标签:read code metrics rev 介绍 中间 case || amp
温馨提示:本文基于 Kafka 2.2.1 版本。本文主要是以源码的手段一步一步探究消息发送流程,如果对源码不感兴趣,可以直接跳到文末查看消息发送流程图与消息发送本地缓存存储结构图。
从上文 初识 Kafka Producer 生产者,可以通过 KafkaProducer 的 send 方法发送消息,send 方法的声明如下:
Future<RecordMetadata> send(ProducerRecord<K, V> record)
Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback)从上面的 API 可以得知,用户在使用 KafkaProducer 发送消息时,首先需要将待发送的消息封装成 ProducerRecord,返回的是一个 Future 对象,典型的 Future 设计模式。在发送时也可以指定一个 Callable 接口用来执行消息发送的回调。
我们在学习消息发送流程之前先来看一下用于封装一条消息的 ProducerRecord 的类图,先来认识一下 kafka 是如何对一条消息进行抽象的。

我们首先来看一下 ProducerRecord 的核心属性,即构成 消息的6大核心要素:
在了解 ProducerRecord 后我们开始来探讨 Kafka 的消息发送流程。
KafkaProducer 的 send 方法,并不会直接向 broker 发送消息,kafka 将消息发送异步化,即分解成两个步骤,send 方法的职责是将消息追加到内存中(分区的缓存队列中),然后会由专门的 Send 线程异步将缓存中的消息批量发送到 Kafka Broker 中。
消息追加入口为 KafkaProducer#send
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
// intercept the record, which can be potentially modified; this method does not throw exceptions
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record); // @1
return doSend(interceptedRecord, callback); // @2
}代码@1:首先执行消息发送拦截器,拦截器通过 interceptor.classes 指定,类型为 List< String >,每一个元素为拦截器的全类路径限定名。
代码@2:执行 doSend 方法,后续我们需要留意一下 Callback 的调用时机。
接下来我们来看 doSend 方法。
KafkaProducer#doSend
ClusterAndWaitTime clusterAndWaitTime;
try {
clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), maxBlockTimeMs);
} catch (KafkaException e) {
if (metadata.isClosed())
throw new KafkaException("Producer closed while send in progress", e);
throw e;
}
long remainingWaitMs = Math.max(0, maxBlockTimeMs - clusterAndWaitTime.waitedOnMetadataMs);Step1:获取 topic 的分区列表,如果本地没有该topic的分区信息,则需要向远端 broker 获取,该方法会返回拉取元数据所耗费的时间。在消息发送时的最大等待时间时会扣除该部分损耗的时间。
温馨提示:本文不打算对该方法进行深入学习,后续会有专门的文章来分析 Kafka 元数据的同步机制,类似于专门介绍 RocketMQ 的 Nameserver 类似。
KafkaProducer#doSend
byte[] serializedKey;
try {
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
} catch (ClassCastException cce) {
throw new SerializationException("Can‘t convert key of class " + record.key().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() +
" specified in key.serializer", cce);
}Step2:序列化 key。注意:序列化方法虽然有传入 topic、Headers 这两个属性,但参与序列化的只是 key 。
KafkaProducer#doSend
byte[] serializedValue;
try {
serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
} catch (ClassCastException cce) {
throw new SerializationException("Can‘t convert value of class " + record.value().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() +
" specified in value.serializer", cce);
}Step3:对消息体内容进行序列化。
KafkaProducer#doSend
int partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);Step4:根据分区负载算法计算本次消息发送该发往的分区。其默认实现类为 DefaultPartitioner,路由算法如下:
setReadOnly(record.headers());
Header[] headers = record.headers().toArray();Step5:如果是消息头信息(RecordHeaders),则设置为只读。
KafkaProducer#doSend
int serializedSize = AbstractRecords.estimateSizeInBytesUpperBound(apiVersions.maxUsableProduceMagic(),
compressionType, serializedKey, serializedValue, headers);
ensureValidRecordSize(serializedSize);Step5:根据使用的版本号,按照消息协议来计算消息的长度,并是否超过指定长度,如果超过则抛出异常。
KafkaProducer#doSend
long timestamp = record.timestamp() == null ? time.milliseconds() : record.timestamp();
