标签:平衡 有关 erro var 面积 hold 工作 整合 元素
【内容简介】系统详解分类器性能指标,什么是准确率 - Accuracy、精确率 - Precision、召回率 - Recall、F1值、ROC曲线、AUC曲线、误差 - Error、偏差 - Bias、方差 - Variance及Bias-Variance Tradeoff在任何领域,评估(Evaluation)都是一项很重要的工作。在Machine Learning领域,定义了许多概念并有很多手段进行评估工作
确率定义:对于给定的测试数据集,分类器正确分类的样本数与总样本数的之比
通过准确率,的确可以在一些场合,从某种意义上得到一个分类器是否有效,但它并不总是能有效的评价一个分类器的工作。一个例子,Google抓取了100个特殊页面,它的索引中有10000000页面。随机抽取一个页面,这是不是特殊页面呢?如果我们的分类器确定一个分类规则:“只要来一个页面就判断为【不是特殊页面】”,这么做的效率非常高,如果计算按照准确率的定义来计算的话,是(9,999,900/10,000,000) = 99.999%。虽然高,但是这不是我们并不是我们真正需要的值,就需要新的定义标准了
对于一个二分类问题来说,将实例分为正类(Positive/+)或负类(Negative/-),但在使用分类器进行分类时会有四种情况
为了全面的表达所有二分问题中的指标参数,下列矩阵叫做混淆矩阵 - Confusion Matrix,目的就是看懂它,搞清楚它,所有模型评价参数就很清晰了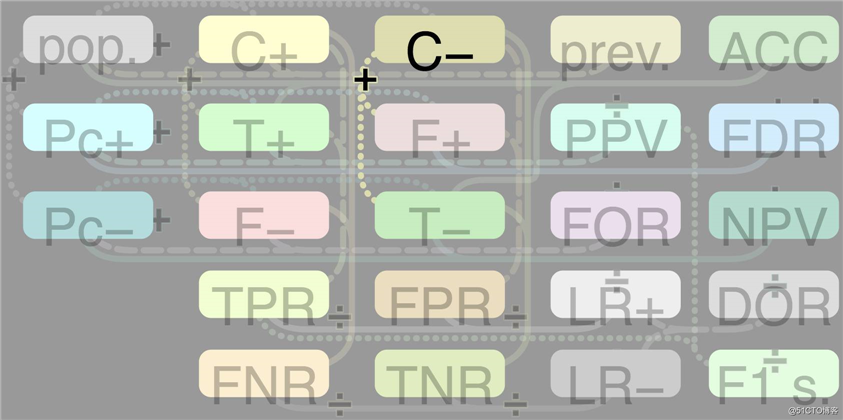
通过上面的的讨论已经有T+:TP F+:FP T-:TN F-:FN C+:样本正类 C-:样本负类 Pc+:预测正类 Pc-:预测负类
用样本中的正类和负类进行计算的定义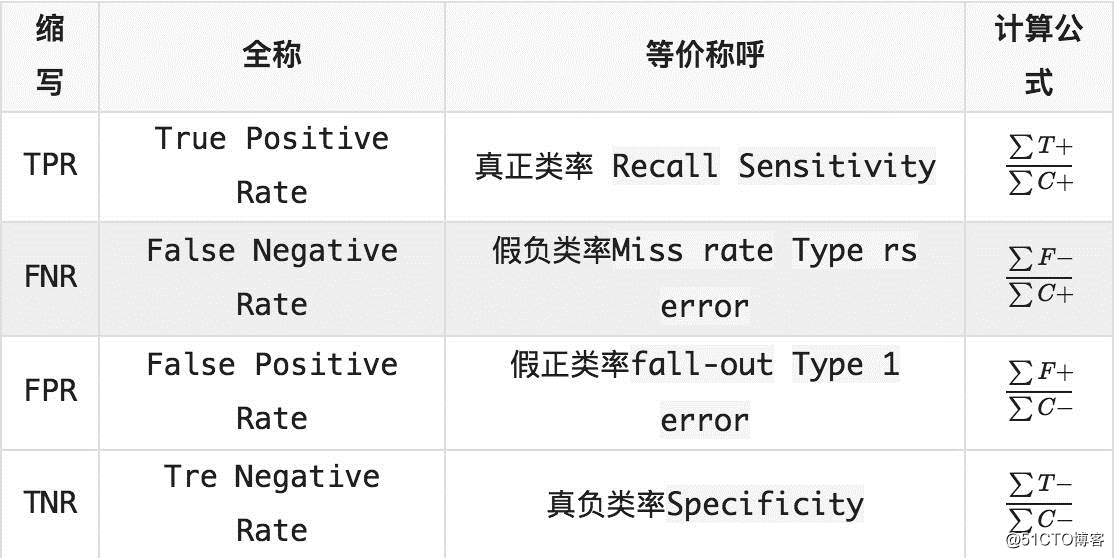
用预测结果的正类和负类进行计算的定义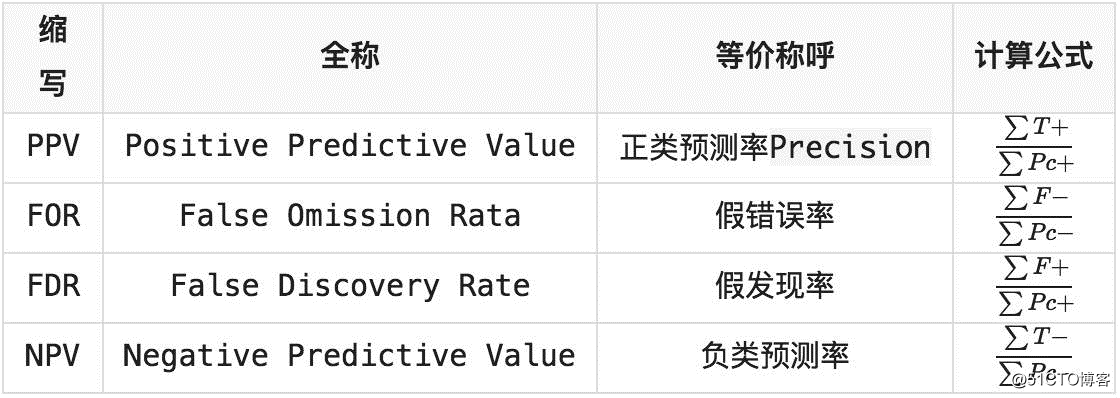
其他定义概念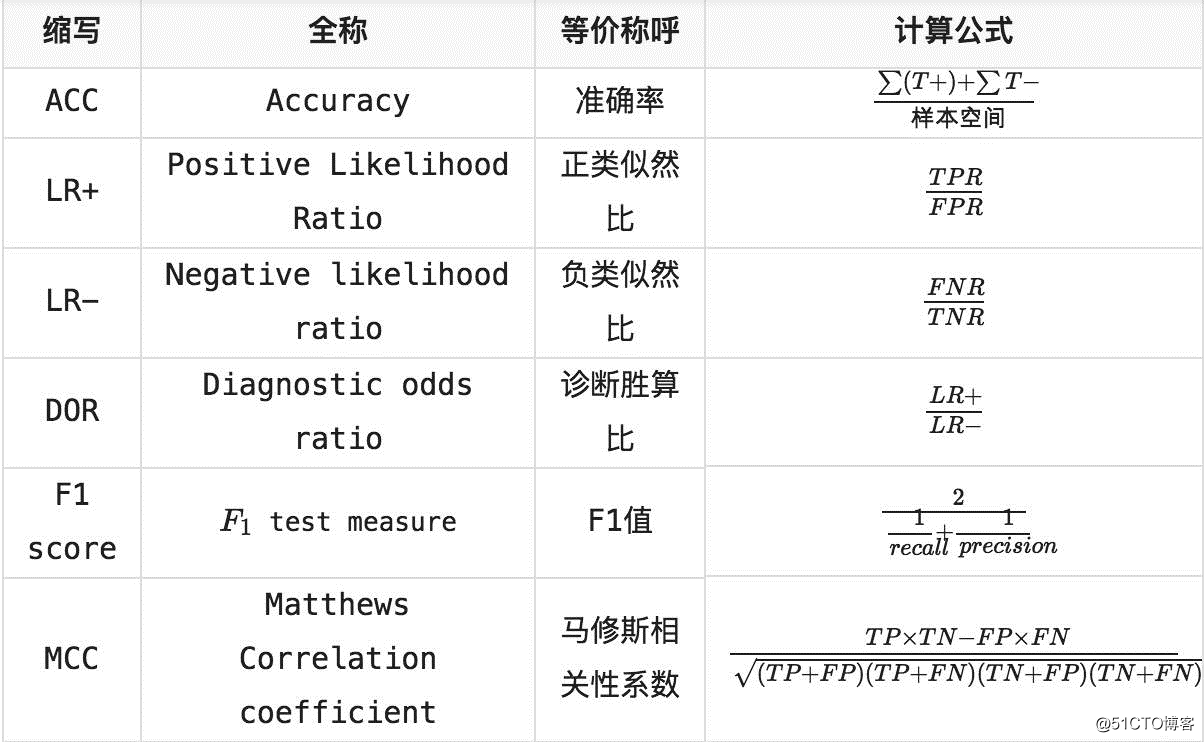

