标签:32位 慢慢 性能调优 option sage 过滤 ons 为什么 序列化
在网上找了一张图,这个画的比较简单,就拿这个图来说吧。
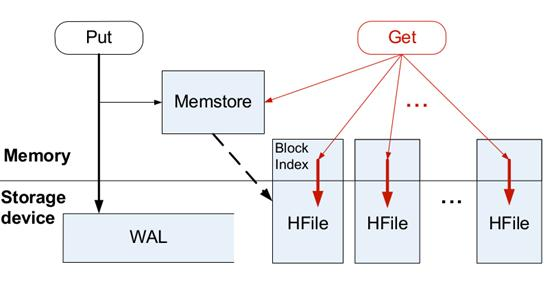
1.当Client发起一个Put请求时,首先访问Zookeeper获取hbase:meta表。
2.从hbase:meta表查询即将写入数据的Region位置。
3.Client向目标RegionServer发出写命令,同时写WAL(WAL叫预写日志,类似binlog,先写入内存,HLog每秒一次刷入磁盘)和MemStore。
4.MemStore默认满128M时,溢写入HDFS,生成StoreFile文件。
5.写数据可能会引发文件合并或者Region拆分。
1.当Client发起一个Get请求时,首先访问Zookeeper获取hbase:meta表。
2.从hbase:meta表查询即将读取数据的Region位置。
3.Client向目标RegionServer发出读命令,先从 MemStore 查找数据,如果没有再根据数据索引去StoreFile和BlockCache中查找,并把读取的最新版本数据更新到BlockCache中。
读流程其实比写流程更麻烦,当使用scan批量查找时,数据很可能分散在不同的Region和Store中,需要层层调用查询方法,并把结果汇总。
HBase使用protobufs来保存元数据或者是给远程调用传输对象。这一小节我们来聊聊Protocol Buffer。
这是一种数据序列化技术。XML、JSON这些技术我们都很熟悉了,Protocol Buffer是google内部使用的一种序列化技术,慢慢也开始流行。那么它比其他序列化技术有啥优势呢?一是体积更小,二是能够支持更复杂的结构。
我对这个技术的了解也不是很深入,尝试用大白话来解释一下。
场景:我爸是中医科医生,他们医院看病是不需要挂号的,有很多病人开了处方就去药店抓药,医院没有收入,医生的价值无法体现。中医科就编制了一张中药表,长得像下面这样,医生和药房各一份。
1.景天 2.徐长卿 3.雪见 4.紫萱 5.重楼 6.花楹 7.龙葵 8.飞蓬
不要纠结为啥都是仙剑人名,因为大学时期仙剑玩的太多了,其实这些全部是中草药。
假如有个药方,我瞎掰的:景天10g,雪见6g,重楼20g,龙葵8g
用XML表示是这样的
<药方> <景天>10g</景天> <雪见>6g</雪见> <重楼>20g</重楼> <龙葵>8g</龙葵> </药方>
用JSON表示是这样的
{景天:10g,雪见:6g,重楼:20g,龙葵:8g}
用protobuf表示大概是这样的
1:10g,3:6g,5:20g,7:8g
上面这个例子并不准确,但医生们就是这么干的,只写编号和对应的克数,病人拿这个处方去药店是抓不到药的,必须在医院药房才知道是啥。
从这个例子里可以看出,protobuf的优点是数据量很小,缺点也是显而易见的,就是可读性差,没有.proto文件根本不知道传输的是啥。
.proto文件长得是下面这样,就跟医生们的办法一样。
package hospital; message traditionalMedicine { optional int32 景天 = 1; optional int32 徐长卿 = 2; optional int32 雪见 = 3; optional int32 紫萱 = 4; optional int32 重楼 = 5; optional int32 花楹 = 6; optional int32 龙葵 = 7; optional int32 飞蓬 = 8; }
protocol buffer不是HBase重点要关注的内容,如果感兴趣,可以自行学习。
大家都是写代码,为啥他拿3万月薪,我只能拿1万?代码的性能和质量体现了这种差异。
HBase性能调优分几个方面来说。
影响Hadoop和HBase性能的关键因素可能是正在使用的交换设备。项目初期过早地做出(设备选型的)决定,可能会在后续集群规模翻倍的时候埋下隐患。
充分考虑这几点:
在CAP里,HBase默认是CP模型,即支持强一致性和分区容错性,不保证可用性。当开启多region的时候,它是AP模型,支持可用性和分区容错性,不支持强一致性。
Java方面的调优就一点:尽量避免full GC,用行话说,这种情况将stop the world,整个世界都安静了,等它垃圾回收。
配置项很多,参考HBase参数配置
HBase为什么这么快?因为它合理利用了内存,并且批量写入磁盘,用顺序写来代替随机写,这是它性能优异的原因。下一篇我们来介绍LSM树,这是它采用的存储形式。
标签:32位 慢慢 性能调优 option sage 过滤 ons 为什么 序列化
原文地址:https://www.cnblogs.com/burningblade/p/13999193.html