标签:属性 lse parser 配置文件 使用 imp druid specific lazy
概念
原理
解决问题
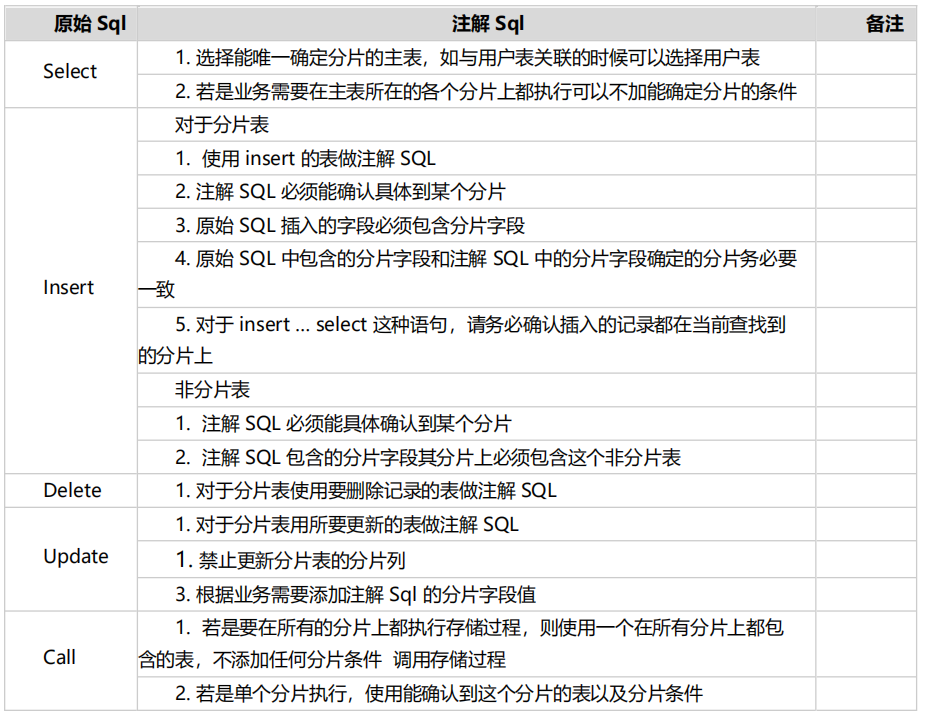
注解规范
/*#mycat:db_type=master*/ select * from travelrecord /*!mycat:db_type=slave*/ select * from travelrecord /**mycat:db_type=master*/ select * from travelrecord
/*!mycat: sql=select 1 from test */ CREATE PROCEDURE `test_proc`() BEGIN END ;
/*!mycat: sql=select 1 from test */create table test2(id int);
/*!mycat: sql=select 1 from test */insert into t_user(id,name) select id,name from t_user2;
a. 事务内的 SQL,默认走写节点,以注解/*balance*/开头,则会根据 schema.xml 的 dataHost 标签属性的 balance=“1”或“2”去获取节点 b. 非事务内的 SQL,开启读写分离默认根据 balance=“1”或“2”去获取,以注解/*balance*/开头则会走写节 点解决部分已经开启读写分离,但是需要强一致性数据实时获取的场景走写节点 /*balance*/ select a.* from customer a where a.company_id=1;
/*!mycat:catlet=demo.catlets.ShareJoin */ select a.*,b.id, b.name as tit from customer a,company b on a.company_id=b.id;
/*!mycat:db_type=master*/ select * from travelrecord /*!mycat:db_type=slave*/ select * from travelrecord /*#mycat:db_type=master*/ select * from travelrecord
