标签:object 观察 五个 微信 master 次数 odi 函数 numpy

机器学习算法与自然语言处理出品
@公众号原创专栏作者 刘聪NLP
学校 | 中国药科大学 药学信息学硕士
知乎专栏 | 自然语言处理相关论文
前几天写了一篇短文本相似度算法研究的文章,不过里面介绍的方法基本上都是基于词向量生成句子向量的方法。今天在这里就介绍一下传统算法TF-IDF是如何计算短文本相似度的。
TF-IDF是英文Term Frequency–Inverse Document Frequency的缩写,中文叫做词频-逆文档频率。
在一个文本中,当一个词汇出现很多次时,我们往往认为这个词是重要的,可以代表该文本。但是事实不是这样的,比如:“的”这个词,虽然在一个文本中出现很多次,但是它依然没有什么实际意义。而人们想要给文本中每个词在语义表达中,赋予一定的权重,就出现了TF-IDF算法。
它由TF(词频)和IDF(逆文档频率)组成,其中,TF(词频)计算如下:
理论上,词汇出现的次数就应该是词汇的频率。我们这里除以文本词汇总个数,是为了排除文本长度的影响,获取到该词在文本中的相对重要程度。
IDF(逆文档频率)计算如下:

上面我们说过,有一些虽然在一个文本中出现很多次,但是它依然没有什么实际意义,比如:“的”。而IDF逆文档频率是衡量该词汇是否可以充分表示该文本的参数。IDF值越大,说明包含该词汇的文本越少,则该词汇越能够代表该文本。
TF-IDF则是由TF和IDF相乘得到,如下:
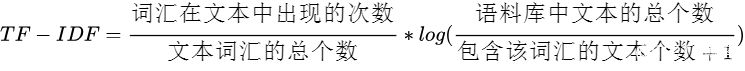
它的含义是,如果一个词,在该文本中出现次数越多,而在其他文本中出现很少时,则该词汇越能够表示该文本的信息。
实践是检验真理的唯一标准。讲完理论之后,我来看看具体任务上,我们要如何去使用TF-IDF。上一篇短文本相似度算法研究 文章中,我们举过这样一个场景,在问答系统任务(问答机器人)中,我们往往会人为地配置一些常用并且描述清晰的问题及其对应的回答,我们将这些配置好的问题称之为“标准问”。当用户进行提问时,常常将用户的问题与所有配置好的标准问进行相似度计算,找出与用户问题最相似的标准问,并返回其答案给用户,这样就完成了一次问答操作。
根据上述例子,我们进行coding,TF-IDF类定义具体如下:
import numpy as np
class TF_IDF_Model(object):
def __init__(self, documents_list):
self.documents_list = documents_list
self.documents_number = len(documents_list)
self.tf = []
self.idf = {}
self.init()
def init(self):
df = {}
for document in self.documents_list:
temp = {}
for word in document:
temp[word] = temp.get(word, 0) + 1/len(document)
self.tf.append(temp)
for key in temp.keys():
df[key] = df.get(key, 0) + 1
for key, value in df.items():
self.idf[key] = np.log(self.documents_number / (value + 1))
def get_score(self, index, query):
score = 0.0
for q in query:
if q not in self.tf[index]:
continue
score += self.tf[index][q] * self.idf[q]
return score
def get_documents_score(self, query):
score_list = []
for i in range(self.documents_number):
score_list.append(self.get_score(i, query))
return score_list其中,documents_list 表示需要输入的文本列表,内部每个文本需要事先分好词;documents_number表示文本总个数;tf 用于存储每个文本中每个词的词频;idf用于存储每个词汇的逆文档频率;init函数是类初始化函数,用于求解文本集合中的tf和idf变量;get_score函数是获取一个文本与文本列表中一个文本的tf-idf相似度值;get_documents_score函数是获取一个文本与文本列表中所有文本的tf-idf相似度值。
定义好的TF-IDF类如何去使用呢?具体如下:
首先,给出文本集合,也就是我们上文场景中提到的“标准问”库;
