标签:左右 位置 poi 时间 参数 32位 loading init success
这是CMU 15-213的Malloc Lab,本来没打算做,被同学安利了一波~
需要用C实现A Dynamic Storage Allocator,类似于libc中的malloc/free/realloc,整体来看难度较大。
开始没什么思路,看了下CSAPP动态内存分配那一节。
内存的划分是这样子的:
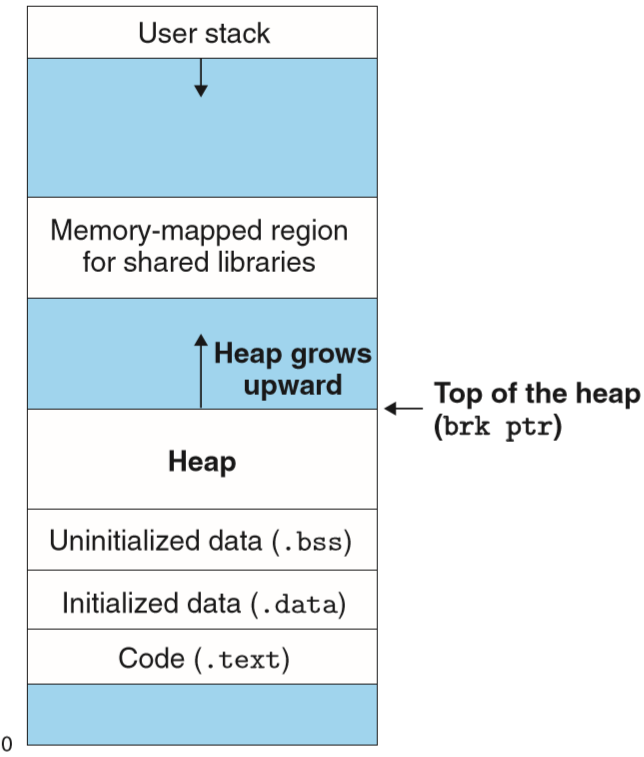
运行时分配的虚拟内存主要是Heap,Allocator将堆视作不同size的块,Allocator有2种:
malloc/freemalloc返回的对齐地址取决于编译环境,32位是8的倍数,64位是16的倍数;malloc不会初始化申请的内存,calloc会初始化内存为0。
堆的增长是通过增加内核的brk指针来增加/减小堆:
void *sbrk(intptr_t incr); // success: old brk pointer; error: -1
如果free的是一个非法指针,那么结果未定义。
主要实现在mm.c中,有4个主要函数:
int mm_init(void);
void *mm_malloc(size_t size);
void mm_free(void *ptr);
void *mm_realloc(void *ptr, size_t size);
mm_init负责初始化,比如分配初始的堆空间,成功返回0,失败返回-1;
mm_malloc负责分配指定大小的空间,但是这个空间必须在已经初始化的堆里,不能与其他空间冲突;返回的指针按照8B对齐,与libc中实现的malloc类似,最后会有一个PK;
mm_realloc负责:
ptr为NULL,等价于void *mm_malloc(size)mm_free(ptr)ptr不为NULL,把ptr所指的内存块增加/减小到size个字节,返回新地址(可能与原来的块相同,也可能不同,取决于实现方式、原块里内碎片的数量以及请求size的大小),保持原块的内容不变(如果申请变大,剩下的空间是未初始化的;如果申请变小,那么只保留size大小的原块内容)memlib.c为我们的分配器模拟了内存系统,可以调用里面的一些函数:
void *mem_sbrk(int incr): 将堆扩展incrB,参数是正整数,返回新分配的内存首地址;
void *mem_heap_lo(void): 返回堆的首地址;
void *mem_heap_hi(void): 返回堆的最后一个字节的地址;
size_t mem_heapsize(void): 返回当前堆的大小;
size_t mem_pagesize(void): 返回系统页面大小。
首先明确设计约束条件:
再明确设计目标:
吞吐量最大化:单位时间处理的请求,分配复杂度\(O(n)\),n是空闲块的数目,释放复杂度\(O(1)\);
内存利用率最大化:用peak utilization衡量,假设有\(n\)个请求:\(R_0, R_1, ... R_k, ..., R_{n-1}\),在\(R_k\)完成后,将aggregate payload(申请的字节总数)记作\(P_k\),当前的堆的大小记作\(H_k\)(单调不减),单调不减的条件可以通过使\(H_k\)为high-water mark来松弛,这样堆就可以上下都增长。那么peak utilization为:
我们的目标是最大化\(U_{n-1}\)。
这两目标是需要trade-off的,吞吐量越大,意味着需要减小操作的时间,往往就不能花费时间去处理碎片;内存利用率越大,意味着要精心处理分配和回收的块,自然需要更多的时间。
具体来说,有以下几点:

这些关键细节的设计非常重要,再BB一次:程序架构、数据结构和接口设计是一门艺术!