/*#mycat:db_type=slave*/ select * from travelrecord
/*!mycat : schema = test_01 */ sql ;
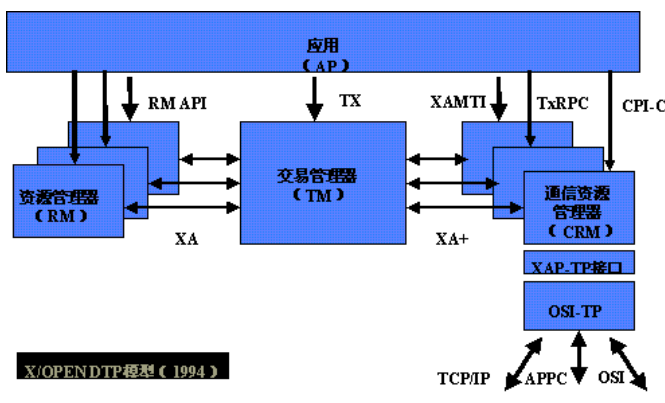
所谓的两个阶段是指准备 prepare 阶段和提交 commit 阶段。
第一阶段分为两个步骤:
1、事务管理器通知参与该事务的各个资源管理器,通知他们开始准备事务。
2、资源管理器接收到消息后开始准备阶段,写好事务日志(redo undo)并执行事务,但不提交,然后将是否就绪的消息返回给事务管理器(此时已经将事务的大部分事情做完,以后的操作耗时极小)。
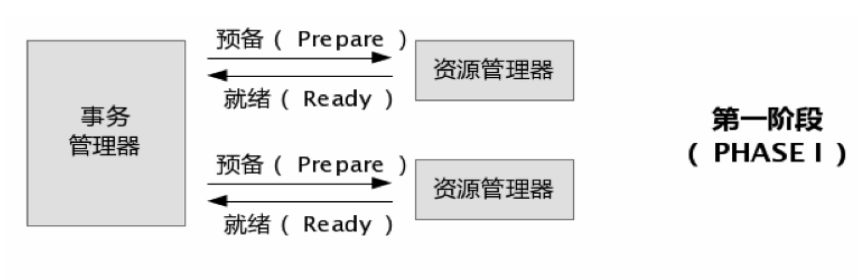
第二阶段也分为两个步骤:
1、事务管理器在接受各个消息后,开始分析,如果有任意数据库失败,则发送回滚命令,否则发送提交命令。
2、各个资源管理器接收到命令后,执行(耗时很少),并将提交消息返回给事务管理器。
事务管理器接受消息后,事务结束,应用程序继续执行。
至于为什么要分两步执行,一是因为分两步,就有了事务管理器统一管理的机会;二尽可能晚地提交事务,让事务在提交前尽可能地完成所有能完成的工作,这样,最后的提交阶段将是耗时极短,耗时极短意味着操作失败的可能性也就降低。
在 XA 的分布式事务处理模型里面涉及到三个角色 AP(应用程序)、RM(数据库)、TM(事务管理器)。AP 定义事务的开始和结束,访问事务内的资源。RM 除了数据库之外,还可以是其他的系统资源,比如文件系统,打印机服务器。 TM 负责管理全局事务,分配事务唯一标识,监控事务的执行进度,并负责事务的提交、回滚、失败恢复等,是一个协调者的角色,可能是程序或者中间件。XA 协议主要规定了了 TM 与 RM 之间的交互。注意:通过实现 XA 的接口,只是提供了对 XA 分布式事务的支持,并不是说数据库本身有分布式事务的能力。
XA 是一种两阶段提交的实现。数据库本身必须要提供被协调的接口,比如事务开启,准备,事务结束,事务提交,事务回滚。https://dev.mysql.com/doc/refman/5.7/en/xa.html
