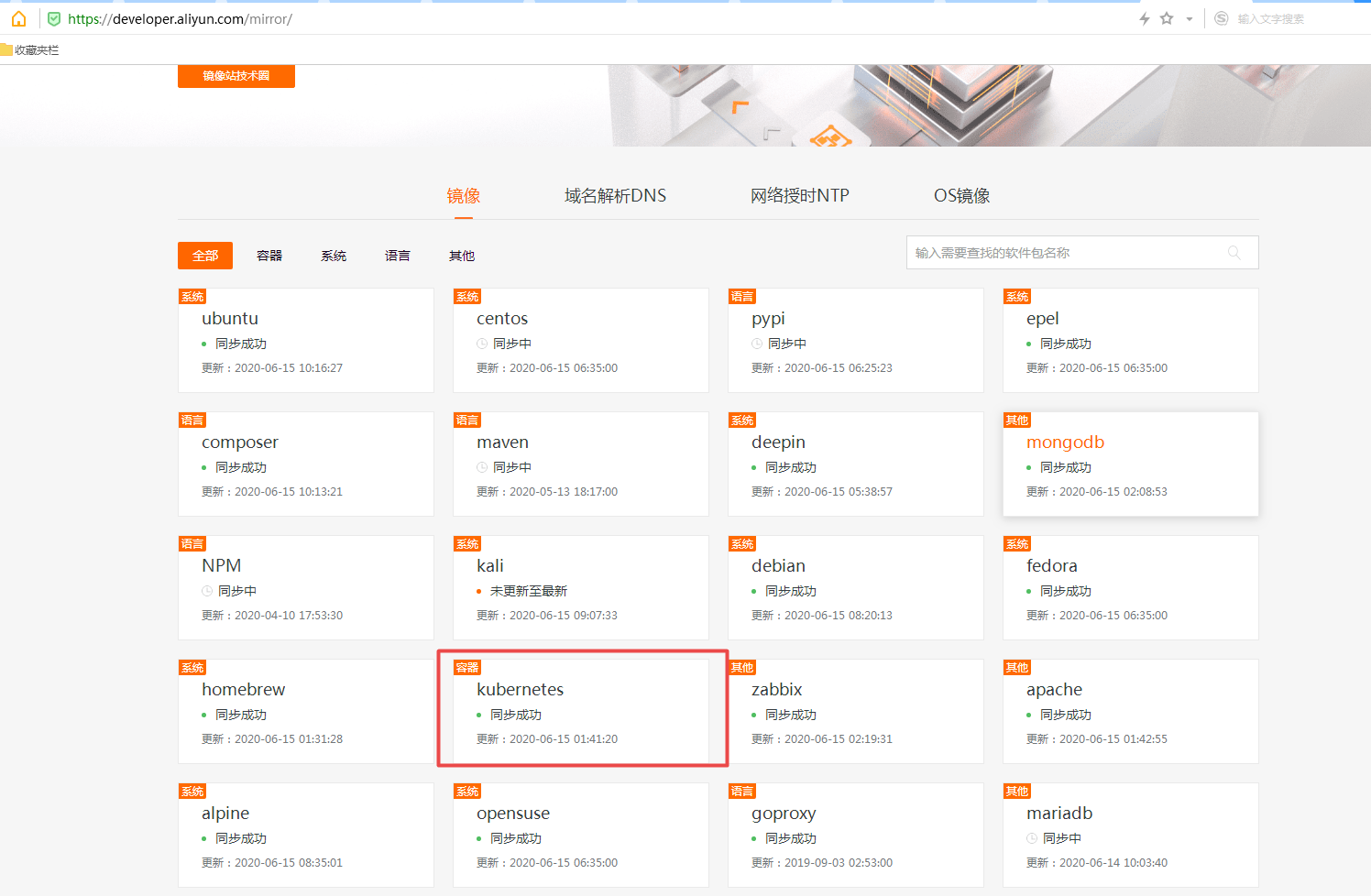
~]# cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF最好是重新生成缓存
~]# dnf clean all
~]# dnf makecachekubeadm、kubelet和kubectl组件所有的节点都需要安装这几个组件。
[root@master1 ~]# dnf list kubeadm --showduplicates
kubeadm.x86_64 1.17.7-0 kubernetes
kubeadm.x86_64 1.17.7-1 kubernetes
kubeadm.x86_64 1.17.8-0 kubernetes
kubeadm.x86_64 1.17.9-0 kubernetes
kubeadm.x86_64 1.18.0-0 kubernetes
kubeadm.x86_64 1.18.1-0 kubernetes
kubeadm.x86_64 1.18.2-0 kubernetes
kubeadm.x86_64 1.18.3-0 kubernetes
kubeadm.x86_64 1.18.4-0 kubernetes
kubeadm.x86_64 1.18.4-1 kubernetes
kubeadm.x86_64 1.18.5-0 kubernetes
kubeadm.x86_64 1.18.6-0 kubernetes由于kubernetes版本变更非常快,因此列出有哪些版本,选择一个合适的。我们这里安装1.18.6版本。
[root@master1 ~]# dnf install -y kubelet-1.18.6 kubeadm-1.18.6 kubectl-1.18.6我们先设置开机自启,但是
kubelet服务暂时先不启动。
[root@master1 ~]# systemctl enable kubeletHaproxy+Keepalived配置高可用VIP高可用我们采用官方推荐的HAproxy+Keepalived,HAproxy和Keepalived以守护进程的方式在所有Master节点部署。
keepalived和haproxy注意:只需要在三个master节点安装即可
[root@master1 ~]# dnf install -y keepalived haproxy Haproxy服务所有master节点的haproxy配置相同,haproxy的配置文件是/etc/haproxy/haproxy.cfg。master1节点配置完成之后再分发给master2、master3两个节点。
global
maxconn 2000
ulimit-n 16384
log 127.0.0.1 local0 err
stats timeout 30s
defaults
log global
mode http
option httplog
timeout connect 5000
timeout client 50000
timeout server 50000
timeout http-request 15s
timeout http-keep-alive 15s
frontend monitor-in
bind *:33305
mode http
option httplog
monitor-uri /monitor
listen stats
bind *:8006
mode http
stats enable
stats hide-version
stats uri /stats
stats refresh 30s
stats realm Haproxy\ Statistics
stats auth admin:admin
frontend k8s-master
bind 0.0.0.0:8443
bind 127.0.0.1:8443
mode tcp
option tcplog
tcp-request inspect-delay 5s
default_backend k8s-master
backend k8s-master
mode tcp
option tcplog
option tcp-check
balance roundrobin
default-server inter 10s downinter 5s rise 2 fall 2 slowstart 60s maxconn 250 maxqueue 256 weight 100
server master1 192.168.50.128:6443 check inter 2000 fall 2 rise 2 weight 100
server master2 192.168.50.129:6443 check inter 2000 fall 2 rise 2 weight 100
server master3 192.168.50.130:6443 check inter 2000 fall 2 rise 2 weight 100注意这里的三个master节点的ip地址要根据你自己的情况配置好。
Keepalived服务keepalived中使用track_script机制来配置脚本进行探测kubernetes的master节点是否宕机,并以此切换节点实现高可用。
master1节点的keepalived配置文件如下所示,配置文件所在的位置/etc/keepalived/keepalived.cfg。
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
}
vrrp_script chk_kubernetes {
script "/etc/keepalived/check_kubernetes.sh"
interval 2
weight -5
fall 3
