标签:inf 寻址 替代 一起 作用 逻辑 百度搜索 重构 内容
位运算这个概念并不陌生,大多数程序员在进入这个领域的时候或多或少都接触过位运算,估计当时都写过不少练习题的。位运算本身不难,困难的是大家没有学会在系统设计时用上它,提高系统性能,增加你的不可替代性。
就不做太多铺垫了,直接说下今天讲述的干货内容:
位运算使用场景
面试经常问
比如我曾经在面试腾讯的时候
?
O(1) 时间如何检测整数 n 是否是 2 的幂次?
?
在看一道Google面试题:
?
有64瓶药,其中63瓶是无毒的,一瓶是有毒的。如果做实验的小白鼠喝了有毒的药,3天后会死掉,当然喝了其它的药,包括同时喝几种就没事。现在只剩下3天时间,请问最少需要多少只小白鼠才能试出那瓶药有毒?
?
这就不用龙su啰嗦了吧,稳稳的都是和位运算有关的。
类似面试题目还有很多,一个不注意就会被撂倒。
这部分的题目整体难度不大,本身不是一个很大的知识点,但是「很容易被大家忽略」,今天龙su就拿出来好好说说,大家可要记住喔,不然...

系统设计经常用
喜欢看源码的同学就会注意到,经常在里面看到这样的代码。
「lucene源码」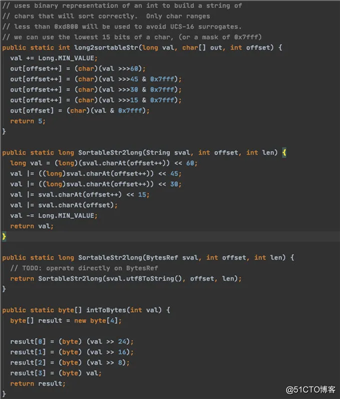
「redis源码」
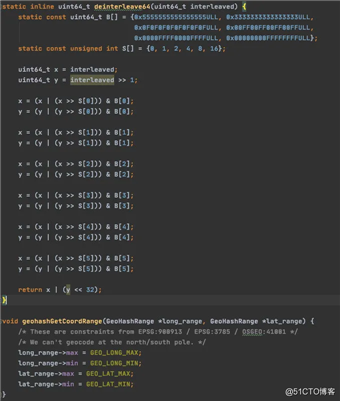
「龙叔的源码」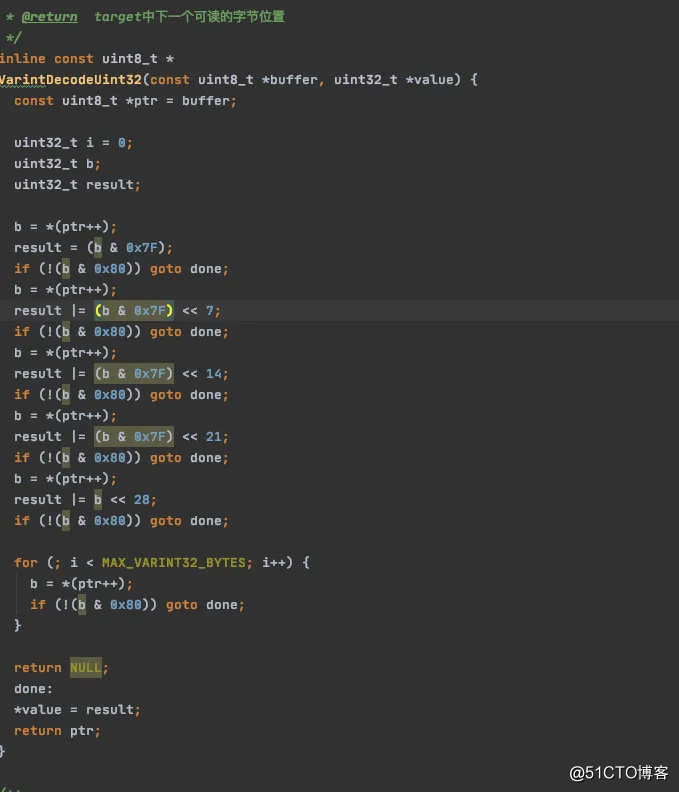
有没有发现这些代码惊人的相似,「好的设计总是这样不谋而合」。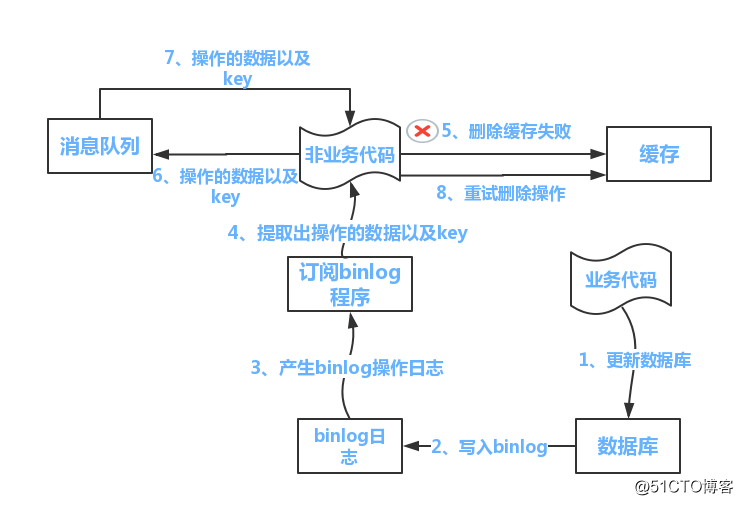
看了这么多,想必大家已经知道这东西还是有些作用的,应该好好搞清楚他的原理。接下来就一起来盘他。
位运算原理
「位」 指的是比特位(bit),不是byte,所以位运算指的就是比特位计算。
CPU所有计算都是二进制的计算,一个高性能的服务一定是把CPU资源利用到极致,也就是用最少资源换取最大收益。
当然随着现代CPU的计算速度不断加快,很多人在设计系统的时候完全不会去考虑这些性能点,然而真正的高并发系统都是极致性能的。
看看我们日常开发都是啥样的,只要不涉及到「高并发」,开发代码就算是一坨屎,也没关系,大多数人都是在这坨屎上继续CRUD,也就会变成了一大坨。