document_list = ["行政机关强行解除行政协议造成损失,如何索取赔偿?",
"借钱给朋友到期不还得什么时候可以起诉?怎么起诉?",
"我在微信上被骗了,请问被骗多少钱才可以立案?",
"公民对于选举委员会对选民的资格申诉的处理决定不服,能不能去法院起诉吗?",
"有人走私两万元,怎么处置他?",
"法律上餐具、饮具集中消毒服务单位的责任是不是对消毒餐具、饮具进行检验?"]然后,我们对其进行分词操作;
import jieba
document_list = [list(jieba.cut(doc)) for doc in document_list]得到结果如下:
[[‘行政‘, ‘机关‘, ‘强行‘, ‘解除‘, ‘行政‘, ‘协议‘, ‘造成‘, ‘损失‘, ‘,‘, ‘如何‘, ‘索取‘, ‘赔偿‘, ‘?‘],
[‘借钱‘, ‘给‘, ‘朋友‘, ‘到期‘, ‘不‘, ‘还‘, ‘得‘, ‘什么‘, ‘时候‘, ‘可以‘, ‘起诉‘, ‘?‘, ‘怎么‘, ‘起诉‘, ‘?‘],
[‘我‘, ‘在‘, ‘微信‘, ‘上‘, ‘被‘, ‘骗‘, ‘了‘, ‘,‘, ‘请问‘, ‘被‘, ‘骗‘, ‘多少‘, ‘钱‘, ‘才‘, ‘可以‘, ‘立案‘, ‘?‘],
[‘公民‘, ‘对于‘, ‘选举‘, ‘委员会‘, ‘对‘, ‘选民‘, ‘的‘, ‘资格‘, ‘申诉‘, ‘的‘, ‘处理‘, ‘决定‘, ‘不服‘, ‘,‘, ‘能‘, ‘不能‘, ‘去‘, ‘法院‘, ‘起诉‘, ‘吗‘, ‘?‘],
[‘有人‘, ‘走私‘, ‘两万元‘, ‘,‘, ‘怎么‘, ‘处置‘, ‘他‘, ‘?‘],
[‘法律‘, ‘上‘, ‘餐具‘, ‘、‘, ‘饮具‘, ‘集中‘, ‘消毒‘, ‘服务‘, ‘单位‘, ‘的‘, ‘责任‘, ‘是不是‘, ‘对‘, ‘消毒‘, ‘餐具‘, ‘、‘, ‘饮具‘, ‘进行‘, ‘检验‘, ‘?‘]]接下来,我们实例化TF-IDF类,生成一个对象;
tf_idf_model = TF_IDF_Model(document_list)通过参数调用,观察示例化的对象中documents_list ,documents_number,tf 和idf变量具体存储了什么;
print(tf_idf_model.documents_list)
print(tf_idf_model.documents_number)
print(tf_idf_model.tf)
print(tf_idf_model.idf)结果如下:
documents_list:
[[‘行政‘, ‘机关‘, ‘强行‘, ‘解除‘, ‘行政‘, ‘协议‘, ‘造成‘, ‘损失‘, ‘,‘, ‘如何‘, ‘索取‘, ‘赔偿‘, ‘?‘], [‘借钱‘, ‘给‘, ‘朋友‘, ‘到期‘, ‘不‘, ‘还‘, ‘得‘, ‘什么‘, ‘时候‘, ‘可以‘, ‘起诉‘, ‘?‘, ‘怎么‘, ‘起诉‘, ‘?‘], [‘我‘, ‘在‘, ‘微信‘, ‘上‘, ‘被‘, ‘骗‘, ‘了‘, ‘,‘, ‘请问‘, ‘被‘, ‘骗‘, ‘多少‘, ‘钱‘, ‘才‘, ‘可以‘, ‘立案‘, ‘?‘], [‘公民‘, ‘对于‘, ‘选举‘, ‘委员会‘, ‘对‘, ‘选民‘, ‘的‘, ‘资格‘, ‘申诉‘, ‘的‘, ‘处理‘, ‘决定‘, ‘不服‘, ‘,‘, ‘能‘, ‘不能‘, ‘去‘, ‘法院‘, ‘起诉‘, ‘吗‘, ‘?‘], [‘有人‘, ‘走私‘, ‘两万元‘, ‘,‘, ‘怎么‘, ‘处置‘, ‘他‘, ‘?‘], [‘法律‘, ‘上‘, ‘餐具‘, ‘、‘, ‘饮具‘, ‘集中‘, ‘消毒‘, ‘服务‘, ‘单位‘, ‘的‘, ‘责任‘, ‘是不是‘, ‘对‘, ‘消毒‘, ‘餐具‘, ‘、‘, ‘饮具‘, ‘进行‘, ‘检验‘, ‘?‘]]
documents_number:
6
tf:
[{‘行政‘: 0.15384615384615385, ‘机关‘: 0.07692307692307693, ‘强行‘: 0.07692307692307693, ‘解除‘: 0.07692307692307693, ‘协议‘: 0.07692307692307693, ‘造成‘: 0.07692307692307693, ‘损失‘: 0.07692307692307693, ‘,‘: 0.07692307692307693, ‘如何‘: 0.07692307692307693, ‘索取‘: 0.07692307692307693, ‘赔偿‘: 0.07692307692307693, ‘?‘: 0.07692307692307693},