rise 2
}
vrrp_instance VI_1 {
state MASTER
interface ens33
mcast_src_ip 192.168.50.128
virtual_router_id 51
priority 100
advert_int 2
authentication {
auth_type PASS
auth_pass K8SHA_KA_AUTH
}
virtual_ipaddress {
192.168.50.100
}
# track_script {
# chk_kubernetes
# }
}需要注意几点(前两点记得修改):
mcast_src_ip:配置多播源地址,此地址是当前主机的ip地址。priority:keepalived根据此项参数的大小仲裁master节点。我们这里让master节点为kubernetes提供服务,其他两个节点暂时为备用节点。因此master1节点设置为100,master2节点设置为99,master3节点设置为98。state:我们将master1节点的state字段设置为MASTER,其他两个节点字段修改为BACKUP。我这里将健康检测脚本放置在/etc/keepalived目录下,check_kubernetes.sh检测脚本如下:
#!/bin/bash
#****************************************************************#
# ScriptName: check_kubernetes.sh
# Author: boming
# Create Date: 2020-06-23 22:19
#***************************************************************#
function chech_kubernetes() {
for ((i=0;i<5;i++));do
apiserver_pid_id=$(pgrep kube-apiserver)
if [[ ! -z $apiserver_pid_id ]];then
return
else
sleep 2
fi
apiserver_pid_id=0
done
}
# 1:running 0:stopped
check_kubernetes
if [[ $apiserver_pid_id -eq 0 ]];then
/usr/bin/systemctl stop keepalived
exit 1
else
exit 0
fi根据上面的注意事项配置master2、master3节点的keepalived服务。
Keeplived和Haproxy服务~]# systemctl enable --now keepalived haproxy确保万一,查看一下服务状态
~]# systemctl status keepalived haproxy
~]# ping 192.168.50.100 #检测一下是否通
PING 192.168.50.100 (192.168.50.100) 56(84) bytes of data.
64 bytes from 192.168.50.100: icmp_seq=1 ttl=64 time=0.778 ms
64 bytes from 192.168.50.100: icmp_seq=2 ttl=64 time=0.339 msMaster节点在master节点执行如下指令:
[root@master1 ~]# kubeadm config print init-defaults > kubeadm-init.yaml这个文件kubeadm-init.yaml,是我们初始化使用的文件,里面大概修改这几项参数。
[root@master1 ~]# cat kubeadm-init.yaml
apiVersion: kubeadm.k8s.io/v1beta2
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.50.100 #VIP的地址
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
name: master1
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
---
apiServer: #添加如下两行信息
certSANs:
- "192.168.50.100" #VIP地址
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers #阿里云的镜像站点
controlPlaneEndpoint: "192.168.50.100:8443" #VIP的地址和端口
kind: ClusterConfiguration
kubernetesVersion: v1.18.3 #kubernetes版本号
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12 #选择默认即可,当然也可以自定义CIDR
podSubnet: 10.244.0.0/16 #添加pod网段
scheduler: {}注意:上面的advertiseAddress字段的值,这个值并非当前主机的网卡地址,而是高可用集群的VIP的地址。
注意:上面的controlPlaneEndpoint这里填写的是VIP的地址,而端口则是haproxy服务的8443端口,也就是我们在haproxy里面配置的这段信息。
frontend k8s-master
bind 0.0.0.0:8443
bind 127.0.0.1:8443
mode tcp这一段里面的8443端,如果你自定义了其他端口,这里请记得修改controlPlaneEndpoint里面的端口。