没办法,老板只看结果,懒得管你的代码是什么样的。哎呀,好像暴露了龙叔是个CRUD菜鸡选手。
等到有一天发现加机器加到扛不住了,这时候就是「最幸运」的一批程序员诞生的时候,必须开始重构系统。为什么最幸运,大家都知道了吧?机会不是天天有的,这就是千载难逢的良机啊。
哈,好像有点说远了。
在计算机世界里,万物皆0、1,0、1生万物。万物到0、1的过程叫做编码。
一个数在计算机中的二进制表示形式, 叫做这个数的机器数。机器数是带符号的,在计算机中用一个数的最高位存放符号, 正数为0, 负数为1。
计算机中对数字的编码表示有三种方式:「原码」,「反码」,「补码」:
「原码」:原码表示法在数值前面增加了一位符号位(即最高位为符号位):正数该位为0,负数该位为1。比如十进制3如果用8个二进制位来表示就是 00000011, -3就是 10000011。
「反码」:反码表示方法:正数的反码是其本身;负数的反码是在其原码的基础上,符号位不变,其余各个位取反。
「补码」:补码表示方法:正数的补码是其本身;负数的补码是在其原码的基础上,符号位不变,其余各位取反,最后+1。(即在反码的基础上+1)
这三种是编码方式,但是在计算机系统中,数值一律用补码来表示(存储)。
举个例子:
2. 1. 10
原码 反码 补码
00001010 --> 00001010 --> 00001010
2. -15
10001111 --> 11110000 --> 11110001 说完了数据编码,基本已经知道一个数据是怎么存储在计算机中的,接下来就看看数据比特位之间是如何计算的。
各种编程语言都提供了对补码的二进制位直接进行运算的方法,即「位运算」。
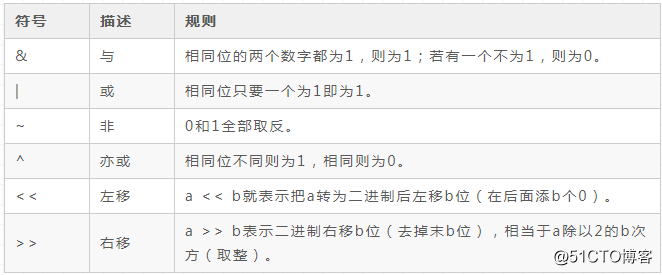
举几个例子
10 & -15 = 00001010 & 11110001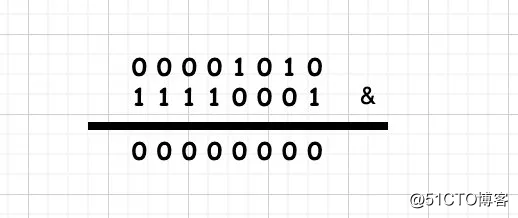
按位进行相与,相同为1则为1,否则为0,最终算的结果为00000000 即0
10 & 15 = 00001010 & 00001111
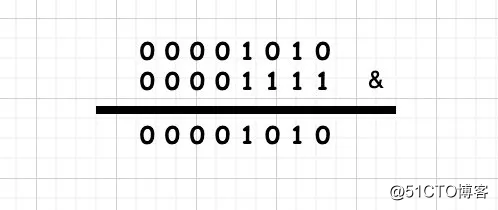
