标签:http import from 技术 使用方法 筛选 python too 就是
一日一技:从列表中一次性筛选多个指定位置的数据
Pandas的DataFrame在筛选列数据的时候,有一个非常方便的用法。
假设现在有这样一个DataFrame:
import pandas as pd
data = [
{‘name‘: ‘kingname‘, ‘age‘: 20, ‘salary‘: 99999},
{‘name‘: ‘alice‘, ‘age‘: 30, ‘salary‘: 99999},
{‘name‘: ‘bob‘, ‘age‘: 10, ‘salary‘: 99999},
{‘name‘: ‘cindy‘, ‘age‘: 40, ‘salary‘: 99999}
]
df = pd.DataFrame(data)
df运行效果如下图所示: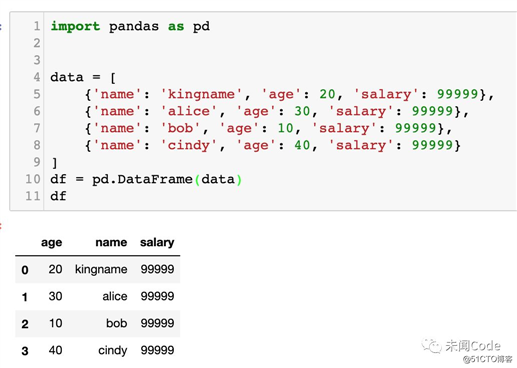
我要筛选所有 age>=30的数据,可以这样写:
df[df[‘age‘] >= 30]运行效果如下图所示: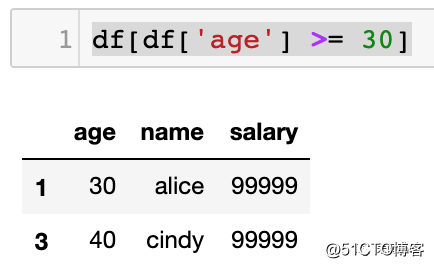
而这里面的原理,实际上可以使用下面这个代码来解释:
df[[False, True, False, True]]如下图所示: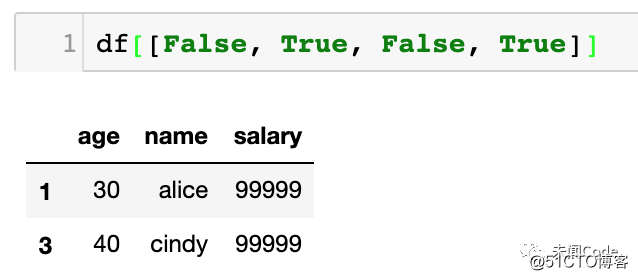
那么问题来了,我有一个Python里面,列表能不能也实现这个功能呢?假设有下面两个列表:
name_list = [‘kingname‘, ‘alice‘, ‘bob‘, ‘cindy‘]
position_list = [True, False, True, False]我想把 position_list列表中, True的下标在 name_list中对应的值都获取下来。
你可能会这样写代码:
name_list = [‘kingname‘, ‘alice‘, ‘bob‘, ‘cindy‘]
position_list = [True, False, True, False]
for name, position in zip(name_list, position_list):
if position:
print(name)运行效果如下图所示: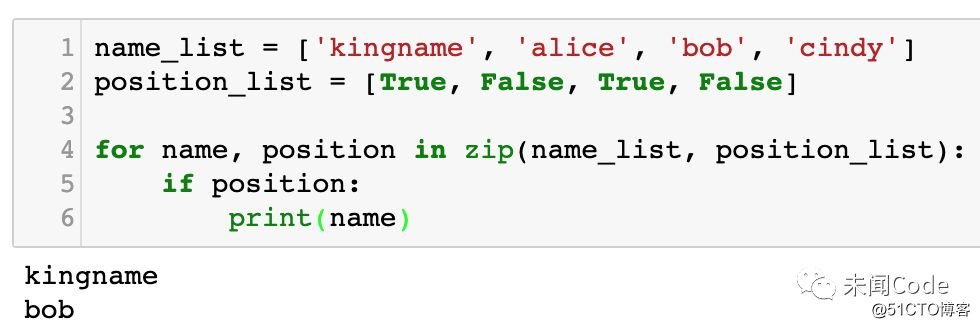
但实际上,在Python里面有一个现成的函数可以实现这个功能,那就是 itertools.compress(),其使用方法如下:
from itertools import compress
name_list = [‘kingname‘, ‘alice‘, ‘bob‘, ‘cindy‘]
position_list = [True, False, True, False]
for name in compress(name_list, position_list):
print(name)运行效果如下图所示: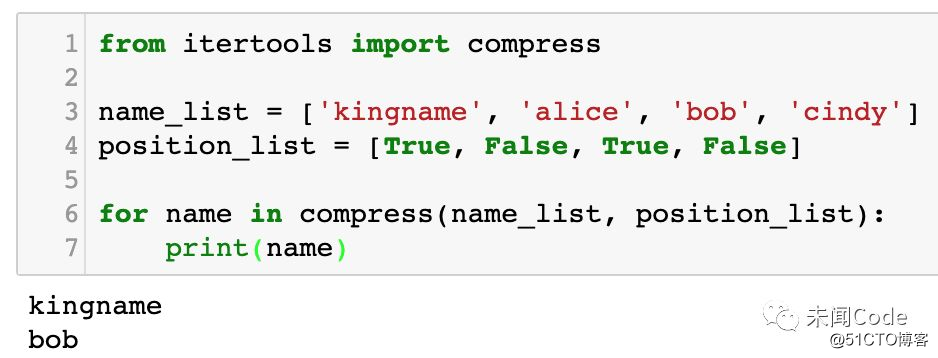
kingname
攒钱给产品经理买房。
标签:http import from 技术 使用方法 筛选 python too 就是
原文地址:https://blog.51cto.com/15023263/2559300