如果直接采用kubeadm init来初始化,中间会有系统自动拉取镜像的这一步骤,这是比较慢的,我建议分开来做,所以这里就先提前拉取镜像。
[root@master1 ~]# kubeadm config images pull --config kubeadm-init.yaml
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-apiserver:v1.18.0
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-controller-manager:v1.18.0
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-scheduler:v1.18.0
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-proxy:v1.18.0
[config/images] Pulled registry.aliyuncs.com/google_containers/pause:3.1
[config/images] Pulled registry.aliyuncs.com/google_containers/etcd:3.4.3-0
[config/images] Pulled registry.aliyuncs.com/google_containers/coredns:1.6.5如果大家看到开头的两行warning信息(我这里没有打印),不必担心,这只是警告,不影响我们完成实验。
master节点提前拉取镜像其他两个master节点在初始化之前也尽量先把镜像拉取下来,这样子减少初始化时间
[root@master1 ~]# scp kubeadm-init.yaml root@master2:~
[root@master1 ~]# scp kubeadm-init.yaml root@master3:~master2节点
# 注意在master2节点执行如下命令
[root@master2 ~]# kubeadm config images pull --config kubeadm-init.yamlmaster3节点
# 注意在master3节点执行如下命令
[root@master3 ~]# kubeadm config images pull --config kubeadm-init.yamlkubenetes的master1节点执行如下命令
[root@master1 ~]# kubeadm init --config kubeadm-init.yaml --upload-certs
[init] Using Kubernetes version: v1.18.3
[preflight] Running pre-flight checks
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using ‘kubeadm config images pull‘
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[certs] apiserver serving cert is signed for DNS names [master1 kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 192.168.50.128 192.168.50.100]
... # 省略
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node master1 as control-plane by adding the label "node-role.kubernetes.io/master=‘‘"
[mark-control-plane] Marking the node master1 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[addons] Applied essential addon: CoreDNS
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join 192.168.50.100:8443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:4c738bc8e2684c5d52d80687d48925613b66ab660403649145eb668d71d85648 --control-plane --certificate-key 4931f39d3f53351cb6966a9dcc53cb5cbd2364c6d5b83e50e258c81fbec69539
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.50.100:8443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:4c738bc8e2684c5d52d80687d48925613b66ab660403649145eb668d71d85648这个过程大概30s的时间就做完了,之所以初始化的这么快就是因为我们提前拉取了镜像。像我上面这样的没有报错信息,并且显示上面的最后10行类似的信息这些,说明我们的master1节点是初始化成功的。
在使用集群之前还需要做些收尾工作,在master1节点执行:
[root@master1 ~]# mkdir -p $HOME/.kube