最终为了不那么麻烦,说人话,还是一图胜千言
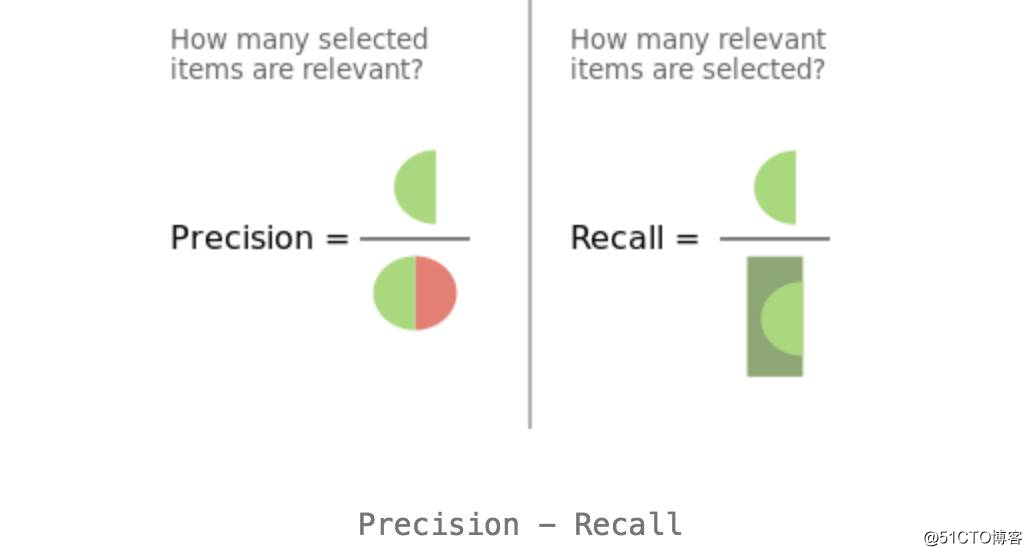
左边暗一些部分的点都是真正的正类,右边亮一些部分的点都是真正的负类
中间的一个圆圈就是我们的正类分类器:注意,这个圈是的预测结果都是正类,也就是说在这个分类器看来,它选择的这些元素都是它所认为的正类,对应的,当然是圈以外的部分,也就是预测结果是负类的部分
底下的Precision和Recall示意图也相当的直观,看一下就能明白
ROC - Receiver Operating Characteristic Curve,接受者操作特征曲线,ROC曲线
这个曲线乍看下为啥名称那么奇怪呢,原来这个曲线最早是由二战中的电子工程师和雷达工程师发明的,用来侦测战场上的敌军飞机,舰艇等,是一种信号检测理论,还被应用到心理学领域做知觉检测。
ROC曲线和混淆矩阵息息相关,上一部分已经详细解释了相关内容,这里直接说明ROC曲线的横坐标和纵坐标分别是什么
横坐标:FPR假正类率,纵坐标:TPR真正类率