MySQL 单节点运行 XA 事务演示:
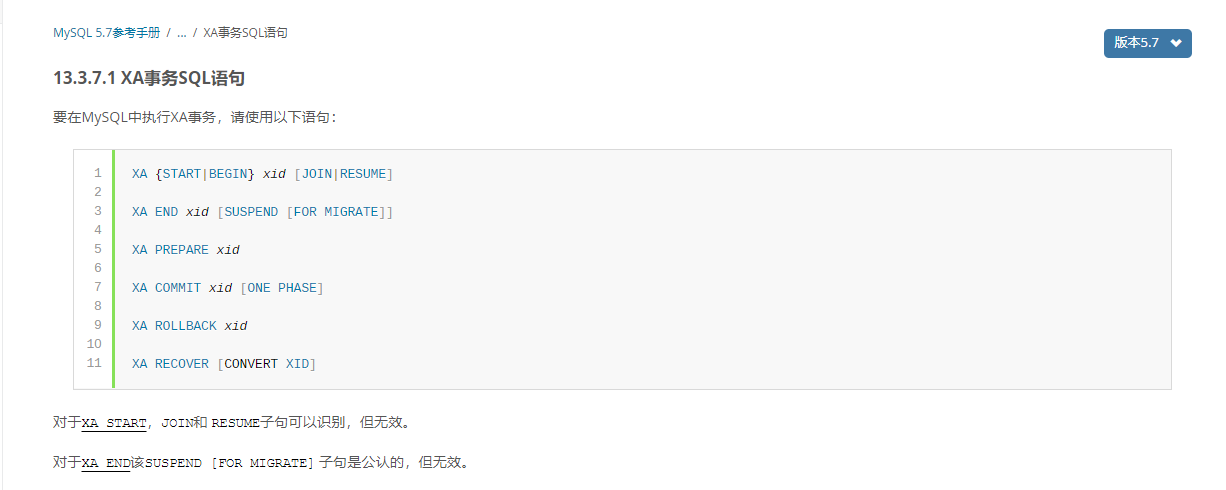
use ljxmycat; --开启 XA 事务 xa start ‘xid‘; --插入数据
INSERT INTO `delivery_mod` (id,name) VALUES (22222, ‘张三‘);
5结束一个 XA 事务
xa end ‘xid‘;
6准备提交
xa prepare‘xid‘;
--列出所有处于 PREPARE 阶段的 XA 事务
xa recover;
- 提交
xa commit ‘xid‘;
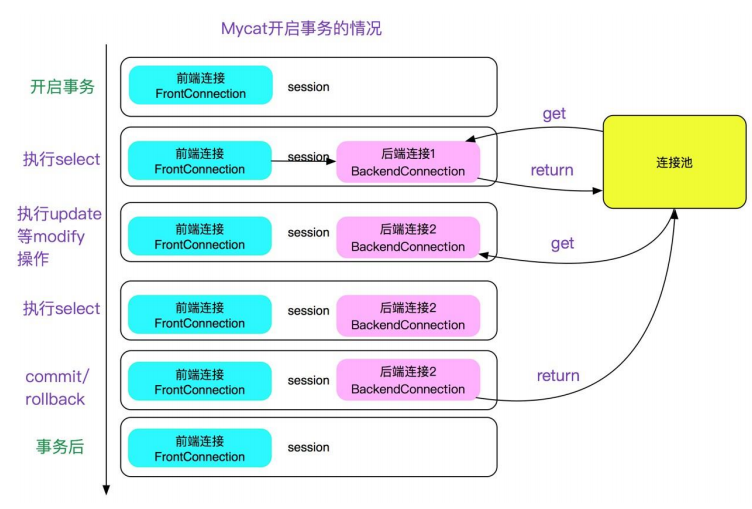
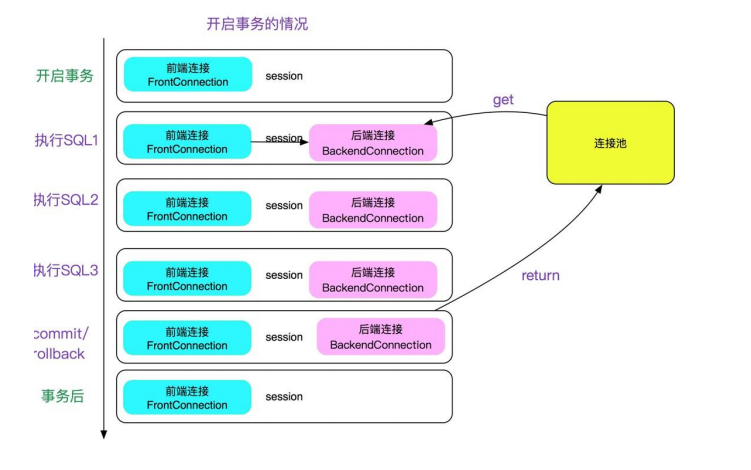
配置: <system> <property name="sqlInterceptor">io.mycat.interceptor.impl.DefaultSqlInterceptor</property> </system> 源码: /** * escape mysql escape letter */ @Override public String interceptSQL(String sql, int sqlType) { if (sqlType == ServerParse.UPDATE || sqlType == ServerParse.INSERT||sqlType == ServerParse.SELECT||sqlType == ServerParse.DELETE) { return sql.replace("\\‘", "‘‘"); } else { return sql; } }
<system> <property name="sqlInterceptor">io.mycat.interceptor.impl.StatisticsSqlInterceptor</property> <property name="sqlInterceptorType">select,update,insert,delete</property> <property name="sqlInterceptorFile">E:/mycat/sql.txt</property> </system>
