标签:解决方案 不等式 就是 最大化 ssi 企业 inf 驾驶 http
数据处理不等式:Data Processing Inequality我是在差分隐私下看到的,新解决方案的可用性肯定小于原有解决方案的可用性,也就是说信息的后续处理只会降低所拥有的信息量。
那么如果这么说的话为什么还要做特征工程呢,这是因为该不等式有一个巨大的前提就是数据处理方法无比的强大,比如很多的样本要分类,我们做特征提取后,SVM效果很好 ,但是如果用DNN之类的CNN、AuToEncoder,那么效果反而不如原来特征。这样就能理解了,DNN提取能力更强,那么原始就要有更多的信息,在新特征下无论怎么提取,信息就那么多。
信息量越多越好么?肯定不是,否则为什么PCA要做降噪和去冗余呢?我们的目的是有效的信息最大化。
另外一种理解就是从互信息不为0(信息损失)来解释。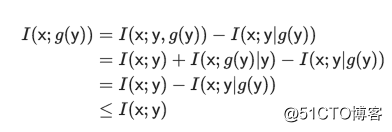
从而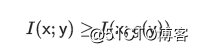
那么如何在处理过程中不丢失有效信息呢?这时候就需要数学上的充分统计量,也就是g是y的充分统计量。
精选干货|近半年干货目录汇总
福利丨4个月入门无人驾驶,进入顶尖企业从未如此简单
欢迎关注公众号学习交流~ 
欢迎加入交流群交流学习

数据处理不等式:Data Processing Inequality
标签:解决方案 不等式 就是 最大化 ssi 企业 inf 驾驶 http
原文地址:https://blog.51cto.com/15009309/2553964