标签:item 目的 passing function ica mos 机器 encoder 推荐

机器学习算法与自然语言处理出品
@公众号原创专栏作者 Don.hub
单位 | 京东算法工程师
学校 | 帝国理工大学
吸睛这个词就很代表attention,我们在看一张图片的时候,很容易被更重要或者更突出的东西所吸引,所以我们把更多的注意放在局部的部分上,在计算机视觉(CV)领域,就可以看作是图片的局部拥有更多的权重,比如图片生成标题,标题中的词就会主要聚焦于局部。
NLP领域,可以想象我们在做阅读理解的时候,我们在看文章的时候,往往是带着问题去寻找答案,所以文章中的每个部分是需要不同的注意力的。例如我们在做评论情感分析的时候,一些特定的情感词,例如amazing等,我们往往需要特别注意,因为它们是很重要的情感词,往往决定了评论者的情感。如下图(Yang et al., 何老师团队 HAN

直白地说,attention就是一个权重的vector。
attention的好处主要是具有很好的解释性,并且极大的提高了模型的效果,已经是很多SOTA 模型必备的模块,特别是transformer(使用了self / global/ multi-level/ multihead/ attention)的出现极大得改变了NLP的格局。
没法捕捉位置信息,需要添加位置信息。当然不同的attention机制有不同的当然如果说transformer的坏处,其最大的坏处是空间消耗大,这是因为我们需要储存attention score(N*N)的维度,所以Sequence length(N)不能太长,这就导致,我们seq和seq之间没有关联。(具体参照XLNET以及XLNET的解决方式)
为什么会有attention?attention其实就是为了翻译任务而生的(但最后又不局限于翻译任务),我们来看看他的具体演化。
Seq2Seq model 是有encoder和decoder组成的,它主要的目的是将输入的文字翻译成目标文字。其中encoder和decoder都是RNN,(可以是RNN/LSTM/或者GRU或者是双向RNN)。模型将source的文字编码成一串固定长度的context编码,之后利用这段编码,使用decoder解码出具体的输出target。这种转化任务可以适用于:翻译,语音转化,对话生成等序列到序列的任务。
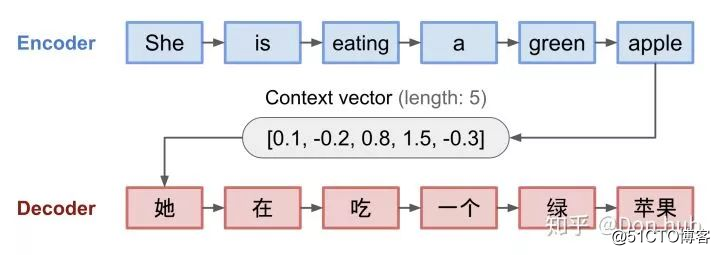
但是这种模型的缺点也很明显:- 首先所有的输入都编码成一个固定长度的context vector,这个长度多少合适呢?很难有个确切的答案,一个固定长度的vector并不能编码所有的上下文信息,导致的是我们很多的长距离依赖关系信息都消失了。- decoder在生成输出的时候,没有一个与encoder的输入的匹配机制,对于不同的输入进行不同权重的关注。- Second, it is unable to model alignment between input and output sequences, which is an essential aspect of structured output tasks such as translation or summarization [Young et al., 2018]. Intuitively, in sequence-to-sequence tasks, each output token is expected to be more in?uenced by some speci?c parts of the input sequence. However, decoder lacks any mechanism to selectively focus on relevant input tokens while generating each output token.
NMT【paper】 【code】最早提出了在encoder以及decoder之间追加attention block,最主要就是解决encoder 以及decoder之间匹配问题。
 是decoder的初始化hidden state,是随机初始化的,相比于seq2seq(他是用context vector作为decoder的hidden 初始化),
是decoder的初始化hidden state,是随机初始化的,相比于seq2seq(他是用context vector作为decoder的hidden 初始化),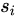 是decoder的hidden states。
是decoder的hidden states。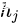 代表的是第j个encoder位置的输出hidden states
代表的是第j个encoder位置的输出hidden states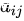 代表的是第i个decoder的位置对对j个encoder位置的权重
代表的是第i个decoder的位置对对j个encoder位置的权重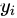 是第i个decoder的位置的输出,就是经过hidden state输出之后再经过全连接层的输出
是第i个decoder的位置的输出,就是经过hidden state输出之后再经过全连接层的输出 代表的是第i个decoder的context vector,其实输出hidden output的加权求和
代表的是第i个decoder的context vector,其实输出hidden output的加权求和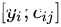 这两个的concat结果
这两个的concat结果详细的实现可以参照tensorflow的repo使用的是tf1.x Neural Machine Translation (seq2seq) tutorial. 这里的代码用的是最新的2.x的代码 code.