[root@master1 ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@master1 ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config再配置一下环境变量
[root@master1 ~]# cat >> ~/.bashrc <<EOF
export KUBECONFIG=/etc/kubernetes/admin.conf
EOF
[root@master1 ~]# source ~/.bashrc好了,此时的master1节点就算是初始化完毕了。
有个重要的点就是最后几行信息中,其中有两条kubeadm join 192.168.50.100:8443 开头的信息。 这分别是其他master节点和node节点加入kubernetes集群的认证命令。这个密钥是系统根据 sha256算法计算出来的,必须持有这样的密钥才可以加入当前的kubernetes集群。
这两条加入集群的命令是有一些区别的:
比如这个第一条,我们看到最后有一行内容--control-plane --certificate-key xxxx,这是控制节点加入集群的命令,控制节点是kubernetes官方的说法,其实在我们这里指的就是其他的master节点。
kubeadm join 192.168.50.100:8443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:4c738bc8e2684c5d52d80687d48925613b66ab660403649145eb668d71d85648 --control-plane --certificate-key 4931f39d3f53351cb6966a9dcc53cb5cbd2364c6d5b83e50e258c81fbec69539而最后一条就表示node节点加入集群的命令,比如:
kubeadm join 192.168.50.100:8443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:4c738bc8e2684c5d52d80687d48925613b66ab660403649145eb668d71d85648所以这两个节点使用时要看清楚是什么类型的节点加入集群的。
如果此时查看当前集群的节点,会发现只有master1节点自己。
[root@master1 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
master1 NotReady master 9m58s v1.18.4接下来我们把其他两个master节点加入到kubernetes集群中
master节点加入kubernetes集群中master2节点加入集群既然是其他的master节点加入集群,那肯定是使用如下命令:
[root@master2 ~]# kubeadm join 192.168.50.100:8443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:4c738bc8e2684c5d52d80687d48925613b66ab660403649145eb668d71d85648 --control-plane --certificate-key 4931f39d3f53351cb6966a9dcc53cb5cbd2364c6d5b83e50e258c81fbec69539
[preflight] Running pre-flight checks
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The
...... #省略若干
[mark-control-plane] Marking the node master2 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
This node has joined the cluster and a new control plane instance was created:
To start administering your cluster from this node, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Run ‘kubectl get nodes‘ to see this node join the cluster.看上去没有报错,说明加入集群成功,现在再执行一些收尾工作
[root@master2 ~]# mkdir -p $HOME/.kube
[root@master2 ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@master2 ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config加环境变量
[root@master2 ~]# cat >> ~/.bashrc <<EOF
export KUBECONFIG=/etc/kubernetes/admin.conf
EOF
[root@master2 ~]# source ~/.bashrcmaster3节点加入集群[root@master3 ~]# kubeadm join 192.168.50.100:8443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:4c738bc8e2684c5d52d80687d48925613b66ab660403649145eb668d71d85648 --control-plane --certificate-key 4931f39d3f53351cb6966a9dcc53cb5cbd2364c6d5b83e50e258c81fbec69539做一些收尾工作
