标签:较差 沟通 转发 trigger 前言 调用 ali 理想 心跳包

顾名思义就是证明是否还活着的依据。
什么场景下需要心跳呢?
目前我们接触到的大多是一些基于长连接的应用需要心跳来“保活”。
由于在长连接的场景下,客户端和服务端并不是一直处于通信状态,如果双方长期没有沟通则双方都不清楚对方目前的状态;所以需要发送一段很小的报文告诉对方 “我还活着”。
同时还有另外几个目的:
服务端检测到某个客户端迟迟没有心跳过来可以主动关闭通道,让它下线。
客户端检测到某个服务端迟迟没有响应心跳也能重连获取一个新的连接。
正好借着在 cim有这样两个需求来聊一聊。
心跳实现方式
心跳其实有两种实现方式:
TCP 协议实现( keepalive 机制)。
由于 TCP 协议过于底层,对于开发者来说维护性、灵活度都比较差同时还依赖于操作系统。
所以我们这里所讨论的都是应用层的实现。
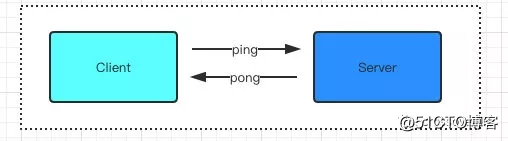
如上图所示,在应用层通常是由客户端发送一个心跳包 ping 到服务端,服务端收到后响应一个 pong 表明双方都活得好好的。
一旦其中一端延迟 N 个时间窗口没有收到消息则进行不同的处理。
客户端自动重连
先拿客户端来说吧,每隔一段时间客户端向服务端发送一个心跳包,同时收到服务端的响应。
常规的实现应当是:
开启一个定时任务,定期发送心跳包。
收到服务端响应后更新本地时间。
再有一个定时任务定期检测这个 “本地时间”是否超过阈值。
这样确实也能实现心跳,但并不友好。
在正常的客户端和服务端通信的情况下,定时任务依然会发送心跳包;这样就显得没有意义,有些多余。
所以理想的情况应当是客户端收到的写消息空闲时才发送这个心跳包去确认服务端是否健在。
好消息是 Netty 已经为我们考虑到了这点,自带了一个开箱即用的 IdleStateHandler 专门用于心跳处理。
来看看 cim 中的实现: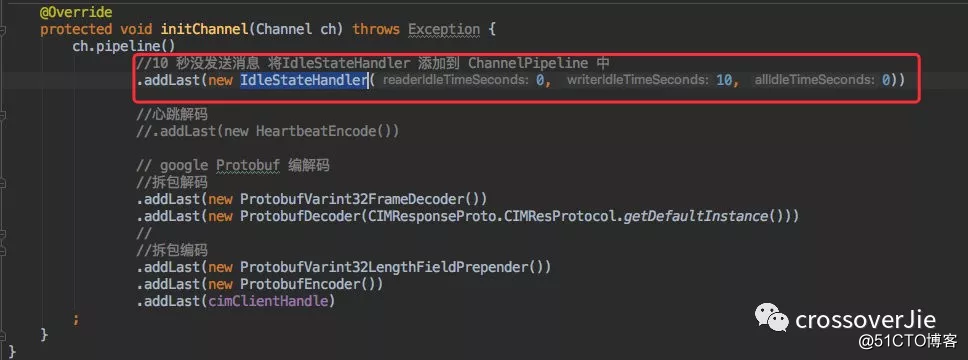
在 pipeline 中加入了一个 10秒没有收到写消息的 IdleStateHandler,到时他会回调 ChannelInboundHandler 中的 userEventTriggered 方法。
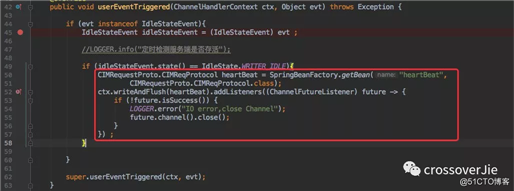
所以一旦写超时就立马向服务端发送一个心跳(做的更完善应当在心跳发送失败后有一定的重试次数);
这样也就只有在空闲时候才会发送心跳包。
但一旦间隔许久没有收到服务端响应进行重连的逻辑应当写在哪里呢?
先来看这个示例:
当收到服务端响应的 pong 消息时,就在当前 Channel 上记录一个时间,也就是说后续可以在定时任务中取出这个时间和当前时间的差额来判断是否超过阈值。
超过则重连。