free只给一个指针,怎么知道要释放多少空间:记录每一块的大小;sbrk向内核申请更多的内存,插入空闲链表;不仅需要记录每块的大小,还需要区分已分配块和空闲块,所以block的格式可以设计如下:
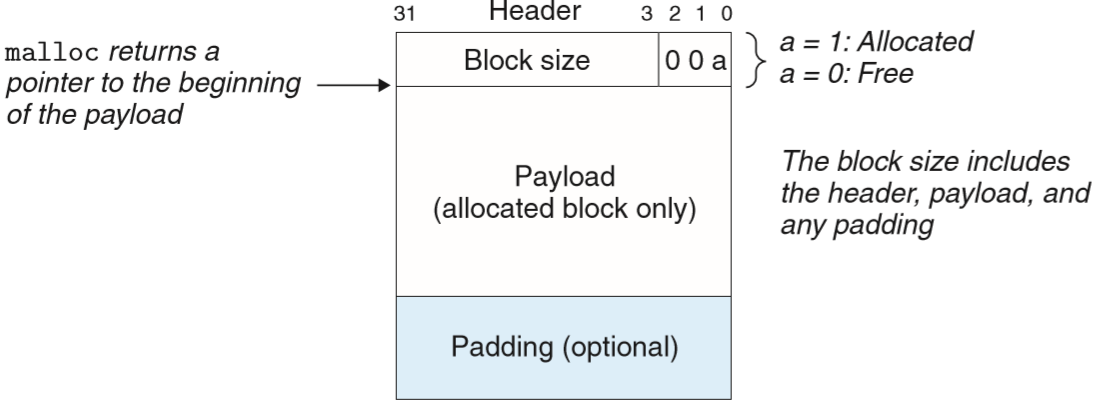
如果要求double-word(8B)对齐,那么Block size总是8的倍数,所以低3位都是0,可以利用其存储分配状态。
这样整个堆就可以组织为连续的分配和空闲块,由于已经存储了每块的大小,所以隐式空闲链表就应运而生:

隐式链表可以在\(O(1)\)的时间里合并之后的空闲块,但是要合并之前的空闲块,需要\(O(n)\)的时间扫描整个堆,这显然无法接受。Knuth大佬提出了boundary tags,这样实际上相当于隐式双向链表:
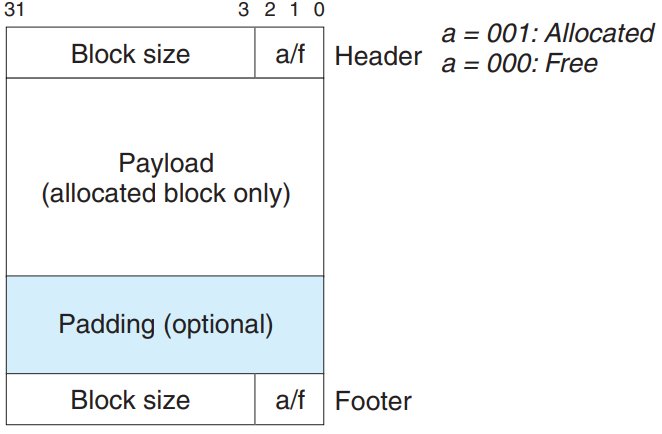
这样就可以通过Footer在\(O(1)\)检查之前的块的状态及其开始位置,缺点在于如果小的内存块比较多的话,内存开销太大。
双向tag带来的内存开销可以优化:只有前面的块是空闲,才需要它footer里的大小,所以可以在每个块用后3位里的某一位来存储前面块的状态,那么已分配块就不需要footer了,可以把footer的空间用来当作payload,但是空闲块仍然需要2个tag。
那么现在整个堆变成了这样:
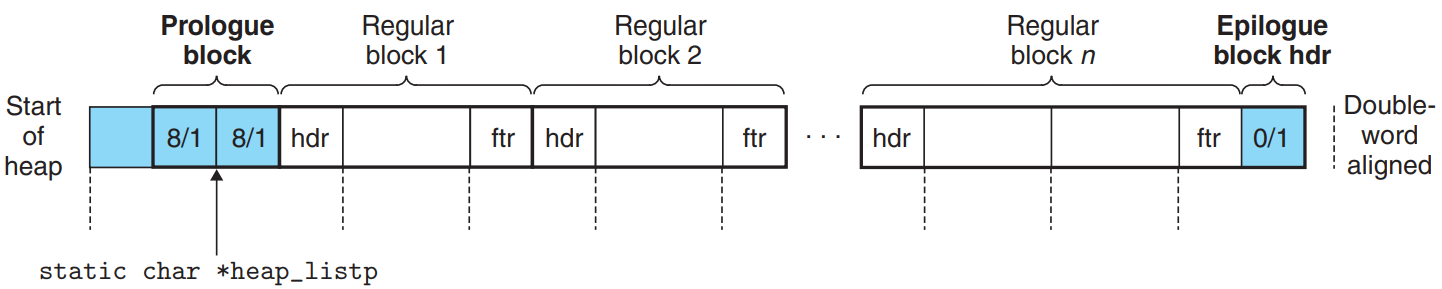
这里的heap_listp指向Prologue block的中间是做了一些小优化,方便直接定位到下一块的数据位置。
这里的实现非常tricky和subtle,一开始只申请了4words,unused(1)+Prologue(2)+Epilogue(1),后续的extend_heap申请一个空闲块后,将原来的Epilogue作为空闲块的header,空闲块的最后一个word变为新的Epilogue。