[root@master3 ~]# mkdir -p $HOME/.kube
[root@master3 ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@master3 ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config
[root@master3 ~]# cat >> ~/.bashrc <<EOF
export KUBECONFIG=/etc/kubernetes/admin.conf
EOF
[root@master3 ~]# source ~/.bashrc到此,所有的master节点都已经加入集群
master节点[root@master1 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
master1 NotReady master 25m v1.18.4
master2 NotReady master 12m v1.18.4
master3 NotReady master 3m30s v1.18.4你可以在任意一个master节点上执行kubectl get node查看集群节点的命令。
node节点加入kubernetes集群中正如我们上面所说的,master1节点初始化完成后,第二条kubeadm join xxx(或者说是最后一行内容)内容便是node节点加入集群的命令。
~]# kubeadm join 192.168.50.100:8443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:4c738bc8e2684c5d52d80687d48925613b66ab660403649145eb668d71d85648注意:node节点加入集群只需要执行上面的一条命令即可,只要没有报错就表示成功。不必像master一样做最后的加入环境变量等收尾工作。
node1节点加入集群[root@node1 ~]# kubeadm join 192.168.50.100:8443 --token abcdef.0123456789abcdef > --discovery-token-ca-cert-hash sha256:4c738bc8e2684c5d52d80687d48925613b66ab660403649145eb668d71d85648
[preflight] Running pre-flight checks
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/
[preflight] Reading configuration from the cluster...
....
....
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run ‘kubectl get nodes‘ on the control-plane to see this node join the cluster.当看到倒数第四行内容This node has joined the cluster,这一行信息表示node1节点加入集群成功。
node2节点加入集群[root@node2 ~]# kubeadm join 192.168.50.100:8443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:4c738bc8e2684c5d52d80687d48925613b66ab660403649145eb668d71d85648此时我们可以在任意一个master节点执行如下命令查看此集群的节点信息。
[root@master1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1 NotReady master 20h v1.18.4
master2 NotReady master 20h v1.18.4
master3 NotReady master 20h v1.18.4
node1 NotReady <none> 5m15s v1.18.4
node2 NotReady <none> 5m11s v1.18.4可以看到集群的五个节点都已经存在,但是现在还不能用,也就是说现在集群节点是不可用的,原因在于上面的第2个字段,我们看到五个节点都是`NotReady状态,这是因为我们还没有安装网络插件。
网络插件有calico,flannel等插件,这里我们选择使用flannel插件。
默认大家从网上看的教程都会使用这个命令来初始化。
~]# kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml事实上很多用户都不能成功,因为国内网络受限,所以可以这样子来做。
flannel镜像源master1节点上修改本地的hosts文件添加如下内容以便解析
199.232.28.133 raw.githubusercontent.com然后下载flannel文件
[root@master1 ~]# curl -o kube-flannel.yml https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml编辑镜像源,默认的镜像地址我们修改一下。把yaml文件中所有的quay.io修改为 quay-mirror.qiniu.com
[root@master1 ~]# sed -i ‘s/quay.io/quay-mirror.qiniu.com/g‘ kube-flannel.yml此时保存保存退出。在master节点执行此命令。
