标签:eve 重点 数据库 callback serve 简单 table 重复 head

Canal是阿里巴巴开源的数据库Binlog日志解析框架,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。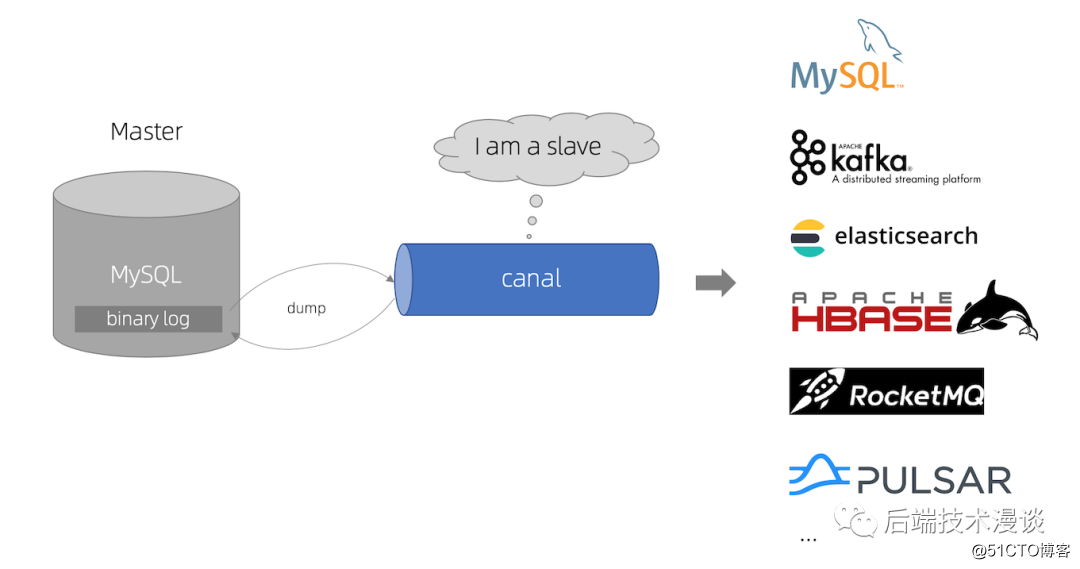
在之前我写的文章阿里开源MySQL中间件Canal快速入门中,我已经介绍了Canal的基本原理和基础使用。
在部署到生产环境的过程中,自己作为一个菜鸟,又踩了一些坑,期间做了记录和总结,并再解决后分析了下原因,便有了此文。
Canal常见的三大问题原因分析及解决方案
这个问题主要由以下几种典型情况:
MySQL在进行主从同步时,会使用Binlog,从库读取Binlog来进行数据的同步。但是Binlog是有三种不同的运行模式的,分别是ROW模式、Statement模式和Mix模式。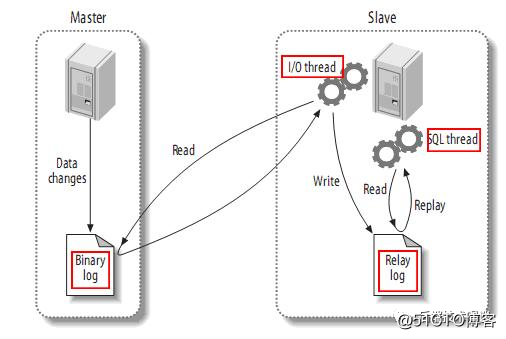
「1. ROW模式」
Binlog日志中仅记录哪一条记录被修改了,修改成什么样了,会非常清楚的记录下每一行数据修改的细节,「Master修改了哪些行,slave也直接修改对应行的数据」
?
优点:row的日志内容会非常清楚的记录下每一行数据修改的细节,非常容易理解。而且不会出现某些特定情况下的存储过程和function,以及trigger的调用和出发无法被正确复制问题。
缺点:在row模式下,所有的执行的语句当记录到日志中的时候,都将以每行记录的修改来记录,这样可能会产生大量的日志内容。
?「2. Statement模式」
每一条会修改数据的sql都会记录到master的binlog中,「slave在复制的时候sql进程会解析成和原来master端执行相同的sql再执行。」
?