初看之下你不懂一个曲线表示的什么意思,那么看几个特征点或特殊曲线是一个非常好的方法。按照这种方法来分析ROC曲线:
总结来说,ROC曲线的面积越大,模型的效果越好;ROC曲线光滑以为着Overfitting越少
还是一图胜千言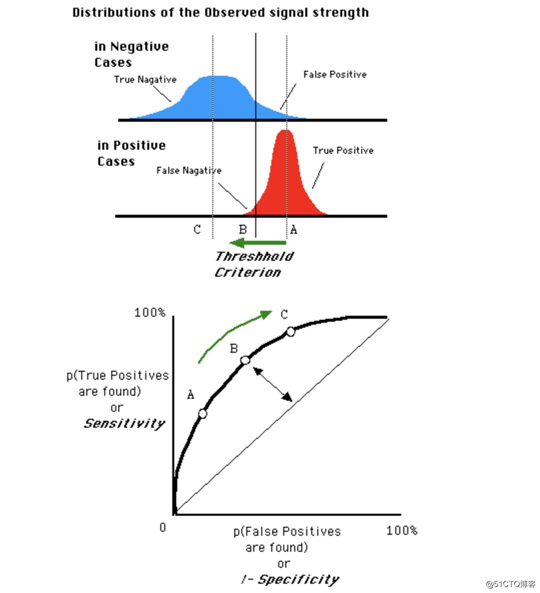

如果问这个分类器画成的图像为何是一个类似帽子的形状,例子是最佳的说明方法,我们就来算一个ROC曲线看看,下图是20个测试样本的结果,“Class”一栏表示每个测试样本真正的标签(p表示正类,n表示负类),“Score”表示每个测试样本属于正样本的概率,Inst#是序号数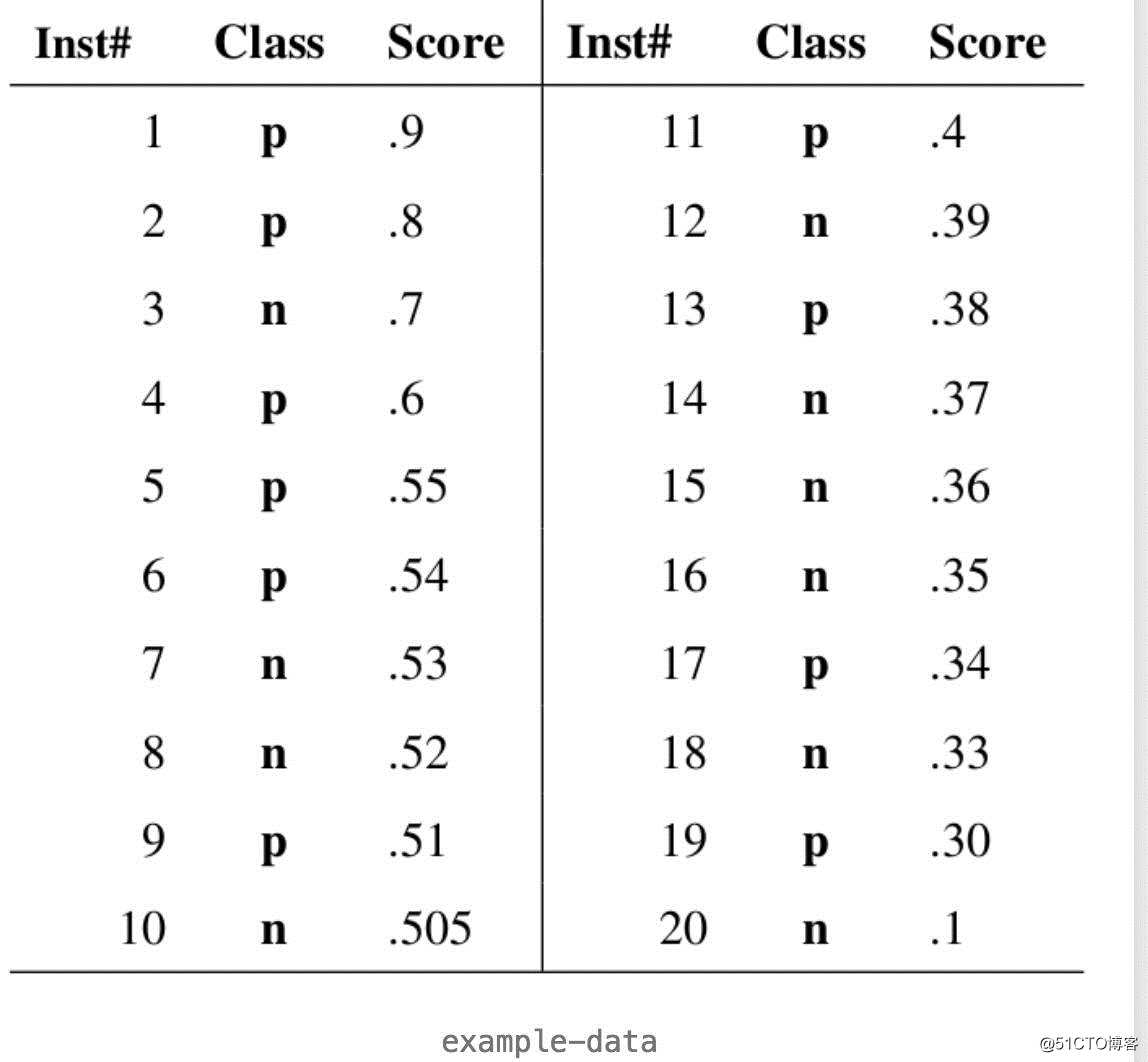
接下来,我们从高到低,依次将“Score”值作为阈值threshold,当测试样本属于正样本的概率大于或等于这个threshold时,我们认为它为正样本,否则为负样本。举例来说,对于图中的第4个样本,其“Score”值为0.6,那么样本1,2,3,4都被认为是正样本,因为它们的“Score”值都大于等于0.6,而其他样本则都认为是负样本。