标签:接收 info 必须 rpo tar range 使用方法 pop 没有
一日一技:如何从 Redis 的列表中一次性 pop 多条数据?
摄影:产品经理
产品经理说我炒的蛋炒饭比图中好吃
当我们想从 Redis 的列表里面持续弹出数据的时候,我们一般使用lpop或者rpop:
import redis
client = redis.Redis()
while True:
data = client.lpop(‘key‘)
if not data:
break
print(f‘弹出一条数据:{data.decode()}‘)但这种写法有一个问题,就是每弹出1条数据都要连接一次 Redis 服务器,当你要把1000万条数据从列表里面弹出来的时候,实际上超过一半的时间都消耗在了网络请求上面。
但是lpop与rpop都只接收一个参数,就是key。因此没有办法通过传入参数的方式让它一次弹出多条数据。
要获取多条数据,我们还有另一种方案,就是lrange:
client = client.lrange(‘key‘, 0, 5000)这一行的意思是从列表中,获取前5001条数据(包含首尾)。但lrange只能获取数据,却不能删除数据。这就会导致在多个进程获取到重复的数据。
我们还知道Redis 的ltrim来删除数据:
client.ltrim(‘key‘, 5000, -1)这样就能删除前5000条数据了。这里第三个参数之所以要用负数,是因为ltrim(key, start, end)的意思是说,保留列表 Key 的第start项到第end 项,其它项删除。那么如果 end为负数,表示倒数第几项,例如-1表示倒数第1项,-2表示倒数第2项。假设列表里面有10000项,那么 start 为5000,end 为-1,表示删除前5000条数据(0-4999),保留后面的。
于是有人问,能不能这样写代码呢:
import redis
client = redis.Redis()
data = client.lrange(‘key‘, 0, 4999)
client.ltrim(‘key‘, 5000, -1)这样不就看起来像是弹出了5000条数据吗?
想法很好,但是由于获取数据与删除数据是两条命令,中间有时间差。这就导致在多个线程或者进程同时执行这两条代码的时候,出现竞争。也就是进程1刚刚获取了前5000条数据,然后进程2同样获取这5000条数据,然后进程1删除前5000条数据,然后进程2再删除5000条数据。
这样一来,两个进程获取了相同的5000条数据,但是却删了10000条数据。
为了解决这个问题,必须让获取数据与删除数据这两个操作变成一个“原子操作”。所谓的原子操作就是只一个最小的操作单位,它不会被中途打断。
要解决这个问题,我们就需要使用 Redis 的pipeline功能。它可以把多条命令放在一个网络请求中发送到服务器,并默认在一个事务中执行这些命令。一个事务是不会被打断的,从事务开始然后执行里面的多个命令到结束的整个过程,可以看做一个原子操作。
pipeline的使用方法如下:
import redis
client = redis.Redis()
def batch_lpop(key, n):
p = client.pipeline()
p.lrange(key, 0, n - 1)
p.ltrim(key, n, -1)
data = p.execute()
return data
batch_lpop(‘test_pipeline‘, 20)当代码执行到p.execute()的时候,它才会真正去连接服务器,然后把待执行的命令在一个事务中一次性执行完成。并返回一个列表。返回的列表有两项,第0项是包含结果的列表,第1项为ltrim 的返回结果。如下图所示:
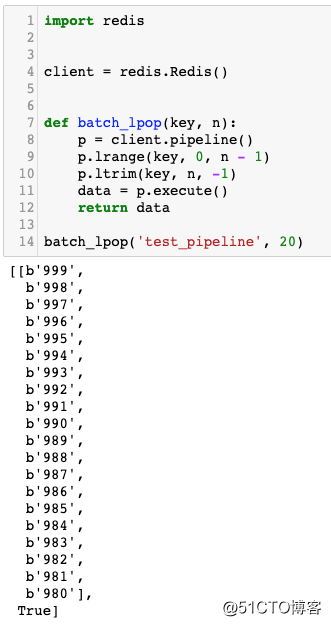
我们只需要使用第0项的结果即可。
一日一技:如何从 Redis 的列表中一次性 pop 多条数据?
标签:接收 info 必须 rpo tar range 使用方法 pop 没有
原文地址:https://blog.51cto.com/15023263/2558898