输入经过encoder之后得到的hidden states 的形状为 (batch_size, max_length, hidden_size) , decoder的 hidden state 形状为 (batch_size, hidden_size).
以下是被implement的等式:
This tutorial uses Bahdanau attention for the encoder. Let‘s decide on notation before writing the simplified form:
And the pseudo-code:
class BahdanauAttention(tf.keras.layers.Layer):
def __init__(self, units):
super(BahdanauAttention, self).__init__()
self.W1 = tf.keras.layers.Dense(units)
self.W2 = tf.keras.layers.Dense(units)
self.V = tf.keras.layers.Dense(1)
def call(self, query, values):
# hidden shape == (batch_size, hidden size)
# hidden_with_time_axis shape == (batch_size, 1, hidden size)
# we are doing this to perform addition to calculate the score
hidden_with_time_axis = tf.expand_dims(query, 1)
# score shape == (batch_size, max_length, 1)
# we get 1 at the last axis because we are applying score to self.V
# the shape of the tensor before applying self.V is (batch_size, max_length, units)
score = self.V(tf.nn.tanh(
self.W1(values) + self.W2(hidden_with_time_axis)))
# attention_weights shape == (batch_size, max_length, 1)
attention_weights = tf.nn.softmax(score, axis=1)
# context_vector shape after sum == (batch_size, hidden_size)
context_vector = attention_weights * values
context_vector = tf.reduce_sum(context_vector, axis=1)
return context_vector, attention_weights
class Encoder(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim, enc_units, batch_sz):
super(Encoder, self).__init__()
self.batch_sz = batch_sz
self.enc_units = enc_units
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
self.gru = tf.keras.layers.GRU(self.enc_units,
return_sequences=True,
return_state=True,
recurrent_initializer=‘glorot_uniform‘)
def call(self, x, hidden):
x = self.embedding(x)
output, state = self.gru(x, initial_state = hidden)
return output, state
def initialize_hidden_state(self):
return tf.zeros((self.batch_sz, self.enc_units))
class Decoder(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim, dec_units, batch_sz):
super(Decoder, self).__init__()
self.batch_sz = batch_sz
self.dec_units = dec_units
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
self.gru = tf.keras.layers.GRU(self.dec_units,
return_sequences=True,
return_state=True,
recurrent_initializer=‘glorot_uniform‘)
self.fc = tf.keras.layers.Dense(vocab_size)
# used for attention
self.attention = BahdanauAttention(self.dec_units)
def call(self, x, hidden, enc_output):
# enc_output shape == (batch_size, max_length, hidden_size)
context_vector, attention_weights = self.attention(hidden, enc_output)
# x shape after passing through embedding == (batch_size, 1, embedding_dim)
x = self.embedding(x)
# x shape after concatenation == (batch_size, 1, embedding_dim + hidden_size)
x = tf.concat([tf.expand_dims(context_vector, 1), x], axis=-1)
# passing the concatenated vector to the GRU
output, state = self.gru(x)
# output shape == (batch_size * 1, hidden_size)
output = tf.reshape(output, (-1, output.shape[2]))
# output shape == (batch_size, vocab)
x = self.fc(output)
return x, state, attention_weights
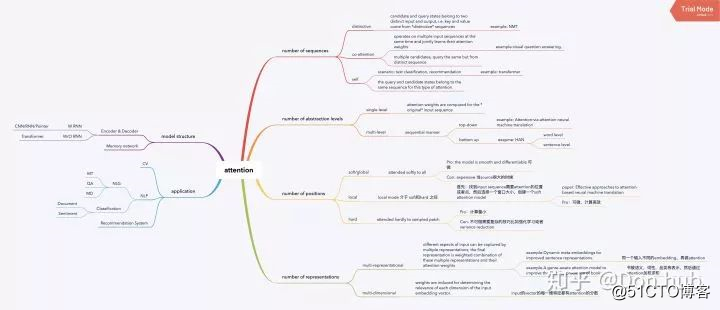
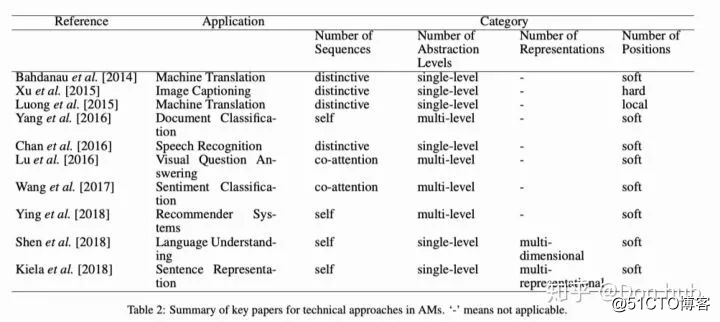
根据不同的分类标准,可以将attention分为多个类别,但是具体来说都是q(query)k(key)以及v(value)之间的交互,通过q以及k计算score,这个score的计算方法各有不同如下表,再经过softmax进行归一化。最后在将计算出来的score于v相乘加和(或者取argmax 参见pointer network)。
Below is a summary table of several popular attention mechanisms and corresponding alignment score functions:
(*) Referred to as “concat” in Luong, et al., 2015 and as “additive attention” in Vaswani, et al., 2017. (^) It adds a scaling factor 1/n ̄√1/n, motivated by the concern when the input is large, the softmax function may have an extremely small gradient, hard for efficient learning.
