标签:独立 观察 必须 bug 情况 处理器 ica 中断控制 oba
原创 兰新宇 Linux阅码场 4月7日作者简介
兰新宇,坐标成都的一名软件工程师,从事底层开发多年,对嵌入式,RTOS,Linux和虚拟化技术有一定的了解,有知乎专栏“术道经纬”进行相关技术文章的分享,欢迎大家共同探讨,一起进步。
一般我们说到多核,大都是指SMP(Symmetric multi-processing),而ARM的big.LITTLE的CPU组合方案则属于HMP(Heterogeneous multi-processing)系统。
这里的"big"是指性能更强,同时功耗更高的CPU(大核),而"LITTLE"则是与之相对的性能略弱,但功耗较低的CPU(小核)。
谁不想又要性能好,又要功耗低,但是单独的一个CPU是没法满足这种互相矛盾的需求的,于是一个折中的方案就是:在一个芯片里同时包含两种在性能和功耗上存在差异的CPU。

big.LITTLE技术最早的引入是在2011年10月出现的Cortex-A7中(基于ARMv7-A架构),Cortex-A7作为“小核”,可搭配与之兼容的Cortex-A12/A15/A17使用。
而后推出的基于ARMv8-A架构且互相兼容的Cortex-A53和Cortex-A57,也可以被用来设计为big.LITTLE的模式。
这里的兼容包括了指令集(ISA)的兼容,大核和小核都属于ARM架构,只是在micro-architecture上有所区别(比如A15有6个event counter,而A7只有4个),所以它们可以运行同一个操作系统。
与之区别的另一个概念是AMP(Asymmetric multi-processing),构成AMP的CPU通常架构差异较大,且运行不同的操作系统镜像(不是一家人,不进一家门)。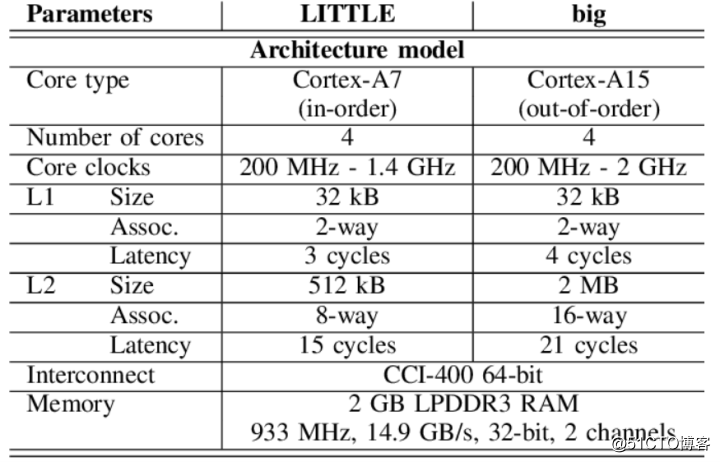
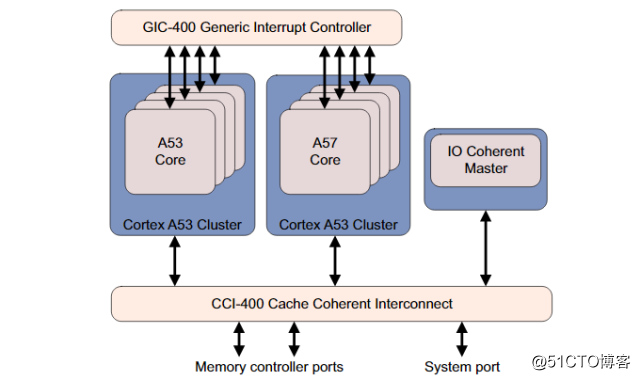
多个同构的大核构成了一个big cluster,多个同构的小核构成了一个LITTLE cluster,同一cluster的CPU共享L2 cache。
big cluster和LITTLE cluster共享中断控制器(比如GIC-400),且通过支持cache一致性的interconnect相连接(比如coreLink CCI-400)。