log.trace("Sending record {} with callback {} to topic {} partition {}", record, callback, record.topic(), partition);
Callback interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);Step6:先初始化消息时间戳,并对传入的 Callable(回调函数) 加入到拦截器链中。
KafkaProducer#doSend
if (transactionManager != null && transactionManager.isTransactional())
transactionManager.maybeAddPartitionToTransaction(tp);Step7:如果事务处理器不为空,执行事务管理相关的,本节不考虑事务消息相关的实现细节,后续估计会有对应的文章进行解析。
KafkaProducer#doSend
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey, serializedValue, headers, interceptCallback, remainingWaitMs);
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
this.sender.wakeup();
}
return result.future;Step8:将消息追加到缓存区,这将是本文重点需要探讨的。如果当前缓存区已写满或创建了一个新的缓存区,则唤醒 Sender(消息发送线程),将缓存区中的消息发送到 broker 服务器,最终返回 future。这里是经典的 Future 设计模式,从这里也能得知,doSend 方法执行完成后,此时消息还不一定成功发送到 broker。
KafkaProducer#doSend
} catch (ApiException e) {
log.debug("Exception occurred during message send:", e);
if (callback != null)
callback.onCompletion(null, e);
this.errors.record();
this.interceptors.onSendError(record, tp, e);
return new FutureFailure(e);
} catch (InterruptedException e) {
this.errors.record();
this.interceptors.onSendError(record, tp, e);
throw new InterruptException(e);
} catch (BufferExhaustedException e) {
this.errors.record();
this.metrics.sensor("buffer-exhausted-records").record();
this.interceptors.onSendError(record, tp, e);
throw e;
} catch (KafkaException e) {
this.errors.record();
this.interceptors.onSendError(record, tp, e);
throw e;
} catch (Exception e) {
// we notify interceptor about all exceptions, since onSend is called before anything else in this method
this.interceptors.onSendError(record, tp, e);
throw e;
}Step9:针对各种异常,进行相关信息的收集。
接下来将重点介绍如何将消息追加到生产者的发送缓存区,其实现类为:RecordAccumulator。
RecordAccumulator#append
public RecordAppendResult append(TopicPartition tp,
long timestamp,
byte[] key,
byte[] value,
Header[] headers,
Callback callback,
long maxTimeToBlock) throws InterruptedException {在介绍该方法之前,我们首先来看一下该方法的参数。
RecordAccumulator#append
Deque<ProducerBatch> dq = getOrCreateDeque(tp);
synchronized (dq) {
if (closed)
throw new KafkaException("Producer closed while send in progress");
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq);
if (appendResult != null)
return appendResult;
}Step1:尝试根据 topic与分区在 kafka 中获取一个双端队列,如果不存在,则创建一个,然后调用 tryAppend 方法将消息追加到缓存中。Kafka 会为每一个 topic 的每一个分区创建一个消息缓存区,消息先追加到缓存中,然后消息发送 API 立即返回,然后由单独的线程 Sender 将缓存区中的消息定时发送到 broker 。这里的缓存区的实现使用的是 ArrayQeque。然后调用 tryAppend 方法尝试将消息追加到其缓存区,如果追加成功,则返回结果。
在讲解下一个流程之前,我们先来看一下 Kafka 双端队列的存储结构:

RecordAccumulator#append
int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(maxUsableMagic, compression, key, value, headers));
log.trace("Allocating a new {} byte message buffer for topic {} partition {}", size, tp.topic(), tp.partition());
buffer = free.allocate(size, maxTimeToBlock);Step2:如果第一步未追加成功,说明当前没有可用的 ProducerBatch,则需要创建一个 ProducerBatch,故先从 BufferPool 中申请 batch.size 的内存空间,为创建 ProducerBatch 做准备,如果由于 BufferPool 中未有剩余内存,则最多等待 maxTimeToBlock ,如果在指定时间内未申请到内存,则抛出异常。
RecordAccumulator#append
synchronized (dq) {
// Need to check if producer is closed again after grabbing the dequeue lock.