优点:在statement模式下首先就是解决了row模式的缺点,不需要记录每一行数据的变化减少了binlog日志量,节省了I/O以及存储资源,提高性能。因为他只需要记录在master上所执行的语句的细节以及执行语句的上下文信息。
缺点:在statement模式下,由于他是记录的执行语句,所以,为了让这些语句在slave端也能正确执行,那么他还必须记录每条语句在执行的时候的一些相关信息,也就是上下文信息,以保证所有语句在slave端被执行的时候能够得到和在master端执行时候相同的结果。另外就是,由于mysql现在发展比较快,很多的新功能不断的加入,使mysql的复制遇到了不小的挑战,自然复制的时候涉及到越复杂的内容,bug也就越容易出现。在statement中,目前已经发现不少情况会造成Mysql的复制出现问题,主要是修改数据的时候使用了某些特定的函数或者功能的时候会出现,比如:sleep()函数在有些版本中就不能被正确复制,在存储过程中使用了last_insert_id()函数,可能会使slave和master上得到不一致的id等等。由于row是基于每一行来记录的变化,所以不会出现,类似的问题。
?「3. Mix模式」
?
从官方文档中看到,之前的 MySQL 一直都只有基于 statement 的复制模式,直到 5.1.5 版本的 MySQL 才开始支持 row 复制。从 5.0 开始,MySQL 的复制已经解决了大量老版本中出现的无法正确复制的问题。但是由于存储过程的出现,给 MySQL Replication 又带来了更大的新挑战。
另外,看到官方文档说,从 5.1.8 版本开始,MySQL 提供了除 Statement 和 Row 之外的第三种复制模式:Mixed,实际上就是前两种模式的结合。
「在 Mixed 模式下,MySQL 会根据执行的每一条具体的 SQL 语句来区分对待记录的日志形式,也就是在 statement 和 row 之间选择一种。」
新版本中的 statment 还是和以前一样,仅仅记录执行的语句。而新版本的 MySQL 中对 row 模式也被做了优化,并不是所有的修改都会以 row 模式来记录,比如遇到表结构变更的时候就会以 statement 模式来记录,如果 SQL 语句确实就是 update 或者 delete 等修改数据的语句,那么还是会记录所有行的变更。
?说完了三种模式,下面就来看看在Canal中会带来的影响,「简单来说就是会造成Canal解析Query出现问题」。
我的客户端代码片段:
String tableName = header.getTableName();
String schemaName = header.getSchemaName();
RowChange rowChange = null;
try {
rowChange = RowChange.parseFrom(entry.getStoreValue());
} catch (InvalidProtocolBufferException e) {
LOGGER.error("解析数据变化出错", e);
}
EventType eventType = rowChange.getEventType();
LOGGER.info("当前正在操作表 {}.{} 执行操作 = {}", schemaName, tableName, eventType);运行后,可以看到输出: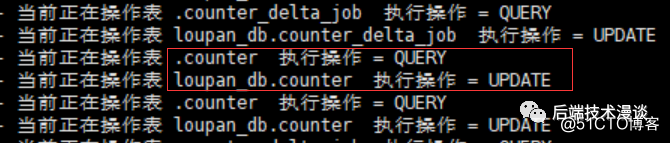
红框标出的部分,可以看出其实是一次操作,但是应该由于是Mix模式,canal解析成了两条消息,一次是QUERY,一次是UPDATE。
官方文档其实给出了解释:
https://github.com/alibaba/canal/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98%E8%A7%A3%E7%AD%94
?
问1:INSERT/UPDATE/DELETE被解析为Query或DDL语句?
答1:出现这类情况主要原因为收到的binlog就为Query事件,比如:
1. binlog格式为非row模式,通过show variables like ‘binlog_format‘可以查看. 针对statement/mixed模式,DML语句都会是以SQL语句存在
2. mysql5.6+之后,在binlog为row模式下,针对DML语句通过一个开关(binlog-rows-query-log-events=true, show variables里也可以看到该变量),记录DML的原始SQL,对应binlog事件为RowsQueryLogEvent,同时也有对应的row记录. ps. canal可以通过properties设置来过滤:canal.instance.filter.query.dml = true
?懂了问题出在Binlog后,其实这个问题也就不是太大,只是一开始让人很迷惑。
Canal提供了filter可以过滤掉不需要监听的表(黑名单),或者指定需要监听的表(白名单)。
我们通常在canal-server端的conf/example/instance.properties文件中进行设置:
# table regex
canal.instance.filter.regex=.*\\..*
# table black regex
canal.instance.filter.black.regex=设置规则方式为:
mysql 数据解析关注的表,Perl正则表达式.
