标签:分布 不可 就会 交流 就是 技术 推荐阅读 北京 蓝色
评测时如何构造训练数据分布与测试数据分布保持一致在很多评测的时候,主办方只会给我们标准数据,并不会给我们测试数据,这个时候,如果我们用标准数据来训练,但是在真实的测试过程中,输入数据的并不会是标准数据,这会导致训练与测试的两个过程中的数据分布不一样,那么自然最后的结果不一样。
评测的内容是得到句法分析之后的结果,但是需要端对端的一个要求,句法分析的输入是分词和词性标注完的结果,而主办方给的训练数据中,一句话的分词和词性标注都是正确标准的。
如果我们是基于这个标准数据训练出来的模型,在测试集合中一定效果不好,因为训练和测试的数据分布就不一样,这个怎么理解呢?
因为在训练的过程中,比如“我去北京”训练数据送给句法分析的分词和词性标注的输入是我/n 去/v 北京/n,所有的数据就会基于这样一个标准正确的数据分布训练得到一个模型。
但是在真实的测试过程中,来了一个句子“我去北京”,首先通过自己的分词和词性标注器处理后,得到的结果可能有错误,比如结果为我去/n 北京/n,然后送给句法分析器中去,得到句法分析,那么句法分析的结果肯定就不好,因为两者数据的分布就不一样。
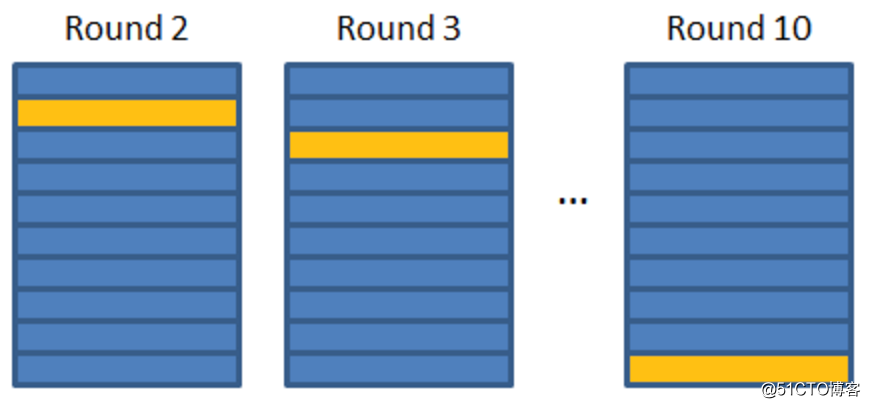
首先可以将训练数据分为10份,将其中的9份作为训练集(如下蓝色部分),其中的一份作为测试集(如下黄色部分)
通过这个训练数据,训练一个分词和词性标注器,然后对测试数据进行分词和词性标注。这个结果对黄色部分数据来说,就会与测试数据的分布接近,已经不是标准数据了。
然后还有其他9份数据,这个时候类似于K折交叉验证的思想。我们再将其余的9份数据依次作为测试数据。
图来自:K折交叉验证 · GitBookhttps://www.gitbook.com/book/suetming/k-fold-cross-validation/details
这样处理之后,原来训练数据的10份数据都不再是原来的标准gold数据(因为事实上测试的时候,准确率不可能是100%,也就是不会是标准gold数据)
而是经过前期处理后的数据,每一份都是基于自动的分词和词性标注器产生的数据,这样与测试数据的分布能够更近。
参考:文中图与题图来自于GitBookhttps://www.gitbook.com/book/suetming/k-fold-cross-validation/details
致谢:德川、骁骋师兄、灏洋、晓明师兄
为什么要对数据进行归一化处理?
logistic函数和softmax函数
视频讲解|为什么神经网络参数不能全部初始化为全0
全是通俗易懂的硬货!只需置顶~欢迎关注交流~

标签:分布 不可 就会 交流 就是 技术 推荐阅读 北京 蓝色
原文地址:https://blog.51cto.com/15009309/2553611