[root@master1 ~]# kubectl apply -f kube-flannel.yml
podsecuritypolicy.policy/psp.flannel.unprivileged created
clusterrole.rbac.authorization.k8s.io/flannel created
clusterrolebinding.rbac.authorization.k8s.io/flannel created
serviceaccount/flannel created
configmap/kube-flannel-cfg created
daemonset.apps/kube-flannel-ds-amd64 created
daemonset.apps/kube-flannel-ds-arm64 created
daemonset.apps/kube-flannel-ds-arm created
daemonset.apps/kube-flannel-ds-ppc64le created
daemonset.apps/kube-flannel-ds-s390x created这样子就可以成功拉取flannel镜像了。当然你也可以使用我提供给大家的kube-flannel.yml文件
flannel是否正常如果你想查看flannel这些pod运行是否正常,使用如下命令
[root@master1 ~]# kubectl get pods -n kube-system | grep flannel
NAME READY STATUS RESTARTS AGE
kube-flannel-ds-amd64-dp972 1/1 Running 0 66s
kube-flannel-ds-amd64-lkspx 1/1 Running 0 66s
kube-flannel-ds-amd64-rmsdk 1/1 Running 0 66s
kube-flannel-ds-amd64-wp668 1/1 Running 0 66s
kube-flannel-ds-amd64-zkrwh 1/1 Running 0 66s如果第三字段STATUS不是处于Running状态的话,说明flannel是异常的,需要排查问题所在。
Ready稍等片刻,执行如下指令查看节点是否可用
[root@master1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1 Ready master 21h v1.18.4
master2 Ready master 21h v1.18.4
master3 Ready master 21h v1.18.4
node1 Ready <none> 62m v1.18.4
node2 Ready <none> 62m v1.18.4目前节点状态是Ready,表示集群节点现在是可用的。
kubernetes集群kubernetes集群测试nginx的pod现在我们在kubernetes集群中创建一个nginx的pod,验证是否能正常运行。
在master节点执行一下步骤:
[root@master1 ~]# kubectl create deployment nginx --image=nginx
deployment.apps/nginx created
[root@master1 ~]# kubectl expose deployment nginx --port=80 --type=NodePort
service/nginx exposed现在我们查看pod和service
[root@master1 ~]# kubectl get pod,svc -o wide
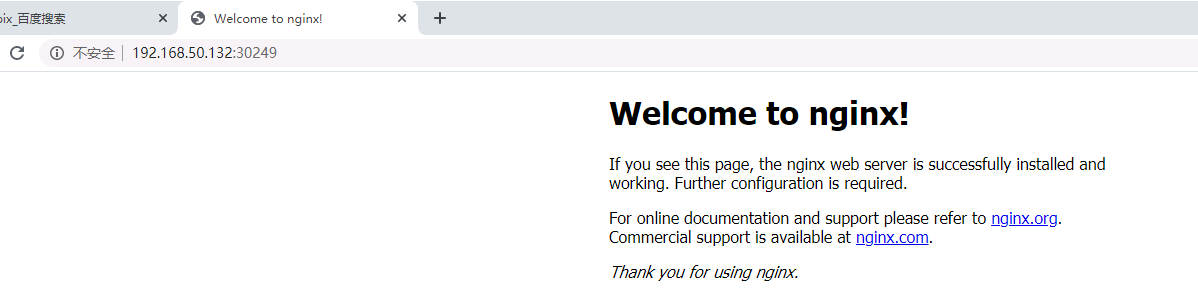
打印的结果中,前半部分是pod相关信息,后半部分是service相关信息。我们看service/nginx这一行可以看出service暴漏给集群的端口是30249。记住这个端口。
然后从pod的详细信息可以看出此时pod在node2节点之上。node2节点的IP地址是192.168.50.132
nginx验证集群那现在我们访问一下。打开浏览器(建议火狐浏览器),访问地址就是:http://192.168.50.132:30249
dashboarddashboard先把dashboard的配置文件下载下来。由于我们之前已经添加了hosts解析,因此可以下载。
[root@master1 ~]# wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0-beta8/aio/deploy/recommended.yaml默认Dashboard只能集群内部访问,修改Service为NodePort类型,暴露到外部:
大概在此文件的32-44行之间,修改为如下:
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kube-system
spec:
type: NodePort #加上此行
ports:
- port: 443
targetPort: 8443
nodePort: 30001 #加上此行,端口30001可以自行定义
selector:
k8s-app: kubernetes-dashboardyaml文件[root@master1 ~]# kubectl apply -f recommended.yaml
namespace/kubernetes-dashboard created
serviceaccount/kubernetes-dashboard created
service/kubernetes-dashboard created
secret/kubernetes-dashboard-certs created
...
