标签:open htm mongod 第三方库 ide not xxx lambda 符号
如何使用 Flupy 构建数据处理管道
摄影:产品经理
厨师:kingname
经常使用 Linux 的同学,肯定对|这个符号不陌生,这个符号是 Linux 的管道符号,可以把左边的数据传递给右边。
例如我有一个spider.log文件,我想查看里面包含"ERROR"关键词,同时时间为2019-11-23的数据,那么我可以这样写命令:
cat spider.log | grep ERROR | grep "2019-11-23"但是,如果你想执行更复杂的操作,例如提取关键词fail on: https://xxx.com后面的这个网址,然后对所有获得的网址进行去重,那么虽然 shell 命令也能办到,但写起来却稍显麻烦。
这个时候,你就可以使用 Flupy 来实现你的需求。首先我们使用 Python 3.6 以上的版本安装Flupy:
python3 -m pip install flupy然后开始写代码,看看这几步操作有多简单:
import re
from flupy import flu
with open(‘spider.log‘, encoding=‘utf-8‘) as f:
error_url = (flu(f).filter(lambda x: ‘ERROR‘ in x)
.map(lambda x: re.search(‘fail on: (.*?),‘, x))
.filter(lambda x: x is not None)
.map(lambda x: x.group(1))
.unique())
for url in error_url:
print(url)首先flu接收一个可迭代对象,无论是列表还是生成器都可以。然后对里面的每一条数据应用后面的规则。这个过程都是基于生成器实现的,所以不会有内存不足的问题,对于 PB 级别的数据也不在话下。
在上面的例子中,Flupy获取日志文件的每一行内容,首先使用filter进行过滤,只保留包含ERROR字符串的行。然后对这些行通过map方法执行正则表达式,搜索满足fail on: (.*?)\n的内容。由于有些行有,有些行没有,所以这一步返回的数据有些是 None,有些是正则表达式对象,所以进一步再使用filter关键字,把所有返回None的都过滤掉。然后继续使用map关键字,对每一个正则表达式对象获取.group(1)。并把结果输出。
运行效果如下图所示:
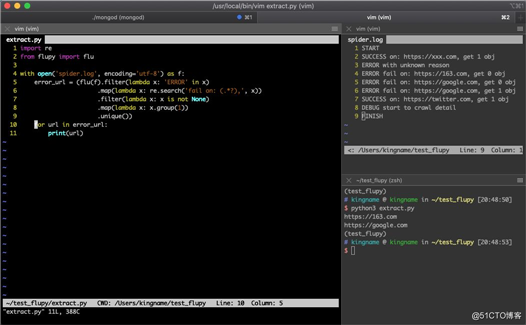
实现了数据的提取和去重。并且整个过程通过 Python 实现,代码也比 Shell 简单直观。
由于Flupy可以接收任何可迭代对象,所以传入数据库游标也是没有问题的,例如从 MongoDB 中读取数据并进行处理的一个例子:
import pymongo
from flupy import flu
handler = pymongo.MongoClient().db.col
cursor = handler.find()
data = flu(cursor).filter(lambda x: x[‘date‘] >= ‘2019-11-10‘).map(lambda x: x[‘text‘]).take_while(lambda x: ‘kingname‘ in x)这一段代码的意思是说,从数据库中一行一行检查数据,如果date字段大于2019-11-10就获取text字段的数据,满足一条就获取一条,直到某条数据包含kingname为止。
使用Flupy不仅可以通过写.py文件实现,还可以直接在命令行中执行,例如上面读取spider.log的代码,可以转换为终端命令:
flu -f spider.log "_.filter(lambda x: ‘ERROR‘ in x).map(lambda x: re.search(‘fail on: (.*?),‘, x)).filter(lambda x: x is not None).map(lambda x: x.group(1)).unique()" -i re运行效果如下图所示: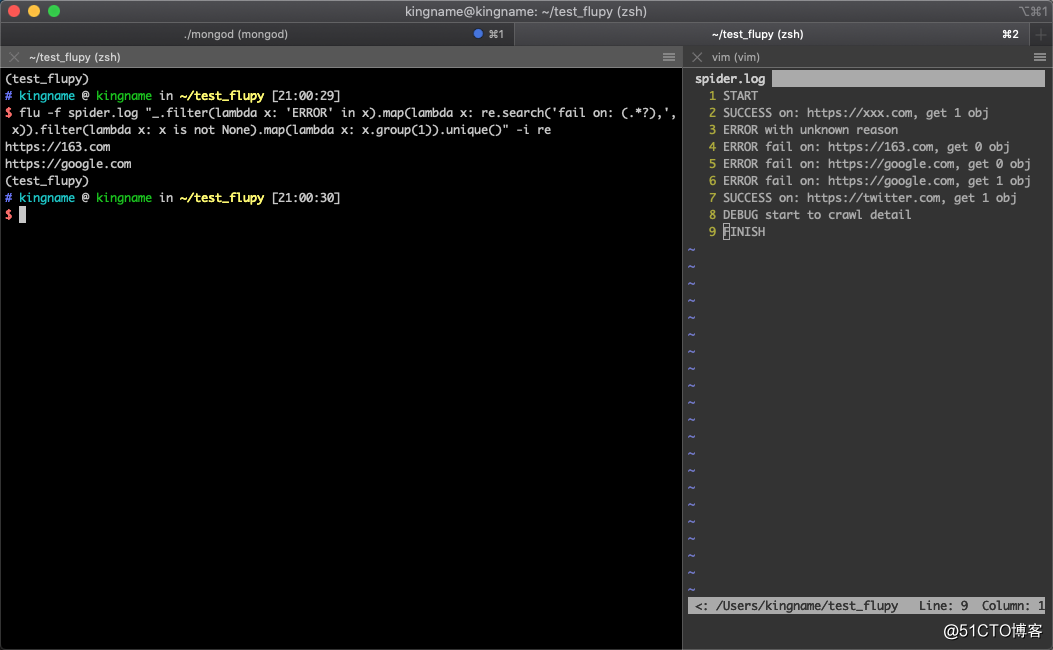
通过-i 参数导入不同的库,无论是系统自带的库或者第三方库都可以。
Flupy 的更多使用参数,可以参阅它的官方文档[1]
参考资料
[1]
官方文档: https://flupy.readthedocs.io/en/latest/welcome.html
标签:open htm mongod 第三方库 ide not xxx lambda 符号
原文地址:https://blog.51cto.com/15023263/2558910