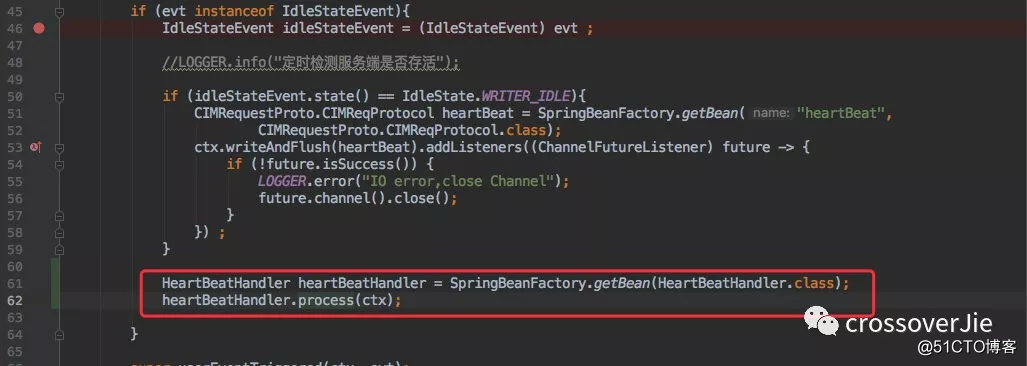
同时在每次心跳时候都用当前时间和之前服务端响应绑定到 Channel 上的时间相减判断是否需要重连即可。
也就是 heartBeatHandler.process(ctx); 的执行逻辑。
伪代码如下:
@Override
public
void
process
(
ChannelHandlerContext
ctx
)
throws
Exception
{
long
heartBeatTime
=
appConfiguration
.
getHeartBeatTime
()
*
1000
;
Long
lastReadTime
=
NettyAttrUtil
.
getReaderTime
(
ctx
.
channel
());
long
now
=
System
.
currentTimeMillis
();
if
(
lastReadTime
!=
null
&&
now
-
lastReadTime
>
heartBeatTime
){
reconnect
();
}
}IdleStateHandler 误区
一切看起来也没毛病,但实际上却没有这样实现重连逻辑。
最主要的问题还是对 IdleStateHandler 理解有误。
我们假设下面的场景:
客户端通过登录连上了服务端并保持长连接,一切正常的情况下双方各发心跳包保持连接。
这时服务端突入出现 down 机,那么理想情况下应当是客户端迟迟没有收到服务端的响应从而 userEventTriggered执行定时任务。
但却事与愿违,并不会执行 2、3两步。
因为一旦服务端 down 机、或者是与客户端的网络断开则会回调客户端的 channelInactive 事件。
IdleStateHandler 作为一个 ChannelInbound 也重写了 channelInactive() 方法。
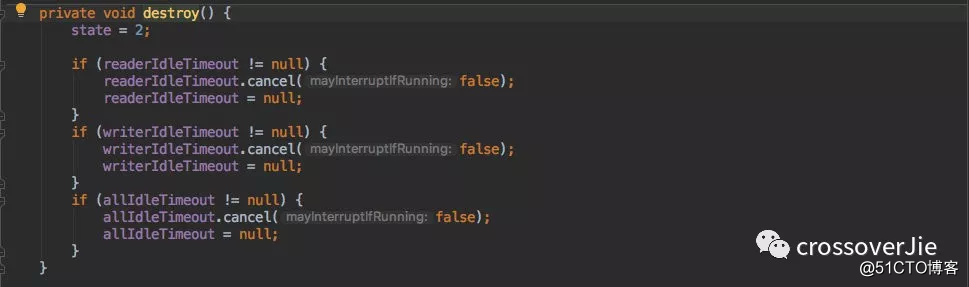
这里的 destroy() 方法会把之前开启的定时任务都给取消掉。
所以就不会再有任何的定时任务执行了,也就不会有机会执行这个重连业务。
靠谱实现
因此我们得有一个单独的线程来判断是否需要重连,不依赖于 IdleStateHandler。
于是 cim 在客户端感知到网络断开时就会开启一个定时任务:
之所以不在客户端启动就开启,是为了节省一点线程消耗。网络问题虽然不可避免,但在需要的时候开启更能节省资源。


在这个任务重其实就是执行了重连,限于篇幅具体代码就不贴了,感兴趣的可以自行查阅。
同时来验证一下效果。
启动两个服务端,再启动客户端连接上一台并保持长连接。这时突然手动关闭一台服务,客户端可以自动重连到可用的那台服务节点。


启动客户端后服务端也能收到正常的 ping 消息。
利用 :info 命令查看当前客户端的链接状态发现连的是 9000端口。

:info 是一个新增命令,可以查看一些客户端信息。
这时我关掉连接上的这台节点。
kill -9 2142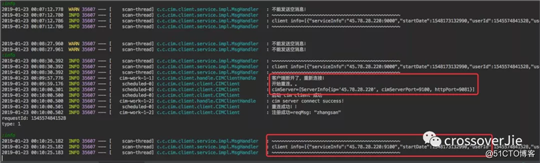

这时客户端会自动重连到可用的那台节点。
这个节点也收到了上线日志以及心跳包。
服务端自动剔除离线客户端
现在来看看服务端,它要实现的效果就是延迟 N 秒没有收到客户端的 ping 包则认为客户端下线了,在 cim的场景下就需要把他踢掉置于离线状态。
消息发送误区
这里依然有一个误区,在调用 ctx.writeAndFlush() 发送消息获取回调时。
其中是 isSuccess 并不能作为消息发送成功与否的标准。