service/dashboard-metrics-scraper created
deployment.apps/dashboard-metrics-scraper createddashboard运行是否正常[root@master1 ~]# kubectl get pods -n kubernetes-dashboard
NAME READY STATUS RESTARTS AGE
dashboard-metrics-scraper-694557449d-mlnl4 1/1 Running 0 2m31s
kubernetes-dashboard-9774cc786-ccvcf 1/1 Running 0 2m31s主要是看status这一列的值,如果是Running,并且RESTARTS字段的值为0(只要这个值不是一直在渐渐变大),就是正常的,目前来看是没有问题的。我们可以继续下一步。
查看此dashboard的pod运行所在的节点

从上面可以看出,kubernetes-dashboard-9774cc786-ccvcf运行所在的节点是node2上面,并且暴漏出来的端口是30001,所以访问地址是:https://192.168.50.132:30001
用火狐浏览器访问,访问的时候会让输入token,从此处可以查看到token的值。
[root@master1 ~]# kubectl describe secrets -n kube-system $(kubectl -n kube-system get secret | awk ‘/dashboard-admin/{print $1}‘)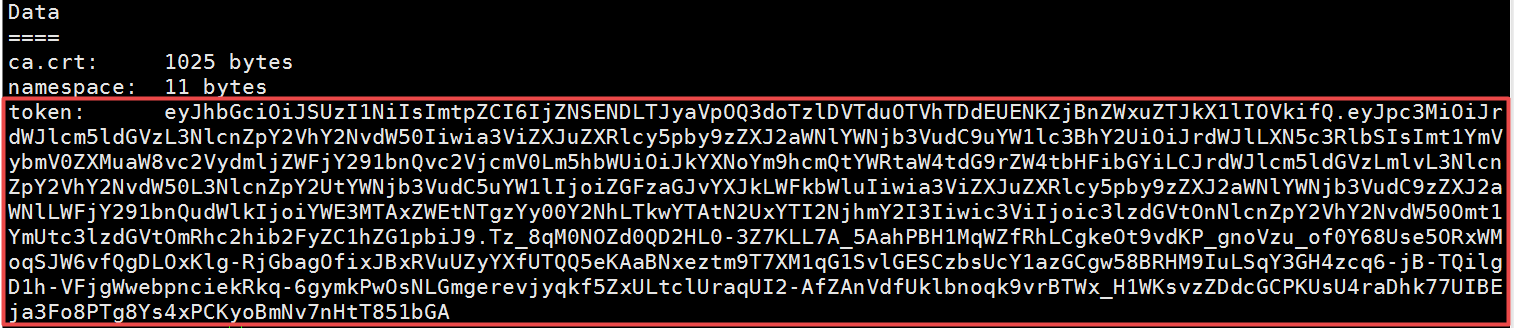
把上面的token值输入进去即可进去dashboard界面。