多个正则之间以逗号(,)分隔,转义符需要双斜杠(\\)
常见例子:
1. 所有表:.* or .*\\..*
2. canal schema下所有表:canal\\..*
3. canal下的以canal打头的表:canal\\.canal.*
4. canal schema下的一张表:canal.test1
5. 多个规则组合使用:canal\\..*,mysql.test1,mysql.test2 (逗号分隔)也可以在客户端与canal进行连接时,用客户端的connector.subscribe("xxxxxxx");来覆盖服务端初始化时的设置。
Canal官方可能是收到的filter设置不成功的反馈有点多了,在canal1.1.3+版本之后,会在日志里记录最后使用的filter条件,可以对比使用的filter看看是否和自己期望的是一致:
c.a.o.canal.parse.inbound.mysql.dbsync.LogEventConvert - --> init table filter : ^.*\..*$
c.a.o.canal.parse.inbound.mysql.dbsync.LogEventConvert - --> init table black filter :如果失效,首先看下自己在客户端是不是调用过connector.subscribe("xxxxxxx");覆盖了服务端初始化时的设置。
Binlog如果不是row模式,filter会失效
?
过滤条件只针对row模式的数据有效(ps. mixed/statement因为不解析sql,所以无法准确提取tableName进行过滤)
?我上面截图中那种收到两条消息的情况,第一条消息就是一个QURTY,并且没法确定表名,所以没法开启过滤。
Canal现在的架构是单机消费,就算是高可用架构,为了保证binlog消费的顺序,依然是单机高可用,也就是在一台消费者挂了之后在其他待命的消费者中启动一台继续消费。(这个是目前版本我的理解,以后或许会有并发消费的新版本出来。)可以看下图: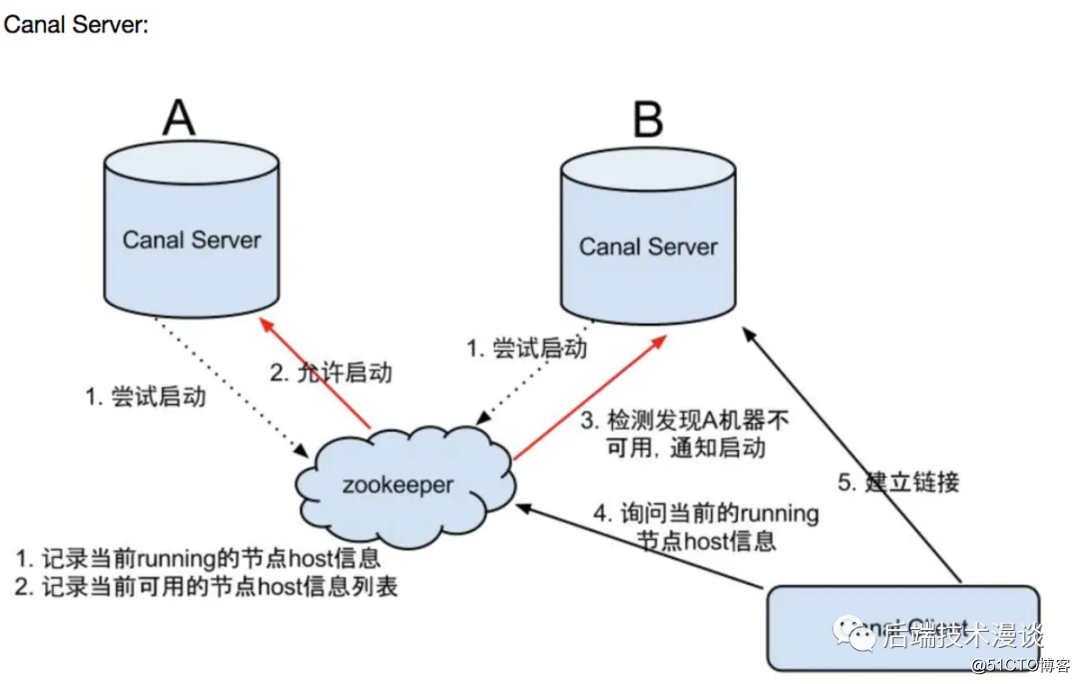