按位进行相与,相同为1则为1,否则为0,最终算的结果为00001010 即10
10 | 15 = 00001010 | 00001111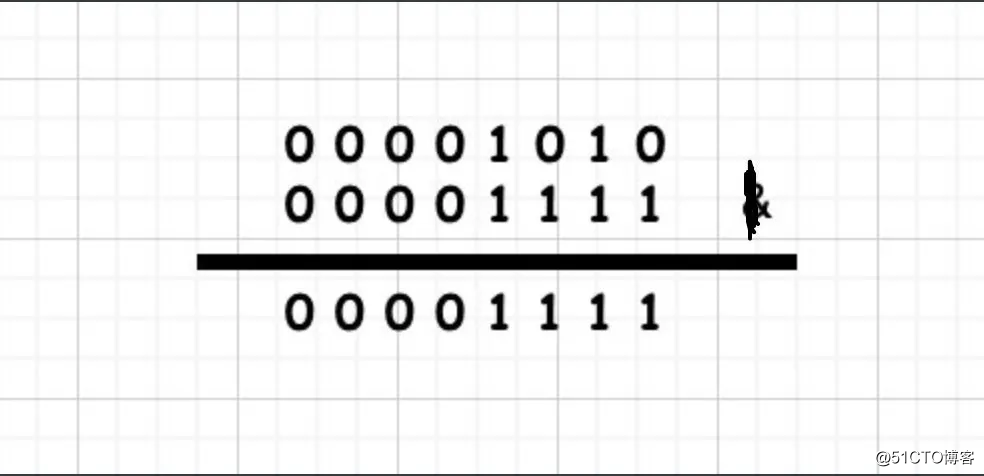
按位进行或逻辑,相同位只要一个为1即为1 ,00001111即15
15>>2
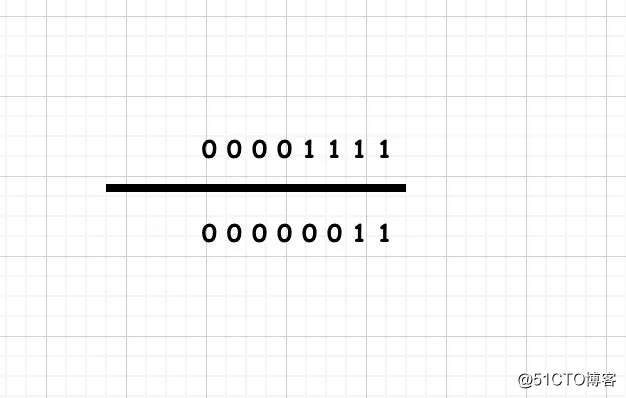
二进制右移2位,左边填符号号位,右边抹掉,得到00000011 即3
15<<2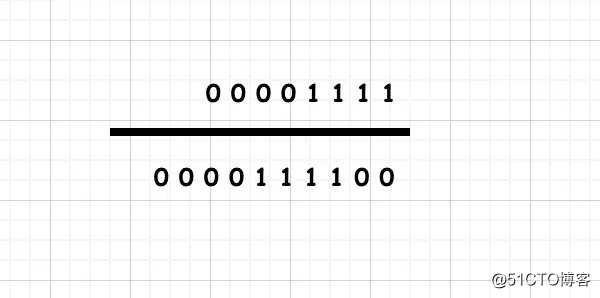
二进制左移2位,左边抹掉,符号位不变,右边填0,得到00111100
原理还是比较简单,主要就是对比特位进行逻辑操作。
位运算为什么那么快?
看到这里其实大多数人已经明白为什么位运算快了,但暖心的龙叔还是在啰嗦下原因,就算是锦上添花(画蛇添足)了。
存储更友好,比特位存储,不用转换后在存储
CPU更友好,直接比特位操作,减少机器数到比特位的转换
寻址次数更少,左移一位就乘2
说一个搜索里面位运算带来的性能提升
比如你在百度搜索 「广东富婆」 ,分词会分为 「广东」 「富婆」 两个词,分别从两个倒排中召回,假设 「广东」 这个词召回了100w个doc,「富婆」 召回了1000W个。
此时两个doc链会进行一个合并,合并的返回结果是存在广东的同时又要存在富婆的doc。
这个合并如果是通过比特位的方式操作的话,一个64位的CPU一个「指令周期」可以处理64个doc,如果采用普通合并的话,一次只能合并一个doc,这个性能提升很明显的吧,是不是感觉高性能有点意思了。
像这种性能上的提升,是无法通过增「加机器」解决的。
总结
这次内容不难,讲出来是希望大家在做系统设计时,性能考虑不是简单的加机器,而是真的把CPU价值最大化。
小改动、大效果,一些小的改动,会对性能提升产生很多的效果。反正我这次设计时基本把一些计算都改为了位运算。
我是龙叔,一个在互联网大器晚成的设计师,我们下期见。喜欢我,记得「关注」我。
标签:inf 寻址 替代 一起 作用 逻辑 百度搜索 重构 内容
原文地址:https://blog.51cto.com/13449864/2560634