以下的分类不是互斥的,比如说HAN模型,就是一个multi-level,soft,的attention model(AM)。
根据我们的query以及value来自的sequence来分类。
attention的query和value分别来自不同两个不同的input sequence和output sequence,例如我们上文提到的NMT,我们的query来自于decoder的hidden state,我们的value来自去encoder的hidden state。
co-attention 模型对多个输入sequences进行联合学习权重,并且捕获这些输入的交互作用。例如visual question answering 任务中,作者认为对于图片进行attention重要,但是对于问题文本进行attention也同样重要,所以作者采用了联合学习的方式,运用attention使得模型能够同时捕获重要的题干信息以及对应的图片信息。
例如文本分类或者推荐系统,我们的输入是一个序列,输出不是序列,这种场景下,文本中的每个词,就去看与自身序列相关的词的重要程度关联。如下图
我们可以看看bert的self attention的实现的函数说明,其中如果from tensor= to tensor,那就是self attention
def attention_layer(from_tensor,
to_tensor,
attention_mask=None,
num_attention_heads=1,
size_per_head=512,
query_act=None,
key_act=None,
value_act=None,
attention_probs_dropout_prob=0.0,
initializer_range=0.02,
do_return_2d_tensor=False,
batch_size=None,
from_seq_length=None,
to_seq_length=None):
"""Performs multi-headed attention from `from_tensor` to `to_tensor`.
This is an implementation of multi-headed attention based on "Attention
is all you Need". If `from_tensor` and `to_tensor` are the **same**, then
this is self-attention. Each timestep in `from_tensor` attends to the
corresponding sequence in `to_tensor`, and returns a fixed-with vector
"""这是根据attention计算权重的层级来划分的。
在最常见的case中,attention都是在输入的sequence上面进行计算的,这就是普通的single-level attention。
但是也有很多模型,例如HAN,模型结构如下。模型是hierarchical的结构的,它的attention也是作用在多层结构上的。我们介绍一下这个模型的作用,它主要做的是一个文档分类的问题,他提出,文档是由句子组成的,句子又是由字组成的,所以他就搭建了两级的encoder(双向GRU)表示,底下的encoder编码字,上面的encoder编码句子。在两个encoder之间,连接了attention层,这个attention层是编码字层级上的注意力。在最后输出作文本分类的时候,也使用了一个句子层级上的attention,最后输出来Dense进行句子分类。需要注意的是,这里的两个query 以及 都是随机初始化,然后跟着模型一起训练的,score方法用的也是Dense方法,但是这边和NMT不同的是,他是self attention。
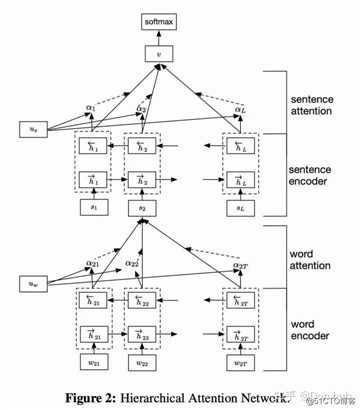
