标签:写文件 详细 自定义 codec stomp puts src 虚拟机 虚拟

01 我们一起学大数据
今天老刘分享的是MapReduce知识点的第二部分,在第一部分中基本把MapReduce的工作流程讲述清楚了,现在就是对MapReduce零零散散的知识点进行总结,这次的内容大纲如下图:
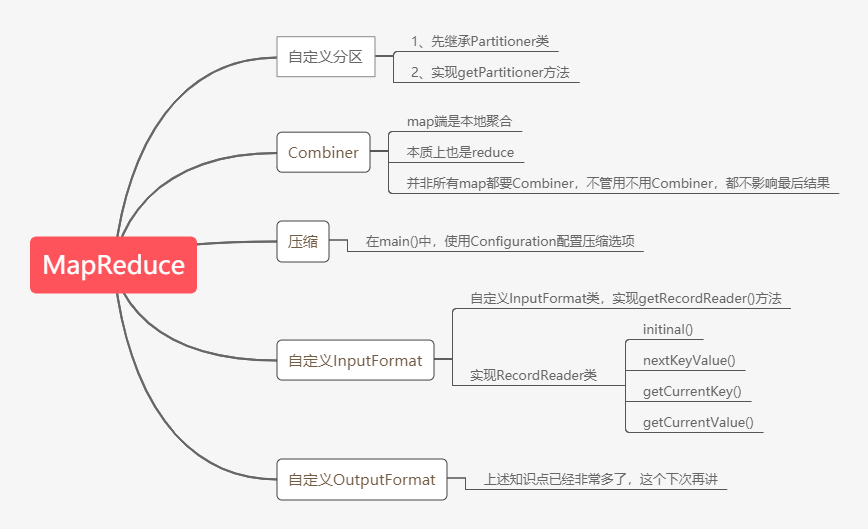
02 需要谨记的知识点
第6点:自定义分区
在上篇文章里的第五点提到过这句话:分区用到了分区器,默认分区器是HashPartitioner,并且给出了相关代码,现在对分区详细介绍介绍。
分区原理
MapReduce有自带的默认分区器HashPartitioner,关键方法是利用getPartition()返回当前键值对的分区索引。
详细流程就是① 在环形缓冲区溢出写磁盘前,会将每个键值对kv,作为getPartition()的参数输入;
② 然后就会对键值对中的key求hash值,与MAX_VALUE按位与,再模上reduce task的个数,这里老刘假设reduce task的个数为4,那么map任务溢出的文件就会有4个分区,分区的index分别为0,1,2,3,那getPartition()的输出结果就是0,1,2,3。
③ 根据计算结果,就会决定出当前键值对KV,落入哪个分区,如果是0,就会落入到溢出文件的0分区里面。
④ 最后就会被相应的reduce通过http获得。
那讲完这个,就要说说自定义分区,为什么会有自定义分区?
因为MR用的是默认HashPartition分区,但是当前业务逻辑,不适用于HashPartition分区,就需要自己设计自定义分区。
这里就举个例子,自定义分区,使得文件中,分别以Dear、Bear、River、Car为键的键值对,分别落到index是0、1、2、3的分区中。
咱们先来分析分析它的逻辑,由于是自定义分区嘛!就需要自定义分区类,然后用这个类实现Partitioner接口,以及在getPartition()中实现分区逻辑,最后就是在main()中设置reduce个数为4,大致就是这样。
下面分享出关键代码:
public class CustomPartitioner extends Partitioner<Text, IntWritable> { public static HashMap<String, Integer> dict = new HashMap<String, Integer>(); //定义每个键对应的分区index,使用map数据结构完成 static{ dict.put("Dear", 0); dict.put("Bear", 1); dict.put("River", 2); dict.put("Car", 3); } public int getPartition(Text text, IntWritable intWritable, int i) { //Dear、Bear、River、Car分别落入到index是0,1,2,3的分区中 int partitionIndex = dict.get(text.toString()); return partitionIndex; } }
那么自定义分区就说完了,大家可以总结总结,自定义分区的步骤。
第7点:自定义Combiner
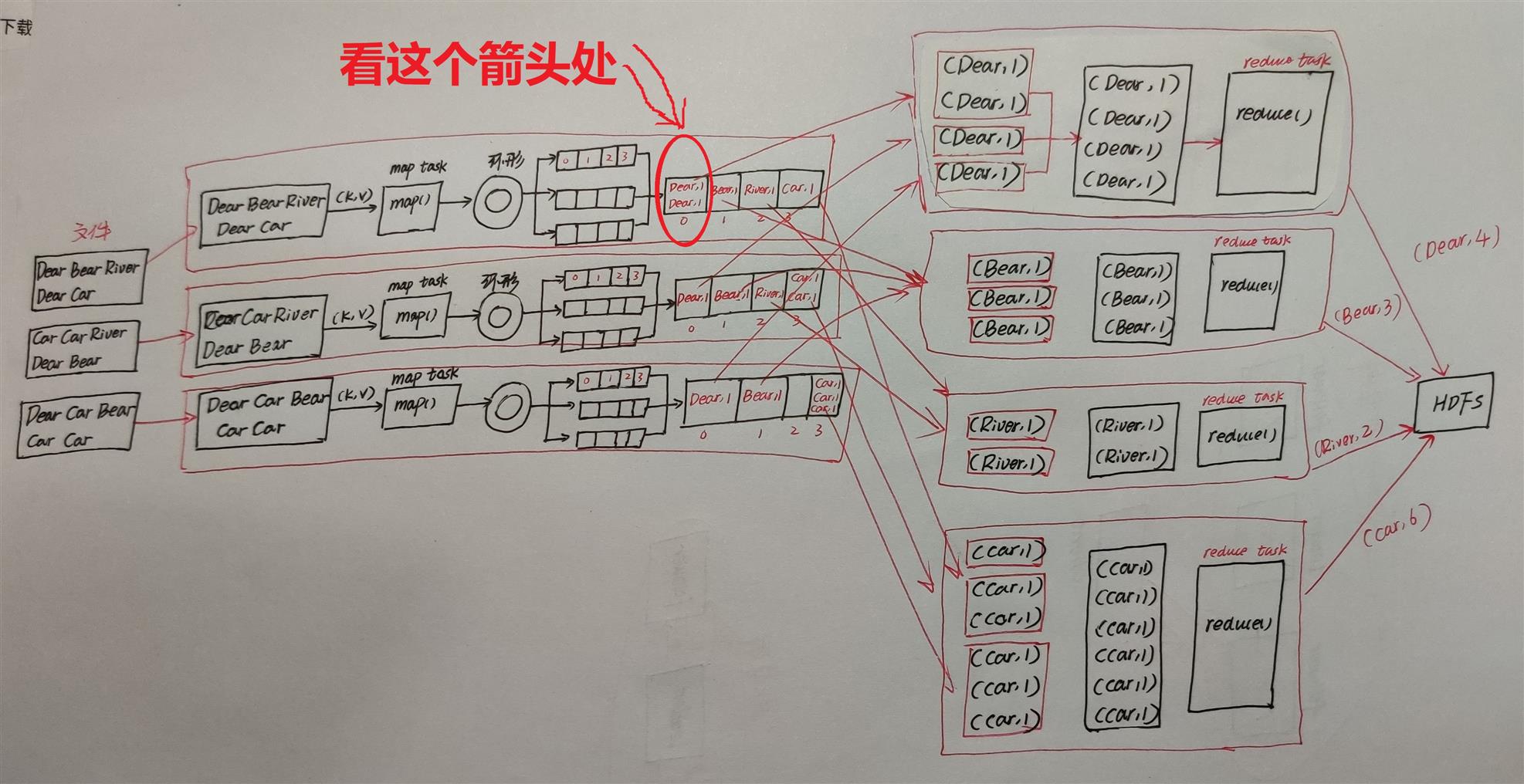
仔细看这张图的红色标记处,combine操作就发生在这个地方,它会把两个(Dear,1)变为1个(Dear,2)。
为什么要进行combine操作?
我们假设map中(Dear, 1)有1亿个,按原思路,map端需要存储1亿个(Dear, 1),然后将1亿个(Dear, 1)通过网络被reduce获得,然后再在reduce端进行汇总,这样做map端本地磁盘IO、数据从map端到reduce端传输的网络IO比较大,网络开销太大了。
所以我们就会需要想办法,能不能在reduce1从map1拉取1亿个(Dear, 1)之前,在map端就提前先做下reduce汇总,得到结果(Dear, 100000000),然后再将这个结果(一个键值对)传输到reduce1呢?那当然是可以的,这个操作就是combine操作。
combine操作具体流程如下:
当每个map任务的环形缓冲区添满80%,开始溢写磁盘文件。
在这个过程中会进行分区,每个分区内按键排序,如果设置了combine的话,就会继续进行combine操作,如果设置map输出压缩的话,就会进行压缩。
在合并溢写文件时,如果至少有3个溢写文件,并且设置了map端combine的话,会在合并的过程中触发combine操作;
但是若只有2个或1个溢写文件,则不触发combine操作(因为combine操作,本质上是一个reduce,需要启动JVM虚拟机,有一定的开销)
combine本质上也是reduce;因为自定义的combine类继承自Reducer父类
MR代码如下:
//在main()中进行设置 job.setCombinerClass(WordCountReduce.class)
MR的combine操作就讲得差不多了,大家还可以总结总结!