如果没有硬件层面的cache一致性,数据在大核和小核之间的传输将必须经过共享内存,这会严重影响效率。
【Migration】
big cluster和LITTLE cluster中的CPU被同一个操作系统所调度,OS中的任务在执行时,可以根据负载的情况,在大小核之间动态地迁移(on the fly),以提高灵活性。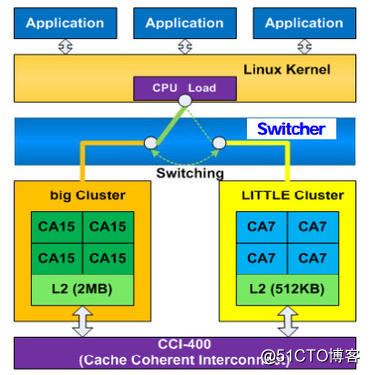
从OS调度的角度,迁移的方案可分为两种,其中最早出现也是相对最简单的是cluster migration。
* cluster migration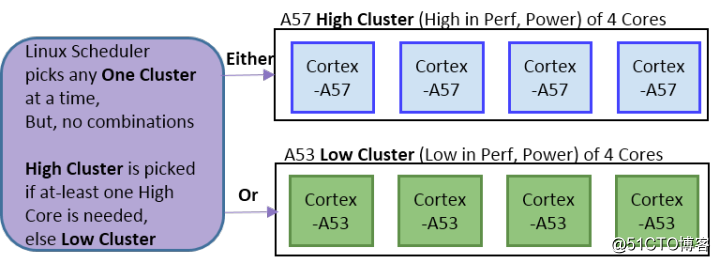
在这种方案中,OS在任何时刻都只能使用其中的一个cluster,当负载变化时,任务将从一个cluster整体切换到另一个cluster上去,也就是说,它是以cluster为单位进行migration的。早期的三星Exynos 5 Octa (5410)和NVIDIA的Tegra X1使用的就是这种模型。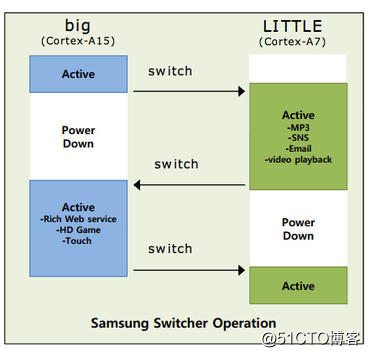
这种方案的好处是:在任一时刻,OS要么全在big cores上运行,要么全在LITTLE cores上运行,虽然整个系统是HMP的,但从OS的角度,具体到每个时刻,操作的对象都是SMP的,因此对于那些默认支持SMP的系统,使用big.LILLTE芯片时,不需要进行太多代码的修改。
* CPU migration
但是,以cluster为迁移单位,粒度实在太大了点,对于任务的负载介于big cluster和LITTLE cluster之间的,并不需要对一个cluster中的所有cores进行迁移。
而且,对一个cluster进行关闭和开启的latency通常较大,因而所需的"target_residency"也较大,切换的频率受到限制。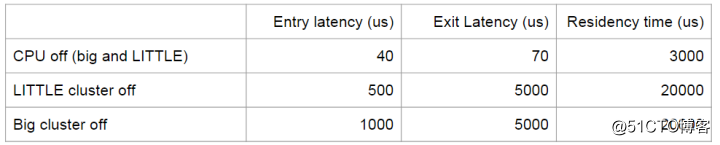
更精细的方案是big cluster和LITTLE cluster中的core能搭配使用,像下图这样,低负载时用4个小核,中等负载时用2个大核和2个小核。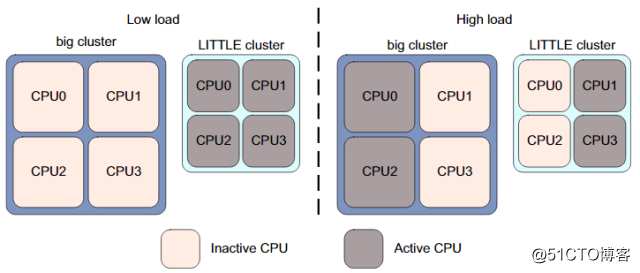