1.定义自定义类 implements SQLInterceptor ,然后改写 sql 后返回。 2.将自己实现的类放入 catlet 目录,可以为 class 或 jar。 3.配置配置文件: <system> <property name="sqlInterceptor">io.mycat.interceptor.impl.自定义 class</property> <!--其他配置--> </system>
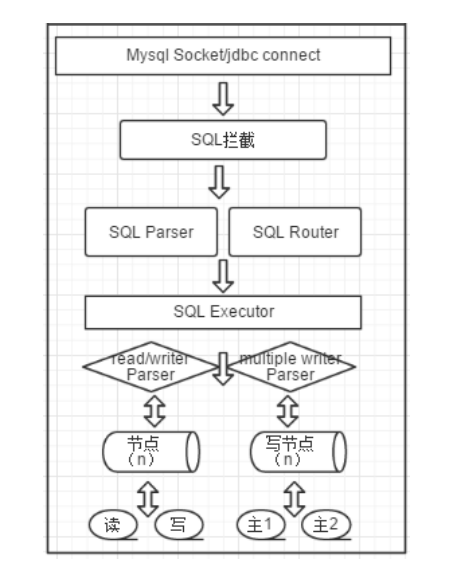
官网的架构图:
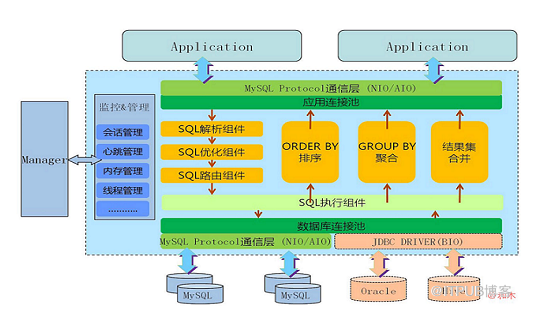
启动
1、MycatServer 启动,解析配置文件,包括服务器、分片规则等
2、创建工作线程,建立前端连接和后端连接
执行 SQL
1、前端连接接收 MySQL 命令
2、解析 MySQL,Mycat 用的是 Druid 的 DruidParser
3、获取路由
4、改写 MySQL,例如两个条件在两个节点上,则变成两条单独的 SQL
例如 select * from text where id in(5000001, 10000001);
改写成:
select * from text where id = 5000001;(dn2 执行)
select * from text where id = 10000001;(dn3 执行)
又比如多表关联查询,先到各个分片上去获取结果,然后在内存中计算
5、与后端数据库建立连接
6、发送 SQL 语句到 MySQL 执行
7、获取返回结果
8、处理返回结果,例如排序、计算等等
9、返回给客户端
目前 Mycat 没有实现对多 Mycat 集群的支持。集群之前最麻烦的是数据同步和选举。可以暂时使用 HAProxy+Keepalived 实现。
标签:属性 lse parser 配置文件 使用 imp druid specific lazy
原文地址:https://www.cnblogs.com/xing1/p/14042199.html