根据attention 层关注的位置不同,我们可以把attention分为三类,分别是global/soft(这两个几乎一样),local以及hard attention。Effective Approaches to Attention-based Neural Machine Translation. 提出了local global attention,Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. 提出了hard soft attention
global/soft attention 指的是attention 的位置为输入序列的所有位置,好处在与平滑可微,但是坏处是计算量大。
hard attention 的context vector是从采样出来的输入序列hidden states进行计算的,相当于将hidden states进行随机选择,然后计算attention。这样子可以减少计算量,但是带来的坏处就是计算不可微,需要采用强化学习或者其他技巧例如variational learning methods。
local的方式是hard和soft的折中 - 首先从input sequence中找到一个需要attention的点或者位置 - 在选择一个窗口大小,create一个local的soft attention 这样做的好处在于,计算是可微的,并且减少了计算量
通常来说single-representation是最常见的情况,which means 一个输入只有一种特征表示。但是在其他场景中,一个输入可能有多种表达,我们按输入的representation方式分类。
在一些场景中,一种特征表示不足以完全捕获输入的所有信息,输入特征可以进行多种特征表示,例如Show, attend and tell: Neural image caption generation with visual attention. 这篇论文就对文本输入进行了多种的word embedding表示,然后最后对这些表示进行attention的权重加和。再比如,一个文本输入分别词,语法,视觉,类别维度的embedding表示,最后对这些表示进行attention的权重加和。
顾名思义,这种attention跟维度有关。这种attention的权重可以决定输入的embedding向量中不同维度之间的相关性。其实embedding中的维度可以看作一种隐性的特征表示(不像one_hot那种显性表示直观,虽然缺少可解释性,但是也算是特征的隐性表示),所以通过计算不同维度的相关性就能找出起作用最大的特征维度。尤其是解决一词多义时,这种方式非常有效果。所以,这种方法在句子级的embedding表示、NLU中都是很有用的。
介绍了那么多的attention类别,那么attention通常是运用在什么网络上的呢,我们这边总结了两种网络,一种是encoder-decoder based的一种是memory network。
encoder-decoder网络+attention是最常见的+attention的网络,其中NMT是第一个提出attention思想的网络。这边的encoder和decoder是可以灵活改变的,并不绝对都是RNN结构。
对于图片转文字这种任务,可以将encoder换成CNN,文字转文字的任务可以使用RNN+RNN。
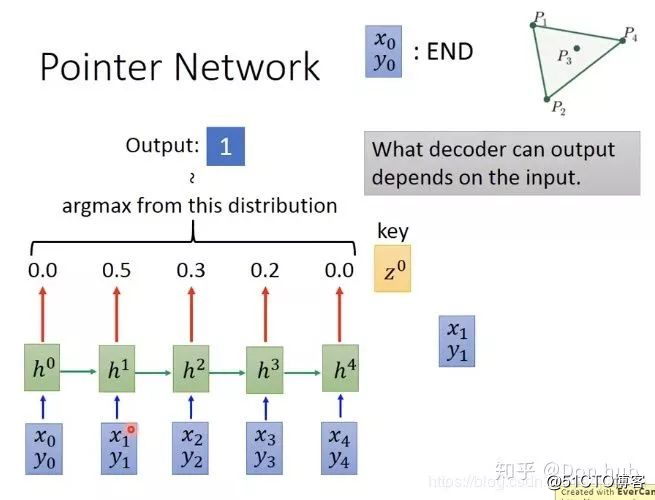
并不是所有的序列输入和序列输出的问题都可以使用encoder-decoder模型解决,(e.g. sorting or travelling salesman problem). 例如下面这个问题:我们想要找到一堆的点,能够将图内所有的点包围起来。我们期望得到的效果是,输入所有的点  最后输出的是
最后输出的是 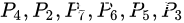
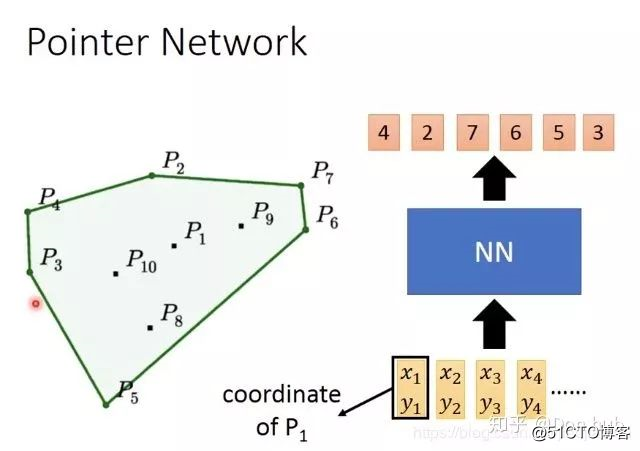