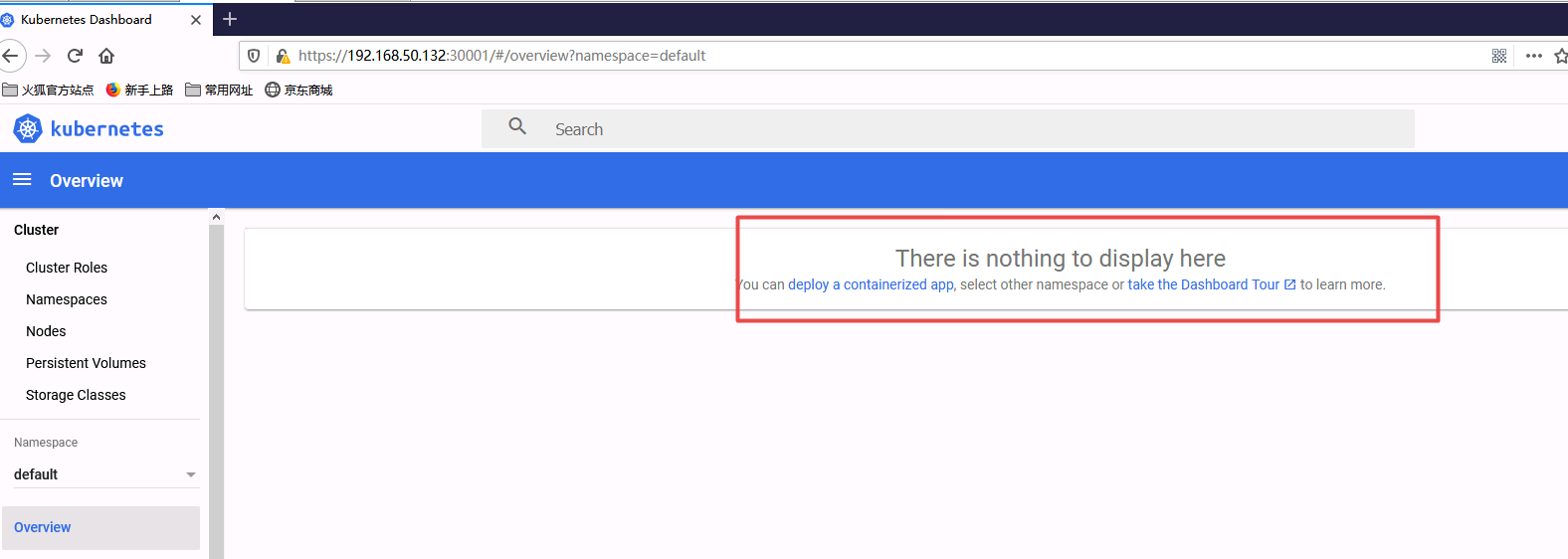
不过现在我们虽然可以登陆上去,但是我们权限不够还查看不了集群信息,因为我们还没有绑定集群角色,同学们可以先按照上面的尝试一下,再来做下面的步骤
[root@master1 ~]# kubectl create serviceaccount dashboard-admin -n kube-system
[root@master1 ~]# kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin
[root@master1 ~]# kubectl describe secrets -n kube-system $(kubectl -n kube-system get secret | awk ‘/dashboard-admin/{print $1}‘)再使用输出的token登陆dashboard即可。
(1)其他master节点无法加入集群
[check-etcd] Checking that the etcd cluster is healthy
error execution phase check-etcd: error syncing endpoints with etc: context deadline exceeded
To see the stack trace of this error execute with --v=5 or higher查看集群的高可用配置是否有问题,比如keepalived的配置中,主备,优先级是否都配置好了。
标签:受限 功能 pen cache domain grep was 很多 根据
原文地址:https://blog.51cto.com/mageedu/2552985