由于对齐要求(Headers在非对齐位置,Payloads对齐),分配器应该有一个minimum block size,即使只请求了1B,也要分配minimum block size,这里是16B。
写代码时先实现并测试malloc和free,如果能正确并且高效执行,再去实现realloc。
性能主要考虑2方面因素:
mm_malloc/mm_realloc但是还没有mm_free)与分配器使用的堆容量的比值,需要用好的策略减小碎片,使得该值接近1;评测程序会综合考虑2个方面,计算一个performance index
\(T_{libc}\)是libc中的malloc的吞吐量,大概在600Kops/s左右,\(w=0.6\)。
这个\(P\)既考虑了内存资源,又考虑了CPU资源,两个矛盾的指标需要适当权衡。
第一个版本mm1.c基本就是抄书,Implicit Free Lists+First Fit+Bi Boundary Tag,抄书也就将将及格。。
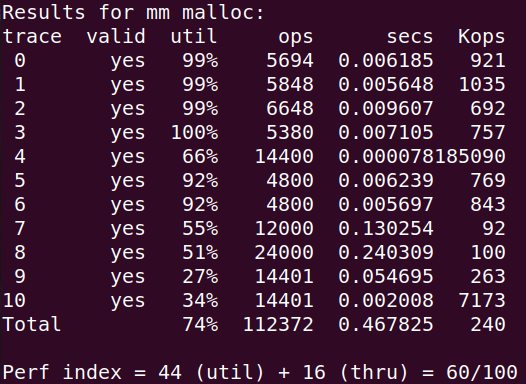
将First-Fit改成Next-Fit,还不错:
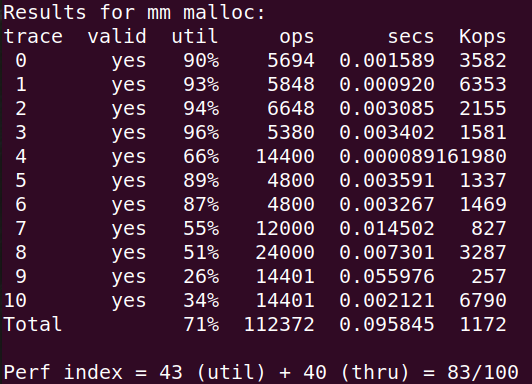
可以看到:Next-Fit在速度上有很大提升,主要是因为它是从上次终止的块开始搜索,避免了前面很多块的无效搜索。
最后对于Implicit Lists的性能做个总结:
分配:\(O(n)\)
释放:\(O(1)\)
Memory Overhead:取决于First Fit等策略
感觉这个性能已经不错了,但是一些无聊的计算机科学家还是不满意分配时的效率。接着我们看下更加????的方法Segregated Free Lists:
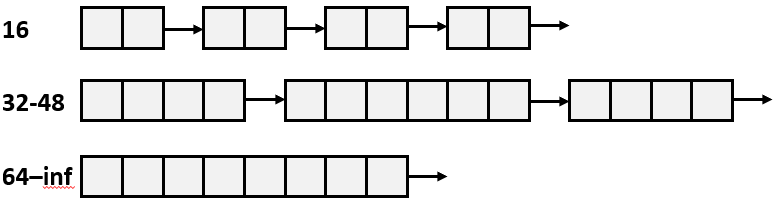