这种情况下,在Binlog数据量极大时,消费进程就有可能处理不过来。最后就会「体现在消费跟不上,进度滞后,甚至挂掉」。在Canal开源仓库的issues中你可以看到很多类似的问题报告:
https://github.com/alibaba/canal/issues/726
我在部署完Canal后,在遇到数据库写入高峰期,就遇到了数据延迟问题。数据延迟还是小事,但是一旦延迟到堆满了内存缓冲区,不消费的话,新的消息就进不来了。
进一步分析这个问题,Canal整体架构如下图: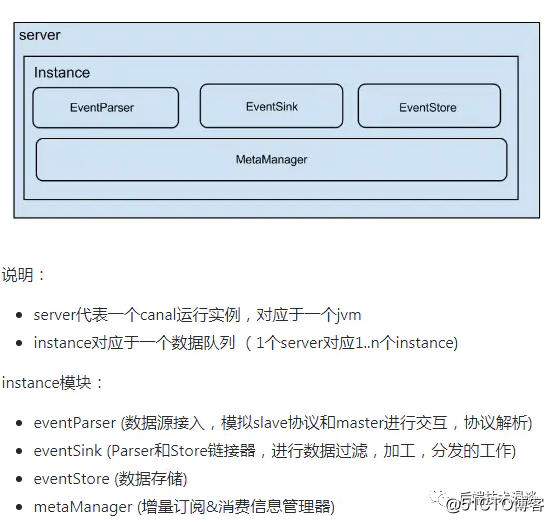
而在消息的存储设计中,Canal使用了RingBuffer,架构如下图:
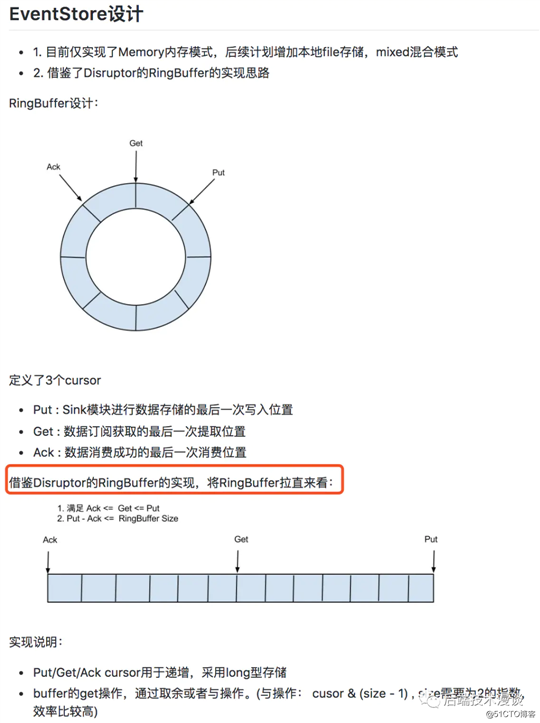
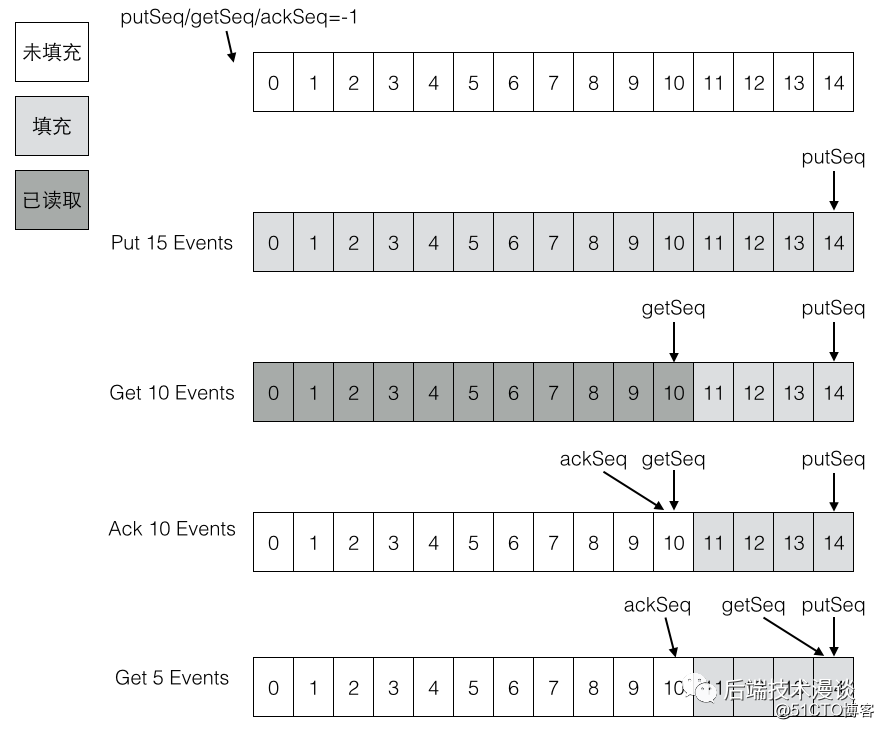
「可以看到,现在Canal是在内存中来缓存消息的,并不会对数据进行持久化,而且缓存空间大小肯定是固定的,所以就会存在一直不提交确认ACK,导致内存缓存被占满的情况。」
下面贴几个看到的写的比较好的对于Canal消费堆积分析的文字,并贴出原文链接:
https://zqhxuyuan.github.io/2017/10/10/Midd-canal/
?
这里假设环形缓冲区的最大大小为15个(源码中是16MB),那么上面两批一共产生了15个元素,刚好填满了环形缓冲区。如果又有Put事件进来,由于环形缓冲区已经满了,没有可用的slot,则Put操作会被阻塞,直到被消费掉。
?https://blog.csdn.net/zhanlanmg/article/details/51213631
?
查看canal源码,为了寻找canal是否进行了文件持久化,大致上是没有的,只有一个发现就是会有临时的存储,存储接口CanalEventStore,CanalServerWithEmbedded.getWithoutAck()方法。