{‘借钱‘: 0.06666666666666667, ‘给‘: 0.06666666666666667, ‘朋友‘: 0.06666666666666667, ‘到期‘: 0.06666666666666667, ‘不‘: 0.06666666666666667, ‘还‘: 0.06666666666666667, ‘得‘: 0.06666666666666667, ‘什么‘: 0.06666666666666667, ‘时候‘: 0.06666666666666667, ‘可以‘: 0.06666666666666667, ‘起诉‘: 0.13333333333333333, ‘?‘: 0.13333333333333333, ‘怎么‘: 0.06666666666666667},
{‘我‘: 0.058823529411764705, ‘在‘: 0.058823529411764705, ‘微信‘: 0.058823529411764705, ‘上‘: 0.058823529411764705, ‘被‘: 0.11764705882352941, ‘骗‘: 0.11764705882352941, ‘了‘: 0.058823529411764705, ‘,‘: 0.058823529411764705, ‘请问‘: 0.058823529411764705, ‘多少‘: 0.058823529411764705, ‘钱‘: 0.058823529411764705, ‘才‘: 0.058823529411764705, ‘可以‘: 0.058823529411764705, ‘立案‘: 0.058823529411764705, ‘?‘: 0.058823529411764705},
{‘公民‘: 0.047619047619047616, ‘对于‘: 0.047619047619047616, ‘选举‘: 0.047619047619047616, ‘委员会‘: 0.047619047619047616, ‘对‘: 0.047619047619047616, ‘选民‘: 0.047619047619047616, ‘的‘: 0.09523809523809523, ‘资格‘: 0.047619047619047616, ‘申诉‘: 0.047619047619047616, ‘处理‘: 0.047619047619047616, ‘决定‘: 0.047619047619047616, ‘不服‘: 0.047619047619047616, ‘,‘: 0.047619047619047616, ‘能‘: 0.047619047619047616, ‘不能‘: 0.047619047619047616, ‘去‘: 0.047619047619047616, ‘法院‘: 0.047619047619047616, ‘起诉‘: 0.047619047619047616, ‘吗‘: 0.047619047619047616, ‘?‘: 0.047619047619047616},
{‘有人‘: 0.125, ‘走私‘: 0.125, ‘两万元‘: 0.125, ‘,‘: 0.125, ‘怎么‘: 0.125, ‘处置‘: 0.125, ‘他‘: 0.125, ‘?‘: 0.125},
{‘法律‘: 0.05, ‘上‘: 0.05, ‘餐具‘: 0.1, ‘、‘: 0.1, ‘饮具‘: 0.1, ‘集中‘: 0.05, ‘消毒‘: 0.1, ‘服务‘: 0.05, ‘单位‘: 0.05, ‘的‘: 0.05, ‘责任‘: 0.05, ‘是不是‘: 0.05, ‘对‘: 0.05, ‘进行‘: 0.05, ‘检验‘: 0.05, ‘?‘: 0.05}]
idf:
{‘行政‘: 1.0986122886681098, ‘机关‘: 1.0986122886681098, ‘强行‘: 1.0986122886681098, ‘解除‘: 1.0986122886681098, ‘协议‘: 1.0986122886681098, ‘造成‘: 1.0986122886681098, ‘损失‘: 1.0986122886681098, ‘,‘: 0.1823215567939546, ‘如何‘: 1.0986122886681098, ‘索取‘: 1.0986122886681098, ‘赔偿‘: 1.0986122886681098, ‘?