也就是说即便是客户端直接断网,服务端这里发送消息后拿到的 success 依旧是 true。
这是因为这里的 success 只是告知我们消息写入了 TCP 缓冲区成功了而已。
和我之前有着一样错误理解的不在少数,这是 Netty 官方给的回复。
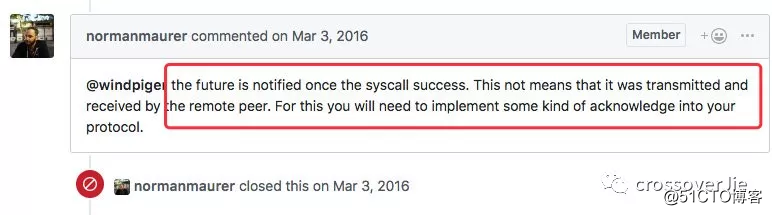
相关 issue:
https://github.com/netty/netty/issues/4915
同时感谢 95老徐以及闪电侠的一起排查。
所以我们不能依据此来关闭客户端的连接,而是要像上文一样判断 Channel 上绑定的时间与当前时间只差是否超过了阈值。
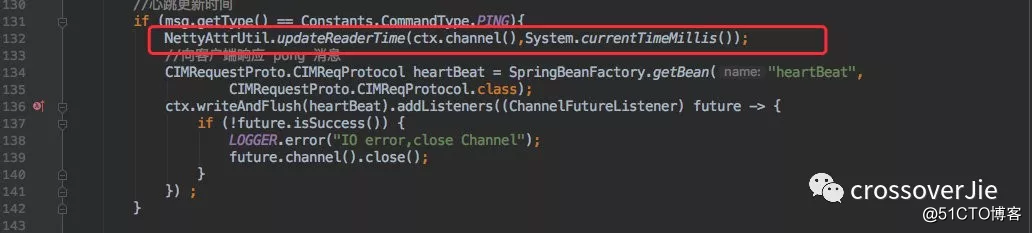
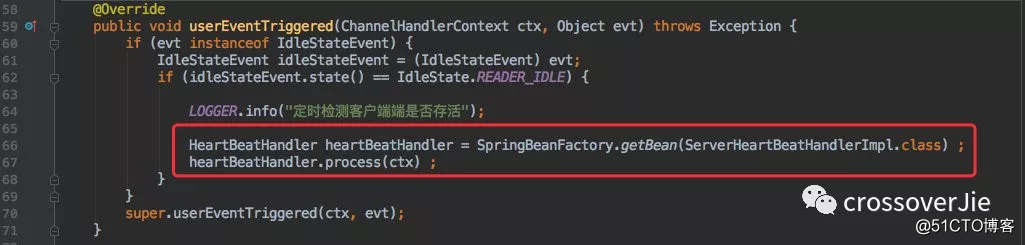
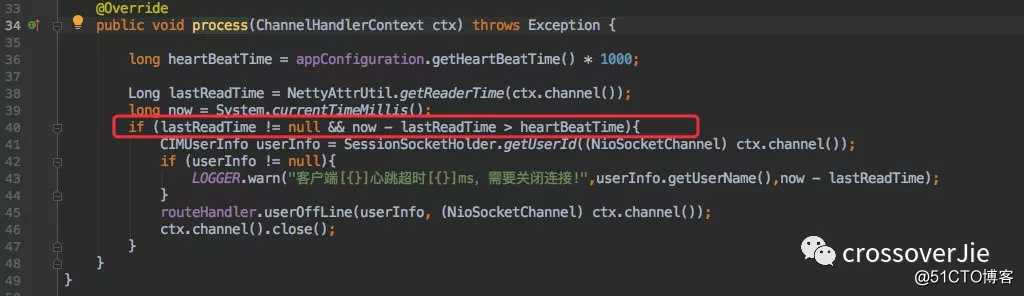
以上则是 cim 服务端的实现,逻辑和开头说的一致,也和 Dubbo 的心跳机制有些类似。
于是来做个试验:正常通信的客户端和服务端,当我把客户端直接断网时,服务端会自动剔除客户端。
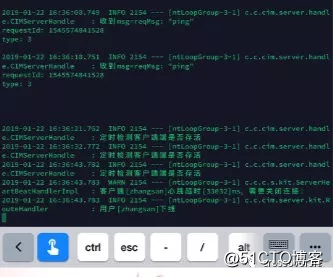
总结
这样就实现了文初的两个要求。
服务端检测到某个客户端迟迟没有心跳过来可以主动关闭通道,让它下线。
同时也踩了两个误区,坑一个人踩就可以了,希望看过本文的都有所收获避免踩坑。
本文所有相关代码都在此处,感兴趣的可以自行查看:
https://github.com/crossoverJie/cim
如果本文对你有所帮助还请不吝转发。
标签:较差 沟通 转发 trigger 前言 调用 ali 理想 心跳包
原文地址:https://blog.51cto.com/15049794/2562700