第8点:MR压缩
为什么会有MR压缩?
在MR中,为了减少磁盘IO及网络IO,可考虑在map端、reduce端设置压缩功能。
那么如何设置压缩功能呢?只需在main方法中,给Configuration对象增加如下设置即可:
//开启map输出进行压缩的功能 configuration.set("mapreduce.map.output.compress", "true"); //设置map输出的压缩算法是:BZip2Codec,它是hadoop默认支持的压缩算法,且支持切分 configuration.set("mapreduce.map.output.compress.codec", "org.apache.hadoop.io.compress.BZip2Codec"); //开启job输出压缩功能 configuration.set("mapreduce.output.fileoutputformat.compress", "true"); //指定job输出使用的压缩算法 configuration.set("mapreduce.output.fileoutputformat.compress.codec", "org.apache.hadoop.io.compress.BZip2Codec");
那MR压缩就差不多就讲完了,大家可以继续总结总结。
第9点:自定义InputFormat
老刘主要讲讲InputFormat的流程,老刘之前在MapReduce的第一篇文章中讲过,假设MR的输入文件有三个block:block1,block2,block3,每一个block对应一个split分片,每一个split对应一个map任务(map task)。
但是呢,没有讲如何把文件进行切分之类的问题,就直接给出来了,下面就是讲讲这些内容。
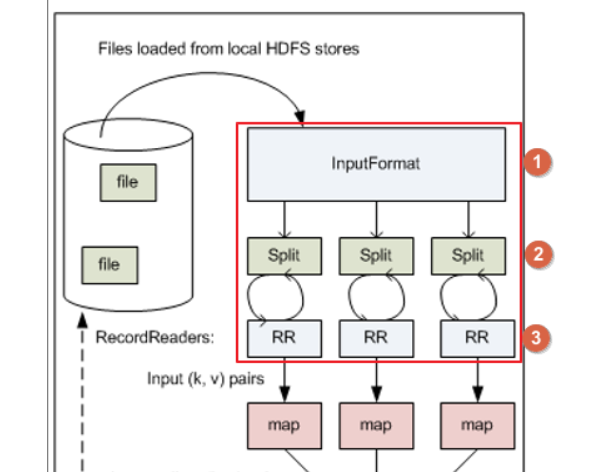
先说一点,MapReduce任务的输入文件一般是存储在HDFS里面,我们主要看map任务是如何从hdfs读取分片数据的部分。
这里会涉及三个关键的类:
① InputFormat输入格式类
② InputSplit输入分片类:getSplit(),InputFormat输入格式类将输入文件分成一个个分片InputSplit;每个Map任务对应一个split分片。
③ RecordReader记录读取器类:createRecordReader(),RecordReader(记录读取器)读取分片数据,一行记录生成一个键值对;传入map任务的map()方法,调用map()。
再说说为什么需要自定义InputFormat?
无论hdfs还是mapreduce,处理小文件都有损效率,实践中,又难免面临处理大量小文件的场景,那这个时候就需要采取一些解决办法。
小文件的优化无非以下几种方式:
① 在数据采集的时候,就将小文件或小批数据合成大文件再上传HDFS(SequenceFile方案)。
② 在业务处理之前,在HDFS上使用mapreduce程序对小文件进行合并;可使用自定义InputFormat实现。
③ 在mapreduce处理时,可采用CombineFileInputFormat提高效率。
我们可以采取第二步,自定义输入格式。老刘这次只能讲讲大概了,等老刘阅读源码水平变高,再来给大家好好讲讲。
03 知识点总结
好啦,今天的MapReduce内容就总结得差不多了,内容还是蛮多的,难点就是这个自定义InputFormat,老刘也只是讲了讲大概,等以后有空了,老刘看源码水平变高了,再看给大家好好讲讲。
最后,有事,就联系公众号:努力的老刘;没事,就和老刘一起好好写大数据。
标签:写文件 详细 自定义 codec stomp puts src 虚拟机 虚拟
原文地址:https://www.cnblogs.com/bigdatalaoliu/p/14016893.html