标签:就是 mina 之间 like 推导 含义 基本 最大值 两种
GAN的数学推导前面我们讲了一下GAN的基本思想,最近看了一下GAN的论文,又恰好看到了李宏毅老师的课程,感觉里面的数学推导很有意思,所以准备写下来以备之后查阅。
首先需要一点预备知识,KL divergence,这是统计中的一个概念,是衡量两种概率分布的相似程度,其越小,表示两种概率分布越接近。 对于离散的概率分布,定义如下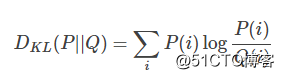
对于连续的概率分布,定义如下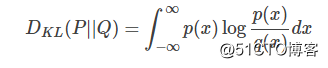
根据我们之前讲的内容,我们要做的事情就如下图所示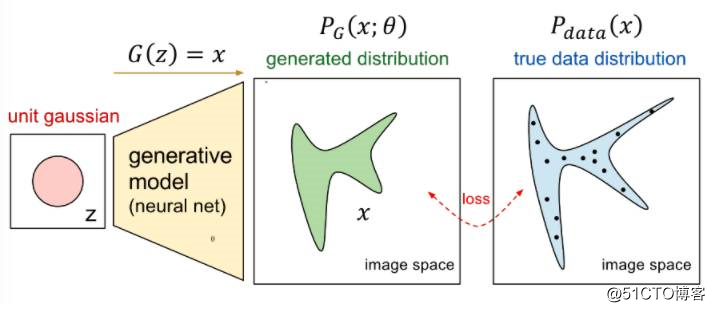
我们想要将一个随机高斯噪声z通过一个生成网络G得到一个和真的数据分布差不多的生成分布。
其中的参数是网络的参数决定的,我们希望找到 使得和尽可能接近。
我们从真实数据分布 里面取样m个点,
里面取样m个点,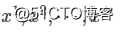 ,根据给定的参数
,根据给定的参数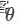 我们可以计算如下的概率
我们可以计算如下的概率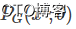 ,那么生成这m个样本数据的似然(likelihood)就是
,那么生成这m个样本数据的似然(likelihood)就是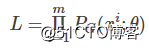
我们想要做的事情就是找到 θ?来最大化这个似然估计
而 PG(x;θ)如何算出来呢?
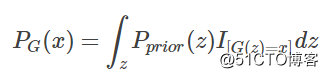
里面的I表示示性函数,也就是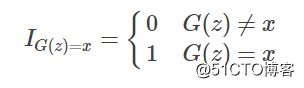
这样我们其实根本没办法求出这个 PG(x) 出来,这就是生成模型的基本想法。
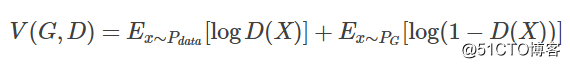
我们可以通过下面的式子求得最优的生成模型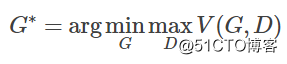
是不是感觉很晕,为什么定义了一个V(G, D)然后通过求max和min就能够取得最优的生成模型呢?
首先我们只考虑 maxDV(G,D),看其表示什么含义。
在给定G的前提下,我们要取一个合适的D使得V(G, D)能够取得最大值,这就是简单的微积分。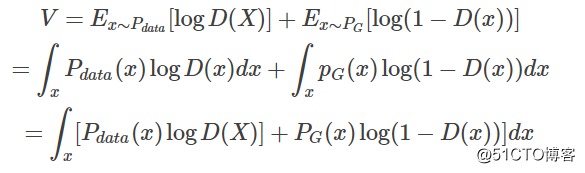
对于这个积分,要取其最大值,我们希望对于给定的x,积分里面的项是最大的,也就是我们希望取到一个最优的 D?最大化下面这个式子
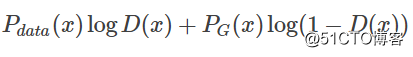
在数据给定,G给定的前提下,Pdata(x)与PG(x) 都可以看作是常数,我们可以分别用a,b来表示他们,这样我们就可以得到如下的式子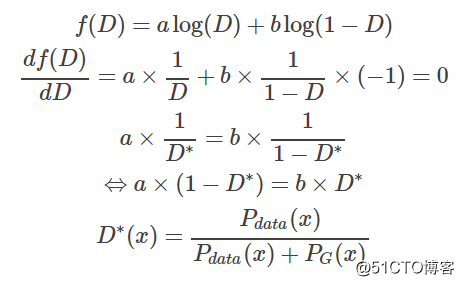
这样我们就求得了在给定G的前提下,能够使得V(D)取得最大值的D,我们将D代回原来的V(G, D),得到如下的结果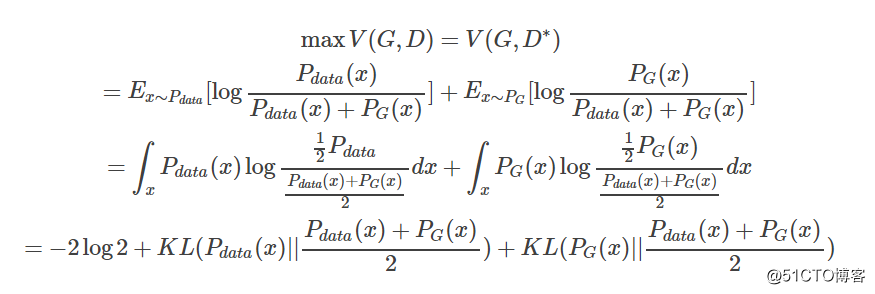
看到这里我们其实就已经推导出了为什么这么衡量是有意义的,因为我们取D使得V(G,D)取得max值。
这个时候这个max值是由两个KL divergence构成的,相当于这个max的值就是衡量 PG(x)与Pdata(x)的差异程度,所以这个时候,我们取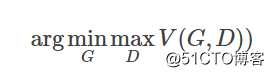
就能够取到G使得这两种分布的差异性最小,这样自然就能够生成一个和原分布尽可能接近的分布。
同时这样也摆脱了计算极大似然估计,所以GAN本质是改变了训练的过程。
欢迎访问我的知乎专栏:深度练丹
博客地址:https://sherlockliao.github.io/2017/06/20/gan_math/
全是通俗易懂的硬货!只需置顶~欢迎关注交流~
标签:就是 mina 之间 like 推导 含义 基本 最大值 两种
原文地址:https://blog.51cto.com/15009309/2553601