每次选取一个不同的threshold,我们就可以得到一组FPR和TPR,即ROC曲线上的一点。这样一来,我们一共得到了20组FPR和TPR的值(和你的测试样本的数量有关),将它们画在ROC曲线的结果如下图: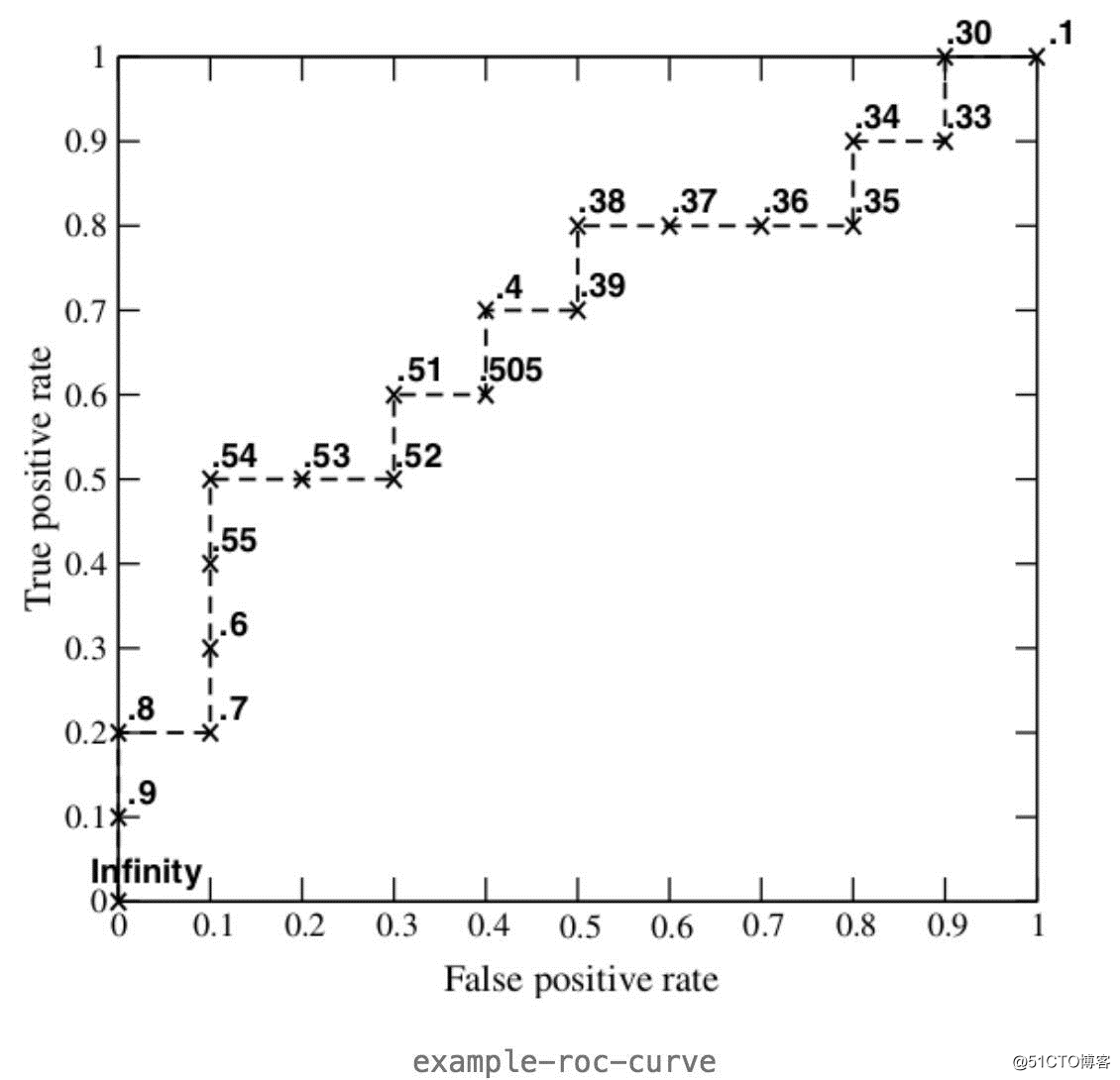
在上图中,(a)和(c)为ROC曲线,(b)和(d)为Precision-Recall曲线。
(a)和(b)展示的是分类其在原始测试集(正负样本分布平衡)的结果,(c)和(d)是将测试集中负样本的数量增加到原来的10倍后,分类器的结果。可以明显的看出,ROC曲线基本保持原貌,而Precision-Recall曲线则变化较大,记住这个结论即可
在上面提到了一个指标,PRC - Precision-Recall 曲线,画法和ROC很相似,但是使用值是Precision和Recall
AUC - Area Under Curve被定义为ROC曲线下的面积