这就是以单个core为迁移单位的CPU migration方案,具体的做法是:一个大核和一个小核进行组队,形成一个pair。调度器可以使用每一组pair,但在同一时刻,只允许pair中的一个 core运行,负载高时在大核上运行,低就在小核上运行。
从OS的角度,在任一时刻,每个pair看起来都像只有一个core一样,所以这样的pair又被称为"virtual core"(或pseudo CPU)。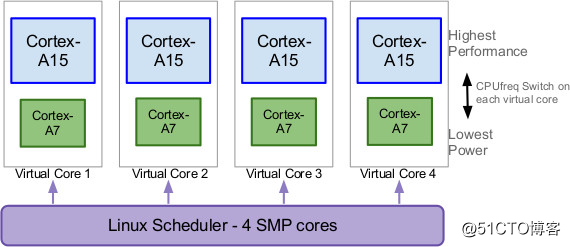
在迁移过程中,"virtual core"中的其中一个核被关闭(outbound),另一个核被同步开启(inbound),任务的context(上下文信息)从被关闭的core转移到同一pair中被开启的core上。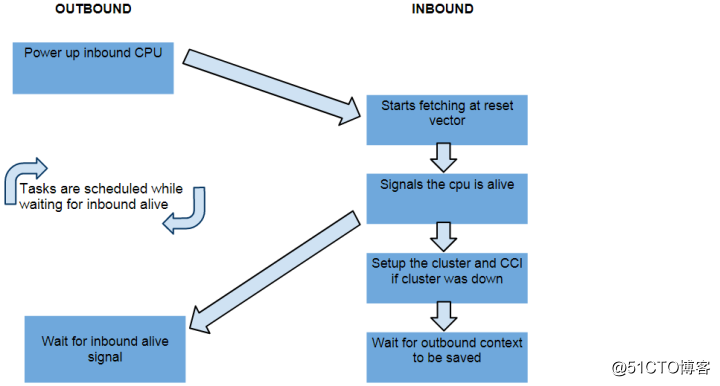
在Linux中,CPU migration的context转移依靠的是cpufreq框架,切换到哪一个core,以及什么时候切换,都由底层的cpufreq的驱动决定。
从内核的角度,它看到的是一个cpufreq展现给它的电压/频率的列表,从pair中一个core到另一个core的迁移,就好像只是调整了一下CPU的电压和频率一样,所以可以说这个CPU pair的构成对内核来说是「透明」的。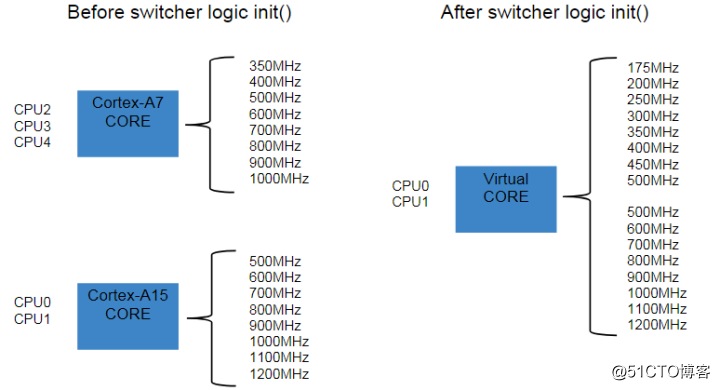
这套机制被称为IKS(In-kernel Switcher),由Linaro实现(参考ELC: In-kernel switcher for big.LITTLE),被NVIDIA的Tegra 3所采用。
【GTS】
不管是cluster migration,还是CPU migration,在某一个时刻,都只有一半的CPU cores可以处在运行状态(假设系统中大核和小核的数目相等),这对CPU资源是一种浪费。所以,一种可以充分利用各个物理核的GTS(Global Task Scheduling)方案应运而生。
在GTS模型中,高优先级或者计算密集型的任务被分配到“大核”上,其他的,比如一些background tasks,则在“小核”上运行。所有的大核和小核被统一调度,可以同时运行。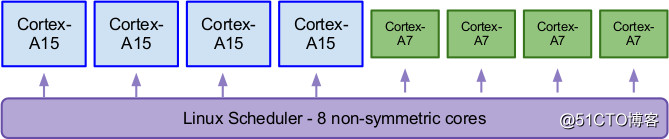
三星的Exynos 5 Octa系列自5420开始,包括5422和5430,以及苹果公司的A11,都采用的是GTS。