每个size级别的块都有自己的free list,分配大小为n的块时:
释放时合并空闲块并且放入相应的free list即可。
这实际上近似模拟了Best Fit,而且不用搜索整个free list,Best Fit一般有着最优的内存利用率,但是运行时间\(O(n)\),又是吞吐量和内存利用率的trade-off,终于明白了为什么官方的malloc要用这个方式了:吞吐量更大\(O(lgn)\)、更优的内存利用率Best Fit。
Segregated Free Lists中的空闲块包含Header+prev+next+padding+Footer,已分配块没有前后指针。
写代码要注意:整个堆中的块位置是不变的,只是状态(分配、释放)在改变,整个堆中的空闲块是用seg list的方式串起来的。
Debug可以自己写一下mm_check,还是很有用的。
realloc快de疯了,整整一个晚上。。。其实就4种情况:
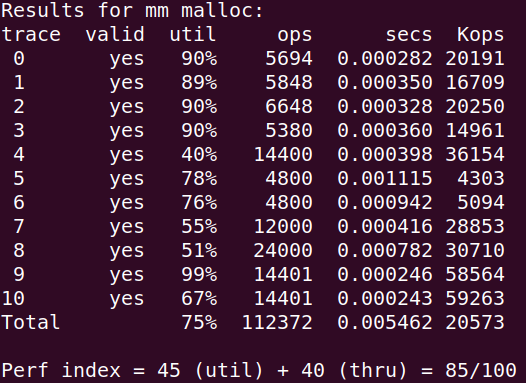
第一次写完,只有85,内存利用率太差了:
place的时候,如果申请块比较大,我们将其分配到后半部分,将前半部分切割为空闲:

之前class的划分是1,2-3,4-7,8-15...
但是最小块是16B,所以16B以下的用不到,所以改为16-31,32-63,64-127,128-255...
这样优化后直接96:
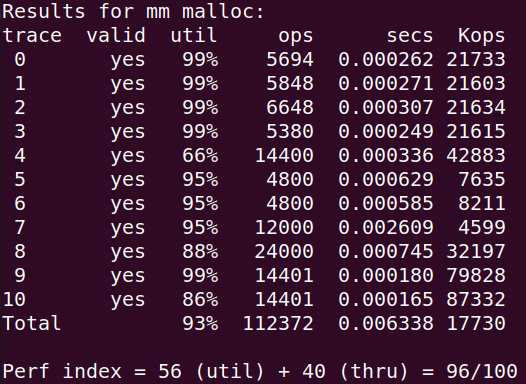
后面还可以继续优化榨干性能,比如去掉已分配块的Footer,realloc组合块以后对remainder进行split...
以后有时间再说......
标签:左右 位置 poi 时间 参数 32位 loading init success
原文地址:https://www.cnblogs.com/EIMadrigal/p/14051740.html