标签:str 集群 cin row asp png 输出 rdd 实现
设计Spark程式过程中最初始的是创建RDD数据集,该数据集来自定义的源数据,当RDD数据集初始后,再通过算子对RDD数据集作转换生成后续的数据集。Spark中提供了多种创建RDD数据集的方法,比如:通过内存集合创建、或使用本地文件创建以及HDFS文件创建RDD数据集。最常见的是第三种方式,生产环境下通常会读取并基于HDFS上存储的数据来创建并进行离线批处理。典型的RDD创建流程为,通过输入算子(如textFile或parallelize)从HDFS等数据源创建RDD分区,之后通过变换算子(如flatMap)定义数据计算与缓存逻辑,最后通过触发行动算子(如Action)执行整个操作。
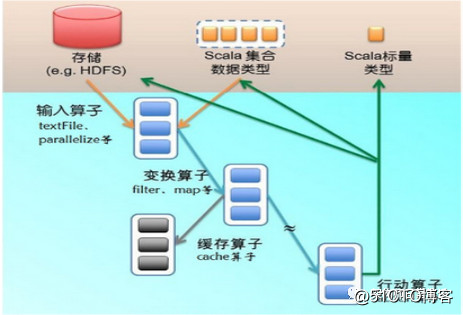
图1:RDD的创建与执行
由于RDD是分布式部署,因此通常会使用并行化方式创建RDD数据集。启动并行化可以通过调用SparkContext上下文中的parallelize方法(输入算子)实现,它会将数据源中的数据复制到集群各个节点中,形成RDD数据分区,如下代码演示创建并执行RDD的整个流程:
public class ParallelizeMath {
publicstatic void main(String[] args) {
//创建SparkConf定义运行环境
SparkConfconf = newSparkConf().
setAppName("ParallelizeMath").setMaster("local");
//创建SparkContext运行上下文
JavaSparkContextsc = new JavaSparkContext(conf);
//构造测试数据集合
Integer[]intArray = new Integer[] { 2, 3, 5, 7, 11, 13, 17, 19 };
//通过并行化创建RDD数据集,此处第二个参数2为指定切分的RDD分区数
JavaRDD<Integer>intRdd = sc.parallelize(Arrays.asList(intArray), 2);
//定义reduce变换算子,对测试集进行累加计算
intresult = intRdd.reduce(
new Function2<Integer, Integer, Integer>() {
privatestatic final long serialVersionUID = 1L;
@Override
publicInteger call(Integer e1, Integer e2)
throws Exception {
returne1 + e2;
}
});
//输出计算结果
System.out.println("Result:" + result);
//关闭SparkContext上下文
sc.close();
}
}上面的示例代码中,调用parallelize方法时通过传入参数来指定将输入源数据切分成对应分区,在每个分区上将运行相应的task进行数据处理。一般分区数与CPU关系密切,根据官方建议可以将分区数设置为:CPU数量2或CPU数量4。如果不做要求,则系统默认情况下会根据集群整体状况来自行设置分区数。
RDD的数据来源可以是多种多样的,比如HDFS、HBASE等,也可以是本地文件。比如通过SparkContext.textFile方法能够从本地或HDFS上读取数据并创建RDD集合。Spark默认为HDFS文件的每个Block创建对应分区或通过textFile方法入参指定分区数,但该指定的参数必须大于Block数。
标签:str 集群 cin row asp png 输出 rdd 实现
原文地址:https://blog.51cto.com/15015181/2556611