【负载和迁移】
何时迁移
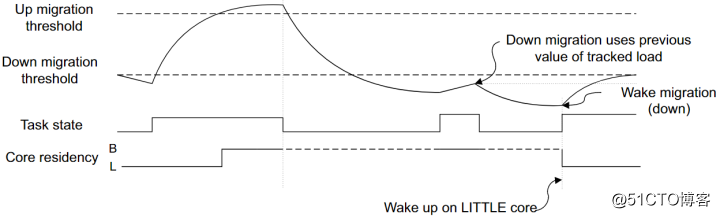
迁移的依据是负载的变化,那具体的标准是怎样的呢?当正在LITTLE core上运行的任务的平均负载超过了"up migration threshold",就将被调度器迁移到big core上继续运行;而当big core上的任务负载低于了"down migration threshold",就将被迁移到LITTLE core上。负载处在这两个threshold之间时,不做操作。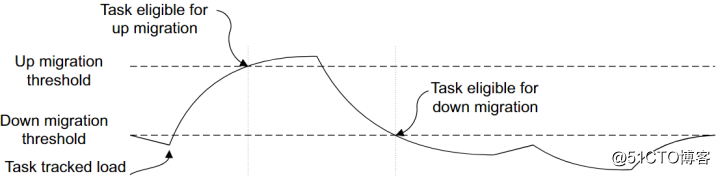
任务唤醒
当任务从睡眠状态被唤醒的时候,还没有产生负载,那如何判断它应该被放到大核还是小核上执行呢?
默认的做法是根据这个任务过去的负载情况,最简单的依据就是该任务在上次进入睡眠前所处的core。为此,需要由调度器去记录一个任务既往的负载信息。
如下图所示的这种场景,第一次唤醒时将在big core上执行("Task state"代表状态是运行还是睡眠,分别对应"Core residency"中的实线和虚线,"B"代表大核,"L"代表小核)。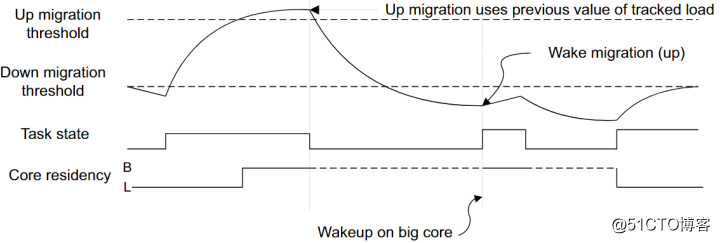
而第二次唤醒时则会调度到LITTLE core上执行。
cache line的大小问题
Cortex-A系列的ARM芯片通常是配合Linux系统使用的,而Linux在针对多核应用的设计上主要面向的是SMP,这就会带来一些问题。
其中之一就是:任务在大核和小核之间切换,但大核和小核的cache line的大小通常是不一致的(比如大核是64字节,小核是 32字节),在某些情况下这可能引发未知的bug。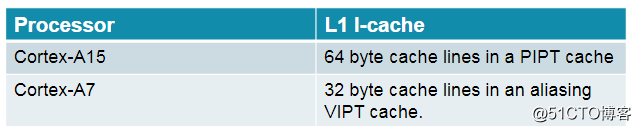
这里(https://www.mono-project.com/news/2016/09/12/arm64-icache/)给出了一个典型的案例,起因是应用会被SIGKILL信号终结,但发生时的地址看起来好像是完全随机的,而后他们观察到这些触发异常的地址全都分布在0x40-0x7for0xc0-0xff的范围内,于是猜想是因为每次cache flush的时候,只处理了每128字节中的64字节,之后如果访问到另外的64字节的区域,就会出错。