‘: -0.15415067982725836, ‘借钱‘: 1.0986122886681098, ‘给‘: 1.0986122886681098, ‘朋友‘: 1.0986122886681098, ‘到期‘: 1.0986122886681098, ‘不‘: 1.0986122886681098, ‘还‘: 1.0986122886681098, ‘得‘: 1.0986122886681098, ‘什么‘: 1.0986122886681098, ‘时候‘: 1.0986122886681098, ‘可以‘: 0.6931471805599453, ‘起诉‘: 0.6931471805599453, ‘怎么‘: 0.6931471805599453, ‘我‘: 1.0986122886681098, ‘在‘: 1.0986122886681098, ‘微信‘: 1.0986122886681098, ‘上‘: 0.6931471805599453, ‘被‘: 1.0986122886681098, ‘骗‘: 1.0986122886681098, ‘了‘: 1.0986122886681098, ‘请问‘: 1.0986122886681098, ‘多少‘: 1.0986122886681098, ‘钱‘: 1.0986122886681098, ‘才‘: 1.0986122886681098, ‘立案‘: 1.0986122886681098, ‘公民‘: 1.0986122886681098, ‘对于‘: 1.0986122886681098, ‘选举‘: 1.0986122886681098, ‘委员会‘: 1.0986122886681098, ‘对‘: 0.6931471805599453, ‘选民‘: 1.0986122886681098, ‘的‘: 0.6931471805599453, ‘资格‘: 1.0986122886681098, ‘申诉‘: 1.0986122886681098, ‘处理‘: 1.0986122886681098, ‘决定‘: 1.0986122886681098, ‘不服‘: 1.0986122886681098, ‘能‘: 1.0986122886681098, ‘不能‘: 1.0986122886681098, ‘去‘: 1.0986122886681098, ‘法院‘: 1.0986122886681098, ‘吗‘: 1.0986122886681098, ‘有人‘: 1.0986122886681098, ‘走私‘: 1.0986122886681098, ‘两万元‘: 1.0986122886681098, ‘处置‘: 1.0986122886681098, ‘他‘: 1.0986122886681098, ‘法律‘: 1.0986122886681098, ‘餐具‘: 1.0986122886681098, ‘、‘: 1.0986122886681098, ‘饮具‘: 1.0986122886681098, ‘集中‘: 1.0986122886681098, ‘消毒‘: 1.0986122886681098, ‘服务‘: 1.0986122886681098, ‘单位‘: 1.0986122886681098, ‘责任‘: 1.0986122886681098, ‘是不是‘: 1.0986122886681098, ‘进行‘: 1.0986122886681098, ‘检验‘: 1.0986122886681098}最后,我们给出一个用户问题,通过tf-idf算法,计算出“标准问”库中所有标准问的相似度值;
query = "走私了两万元,在法律上应该怎么量刑?"
query = list(jieba.cut(query))
scores = tf_idf_model.get_documents_score(query)结果如下:
[0.002167, 0.025656, 0.171679, 0.001341, 0.364818, 0.081880]通过结果我们可以发现,第五个标准问“有人走私两万元,怎么处置他?”与用户问题“走私了两万元,在法律上应该怎么量刑?”最为相似,符合我们的预期。
TF-IDF算法,计算较快,理解起来也比较简单;但是存在着缺点,相较于使用词向量生成句子向量的方法,由于它只考虑词频的因素,没有体现出词汇在文中上下文的地位,因此不能够很好的突出语义信息,会造成相似度结果不理想的情况。
以上,就是本人对TF-IDF算法的总结,有错误地方还希望指出,欢迎大家交流。
代码可见:https://link.zhihu.com/?target=https%3A//github.com/liucongg/ZhiHu_Code/blob/master/tf_idf_code/
重磅!忆臻自然语言处理-学术微信交流群已成立
可以扫描下方二维码,小助手将会邀请您入群交流,
注意:请大家添加时修改备注为 [学校/公司 + 姓名 + 方向]
例如 —— 哈工大+张三+对话系统。
号主,微商请自觉绕道。谢谢!
全连接的图卷积网络(GCN)和self-attention这些机制的区别与联系
图卷积网络(GCN)新手村完全指南
论文赏析[ACL18]基于Self-Attentive的成分句法分析

标签:object 观察 五个 微信 master 次数 odi 函数 numpy
原文地址:https://blog.51cto.com/15009309/2553052