AUC在[0.5,1]之间,这是因为ROC曲线一般都处于y=x这条直线的上方(否则这个做分类器的人连简单的取非都不会真可以去死了)
AUC值越大,证明这个模型越好
三个名词,Error误差 Bisa偏差 Variance方差
再来一次,一图胜千言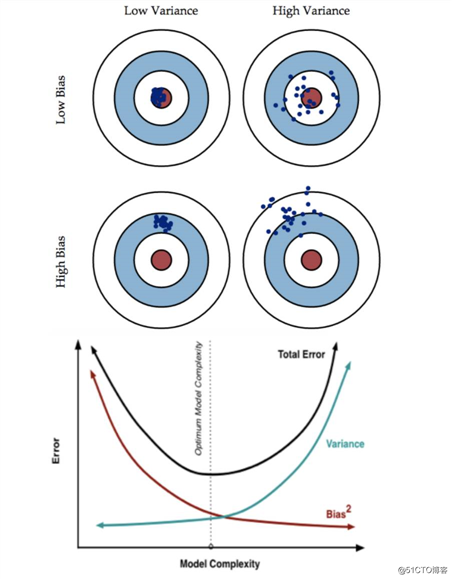


感觉在实际使用中,你不需要去自己写代码来画这些曲线,只要是框架是一定整合了这些值得结果,但是知其然知其所以然,越了解它是如何画的,越能处理奇怪的特殊情况
常见的处理方式是记下来所有指标的结果,即这些指标怎么变,表示了模型的那些方面好或者坏的结论,但是如果在特殊的问题出现了不在你看的结果中的情况可能还是会捉襟见肘,还是脚踏实地,能看见更大的世界!
精选干货|近半年干货目录汇总
【直观理解】一文搞懂RNN(循环神经网络)基础篇
【直观详解】什么是PCA、SVD
欢迎关注公众号学习交流~ 
标签:平衡 有关 erro var 面积 hold 工作 整合 元素
原文地址:https://blog.51cto.com/15009309/2553972