最终,他们通过打印cache line的具体内容,并查阅这个big.LITTLE芯片的手册,验证了确实是由于他们所调用的函数默认是针对cache line大小一致的SMP的,而该芯片的大小核的cache line是不同的。
DynamIQ
DynamIQ的方案于2017年5月出现,它是基于big.LITTLE进行扩展和设计的,可视作是big.LITTLE技术的演进。
同原生的big.LITTLE不同的是,因为它采用了ARMv8.2中一些独有的特性,因此与之前的ARM架构不能完全兼容,所以开始阶段只用在较新的Cortex-A75和Cortex-A55处理器上。
混搭风
在DynamIQ中,“大核”和“小核”的概念依然存在,但构成一个cluster的cores可以属于不同的micro-architecture,因此其可扩展性比big.LITTLE要强。DynamIQ允许至多32个clusters,每个cluster支持最多8个cores,具体的配置可以配成"0+8", "1+7", "2+2+4"等等。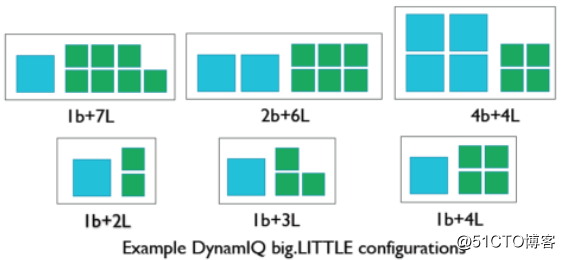
DSU和L3
每个core有自己独立的L2 cache,同一cluster的所有core共享DSU(DynamIQ Shared Unit)单元中的L3 cache。任务在大小核之间的迁移可以在同一cluster内完成,不需要跨越不同的clusters,而且迁移过程中数据的传递可以借助L3 cache,而不是CCI,减少了总线竞争,因此更加高效。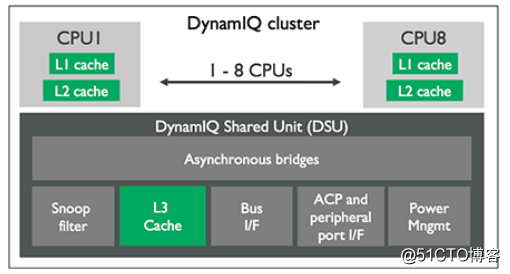
L3 cache的大小从0KB到4MB不等,因为一个cluster中的CPU数目可能较多,为了减少维护cache一致性造成的cache thrashing问题,L3可被划分为至多4个groups,且这种划分可以在软件运行期间动态进行。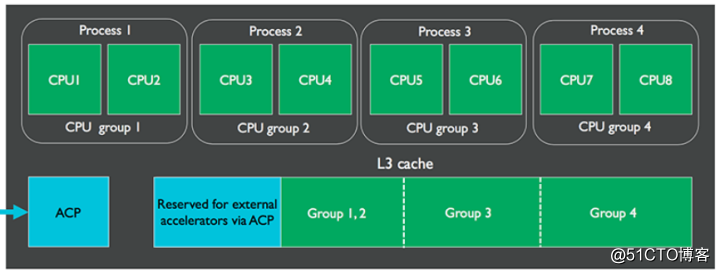
此外,当L3的使用率不高时,还可以group为单位,通过power-gating技术关闭L3中的部分存储空间,也节省其消耗的功率,这已经被Energy Aware Scheduling所支持。
(END)
标签:独立 观察 必须 bug 情况 处理器 ica 中断控制 oba
原文地址:https://blog.51cto.com/15015138/2555368