if (closed)
throw new KafkaException("Producer closed while send in progress");
// 省略部分代码
MemoryRecordsBuilder recordsBuilder = recordsBuilder(buffer, maxUsableMagic);
ProducerBatch batch = new ProducerBatch(tp, recordsBuilder, time.milliseconds());
FutureRecordMetadata future = Utils.notNull(batch.tryAppend(timestamp, key, value, headers, callback, time.milliseconds()));
dq.addLast(batch);
incomplete.add(batch);
// Don‘t deallocate this buffer in the finally block as it‘s being used in the record batch
buffer = null;
return new RecordAppendResult(future, dq.size() > 1 || batch.isFull(), true);
}Step3:创建一个新的批次 ProducerBatch,并将消息写入到该批次中,并返回追加结果,这里有如下几个关键点:
纵观 RecordAccumulator append 的流程,基本上就是从双端队列获取一个未填充完毕的 ProducerBatch(消息批次),然后尝试将其写入到该批次中(缓存、内存中),如果追加失败,则尝试创建一个新的 ProducerBatch 然后继续追加。
接下来我们继续探究如何向 ProducerBatch 中写入消息。
ProducerBatch #tryAppend
public FutureRecordMetadata tryAppend(long timestamp, byte[] key, byte[] value, Header[] headers, Callback callback, long now) {
if (!recordsBuilder.hasRoomFor(timestamp, key, value, headers)) { // @1
return null;
} else {
Long checksum = this.recordsBuilder.append(timestamp, key, value, headers); // @2
this.maxRecordSize = Math.max(this.maxRecordSize, AbstractRecords.estimateSizeInBytesUpperBound(magic(),
recordsBuilder.compressionType(), key, value, headers)); // @3
this.lastAppendTime = now; //
FutureRecordMetadata future = new FutureRecordMetadata(this.produceFuture, this.recordCount,
timestamp, checksum,
key == null ? -1 : key.length,
value == null ? -1 : value.length,
Time.SYSTEM); // @4
// we have to keep every future returned to the users in case the batch needs to be
// split to several new batches and resent.