如果直接下去训练的话,下图所示:input 4个data point的坐标,得到一个红色的vector,再把vector放到decoder中去,得到distribution,再做sample(比如做argmax,决定要输出token 1...),最终看看work不work,结果是不work。比如:训练的时候有50 个点,编号1-50,但是测试的时候有100个点,但是它只能选择 1-50编号的点,后面的点就选不了了。
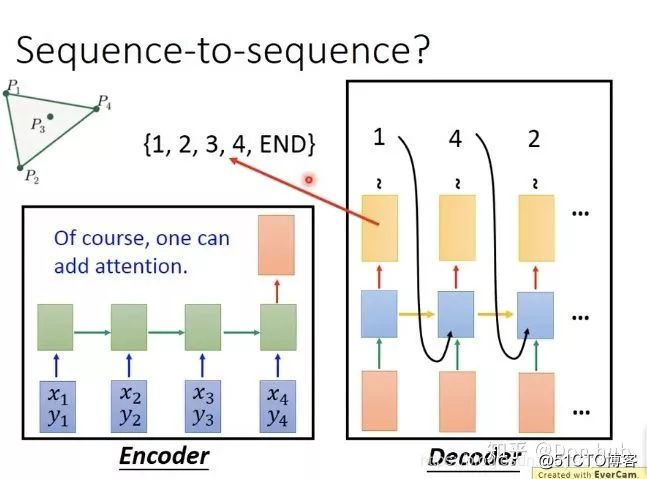
改进:attention,可以让network动态的决定输出的set有多大
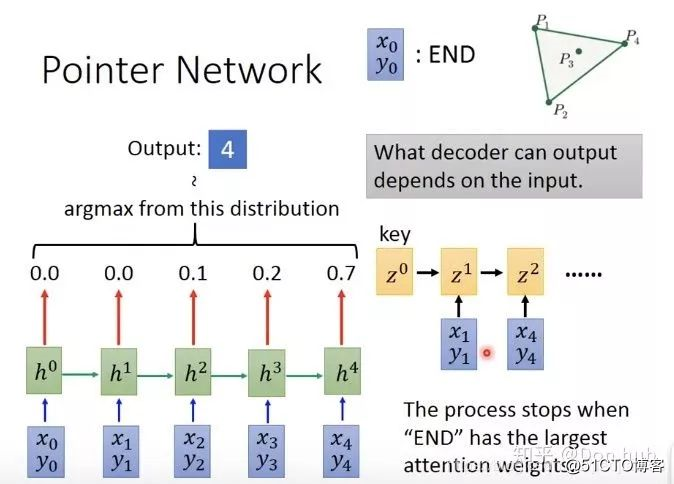
x0,y0代表END这些词,每一个input都会得到一个attention的weight=output的distribution。
最后的模型的结束的条件就是 点的概率最高
transformer网络使用的是encoder+decoder网络,其主要是解决了RNN的计算速度慢的问题,通过并行的self attention机制,提高了计算效率。但是与此同时也带来了计算量大,空间消耗过大的问题,导致sequence length长度不能过长的问题,解决参考transformerXL。(之后会写一篇关于transformer的文章) - multihead的作用:有点类似与CNN的kernel,主要捕获不同的特征信息
像是question answering,或者聊天机器人等应用,都需要传入query以及知识数据库。End-to-end memory networks.通过一个memroy blocks数组储存知识数据库,然后通过attention来匹配query和答案。memory network包含四部分内容:query(输入)的向量、一系列可训练的map矩阵、attention权重和、多hop推理。这样就可以使用KB中的fact、使用history中的关键信息、使用query的关键信息等进行推理,这在QA和对话中至关重要。(这里需要补充)
Multiple papers use self attention mechanism for ?nding the most relevant items in user’s history to improve item recommendations either with collaborative ?ltering framework [He et al., 2018; Shuai Yu, 2019], or within an encoderdecoder architecture for sequential recommendations [Kang and McAuley, 2018; Zhou et al., 2018].
Recently attention has been used in novel ways which has opened new avenues for research. Some interesting directions include smoother incorporation of external knowledge bases, pre-training embeddings and multi-task learning, unsupervised representational learning, sparsity learning and prototypical learning i.e. sample selection.
深度解析LSTM神经网络的设计原理
图卷积网络(GCN)新手村完全指南
论文赏析[ACL18]基于Self-Attentive的成分句法分析
标签:item 目的 passing function ica mos 机器 encoder 推荐
原文地址:https://blog.51cto.com/15009309/2553141