继续~真正处理数据是在AbstractEventParser类,它会开启线程持续向master提交复制请求,直到有数据流过时,会调用EventTransactionBuffer的add(CanalEntry.Entry entry)方法,然后是put,可以看到put方法里面,会把数据放在内存缓存起来,当缓存满了以后会flush,而这个flush会调用TransactionFlushCallback接口的flush实现,这个接口在AbstractEventParser类里面有一个匿名实现,它会把数据处理掉,在consumeTheEventAndProfilingIfNecessary方法中会调用sink方法,它会一直调用到entryEventSink.doSink(Listevents)方法,这里面证实了,如果缓存区已经满了,那么会等待,等待,直到有空位放。所以当缓存区满了以后会阻塞。这就是为什么canal的数据走了很多之后,如果一直不对它ack那么就不会再有新的数据过来了的原因。另外,由于测试方法的问题,导致昨天的描述不正确,并不是插入和更新有区别,而是我的操作问题,因为我的操作是批量更新和单条插入,而缓存的大小取决于获取数据的条数(就是一次master到slave的dump是一条数据),而不是因为数据量的原因。
?「一个可行的解决办法是,将消息拉取后,写入消息队列(如RabbitMQ/Kafka),用消息队列来堆积消息处理,来保证大量消息堆积后不会导致canal卡死,并且可以支持数据持久化。」
「我自己对Canal这样做的的猜测:Canal应该想是让专业的工具做专业的事,Canal就只是一个读取Binlog的中间件,并不是专业的消息队列,消息应该让专业的消息队列来处理。」
Canal实际用起来,特别是好好读他的文档后,能感觉到还有许多问题和坑,还需要自己多多实践一下,调研一下,才知道什么是适合自身业务的。之后如果遇到更多Canal的坑,我还会持续记录下来。
我是一名后端开发工程师。主要关注后端开发,数据安全,爬虫,物联网,边缘计算等方向,欢迎交流。

个人公众号:后端技术漫谈
「如果文章对你有帮助,不妨收藏,转发,在看起来~」
标签:eve 重点 数据库 callback serve 简单 table 重复 head
原文地址:https://blog.51cto.com/15047490/2560629