thunks.add(new Thunk(callback, future)); // @5
this.recordCount++;
return future;
}
}代码@1:首先判断 ProducerBatch 是否还能容纳当前消息,如果剩余内存不足,将直接返回 null。如果返回 null ,会尝试再创建一个新的ProducerBatch。
代码@2:通过 MemoryRecordsBuilder 将消息写入按照 Kafka 消息格式写入到内存中,即写入到 在创建 ProducerBatch 时申请的 ByteBuffer 中。本文先不详细介绍 Kafka 各个版本的消息格式,后续会专门写一篇文章介绍 Kafka 各个版本的消息格式。
代码@3:更新 ProducerBatch 的 maxRecordSize、lastAppendTime 属性,分别表示该批次中最大的消息长度与最后一次追加消息的时间。
代码@4:构建 FutureRecordMetadata 对象,这里是典型的 Future模式,里面主要包含了该条消息对应的批次的 produceFuture、消息在该批消息的下标,key 的长度、消息体的长度以及当前的系统时间。
代码@5:将 callback 、本条消息的凭证(Future) 加入到该批次的 thunks 中,该集合存储了 一个批次中所有消息的发送回执。
流程执行到这里,KafkaProducer 的 send 方法就执行完毕了,返回给调用方的就是一个 FutureRecordMetadata 对象。
源码的阅读比较枯燥,接下来用一个流程图简单的阐述一下消息追加的关键要素,重点关注一下各个 Future。
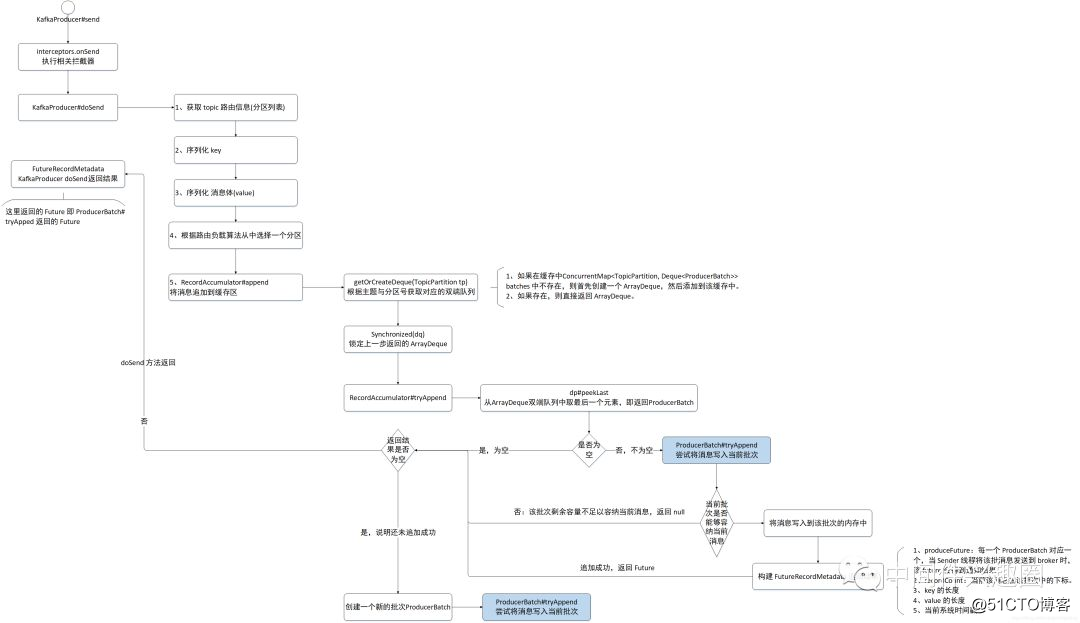
上面的消息发送,其实用消息追加来表达更加贴切,因为 Kafka 的 send 方法,并不会直接向 broker 发送消息,而是首先先追加到生产者的内存缓存中,其内存存储结构如下:ConcurrentMap< TopicPartition, Deque< ProducerBatch>> batches,那我们自然而然的可以得知,Kafka 的生产者为会每一个 topic 的每一个 分区单独维护一个队列,即 ArrayDeque,内部存放的元素为 ProducerBatch,即代表一个批次,即 Kafka 消息发送是按批发送的。其缓存结果图如下: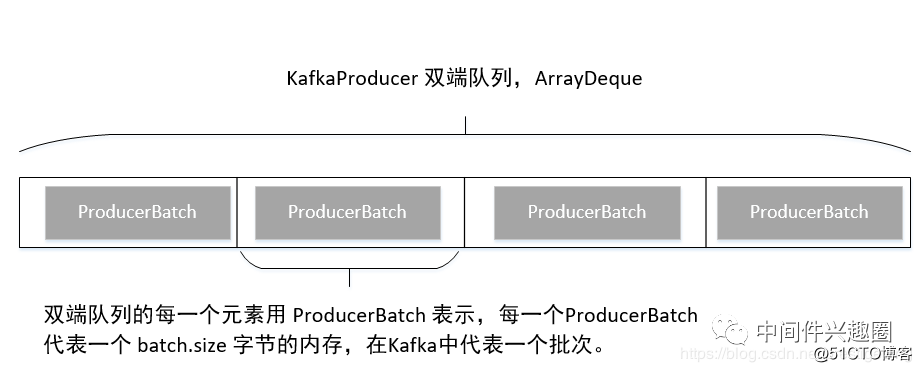
KafkaProducer 的 send 方法最终返回的 FutureRecordMetadata ,是 Future 的子类,即 Future 模式。那 kafka 的消息发送怎么实现异步发送、同步发送的呢?
其实答案也就蕴含在 send 方法的返回值,如果项目方需要使用同步发送的方式,只需要拿到 send 方法的返回结果后,调用其 get() 方法,此时如果消息还未发送到 Broker 上,该方法会被阻塞,等到 broker 返回消息发送结果后该方法会被唤醒并得到消息发送结果。如果需要异步发送,则建议使用 send(ProducerRecord< K, V > record, Callback callback),但不能调用 get 方法即可。Callback 会在收到 broker 的响应结果后被调用,并且支持拦截器。
消息追加流程就介绍到这里了,消息被追加到缓存区后,什么时候会被发送到 broker 端呢?将在下一篇文章中详细介绍。
如果文章对您有所帮助的话,麻烦帮忙点【在看】,谢谢您的认可与支持。
中间件兴趣圈已经陆续发表了源码分析Dubbo、ElasticJob、Mybatis、RocketMQ系列,RocketMQ实战与案例分析、ElasticSearch使用指南等。

标签:read code metrics rev 介绍 中间 case || amp
原文地址:https://blog.51cto.com/15023237/2558919