标签:限制 exec allocator nod ecs driver 资源管理 演示 erb

作者 | 柳密 阿里巴巴阿里云智能
本文整理自《Serverless 技术公开课》
导读:本节课主要介绍如何在 Serverless Kubernetes 集群中低成本运行 Spark 数据计算。首先简单介绍下阿里云 Serverless Kubernetes 和 弹性容器实例 ECI 这两款产品;然后介绍 Spark on Kubernetes;最后进行实际演示。
ECI 提供安全的 Serverless 容器运行服务。无需管理底层服务器,只需要提供打包好的 Docker 镜像,即可运行容器,并仅为容器实际运行消耗的资源付费。
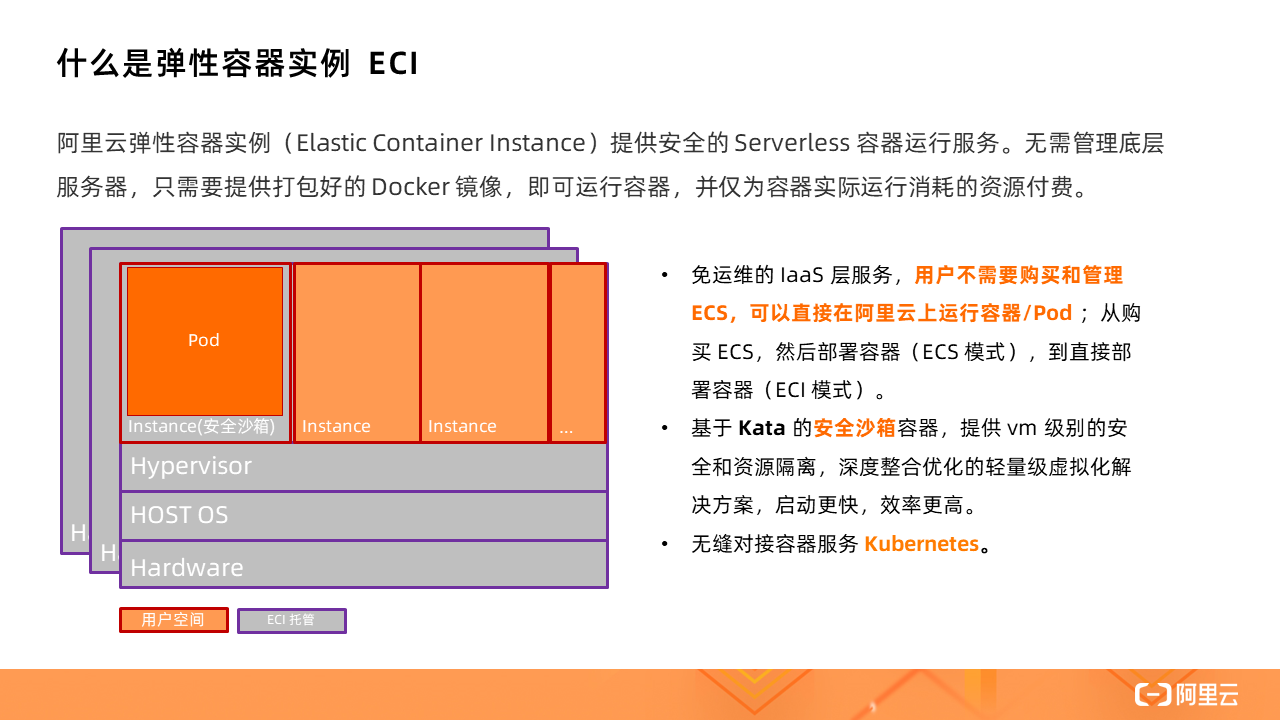
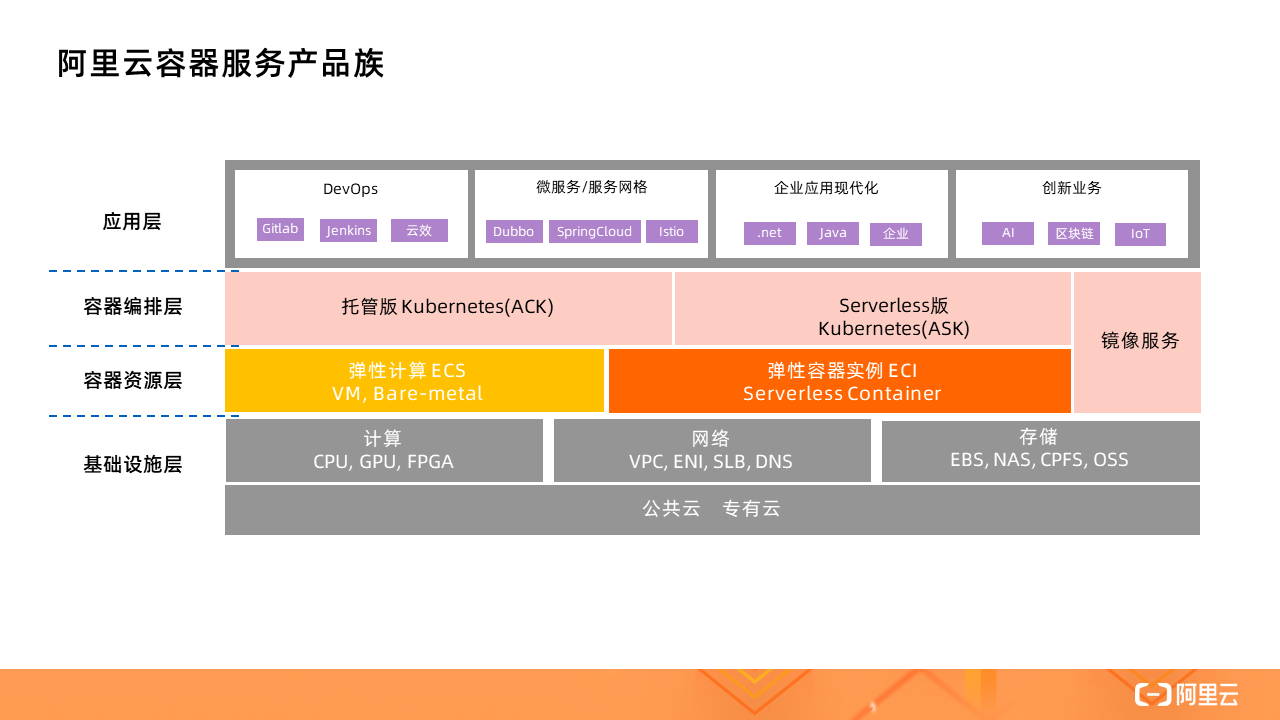
不论是托管版的 Kubernetes(ACK)还是 Serverless 版 Kubernetes(ASK),都可以使用 ECI 作为容器资源层,其背后的实现就是借助虚拟节点技术,通过一个叫做 Virtual Node 的虚拟节点对接 ECI。
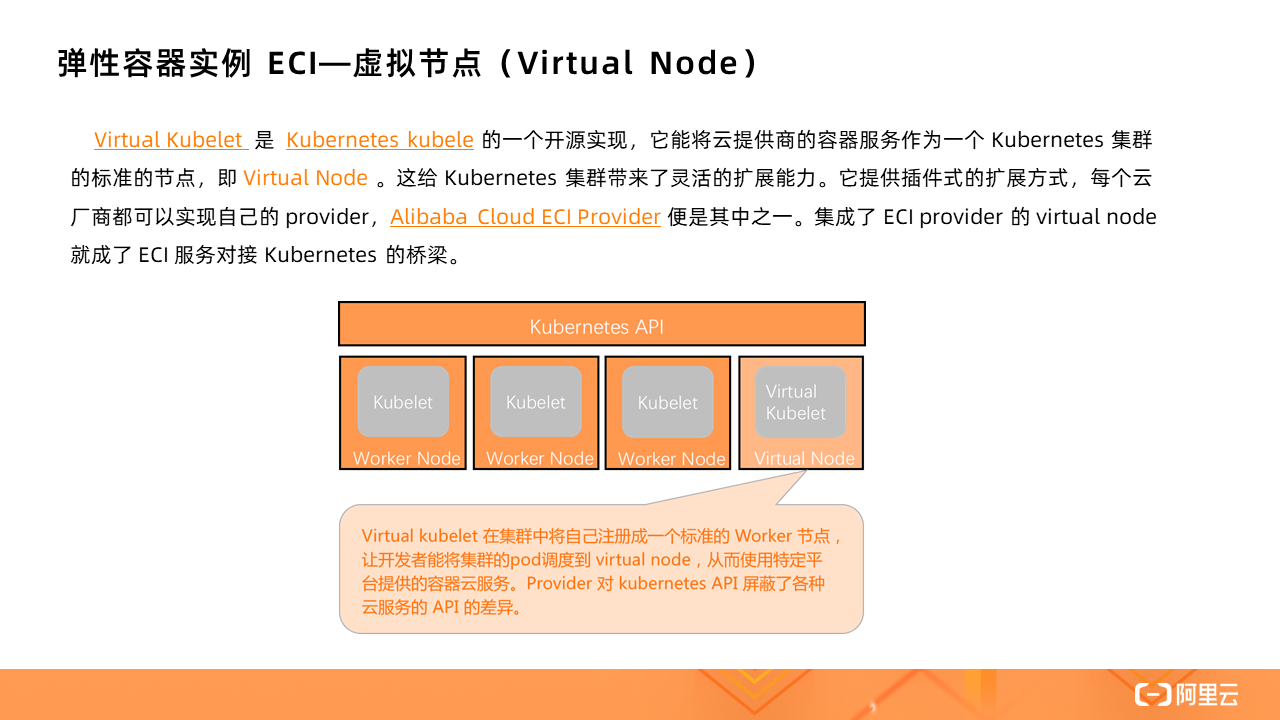
有了 Virtual Kubelet,标准的 Kubernetes 集群就可以将 ECS 和虚拟节点混部,将 Virtual Node 作为应对突发流量的弹性资源池。
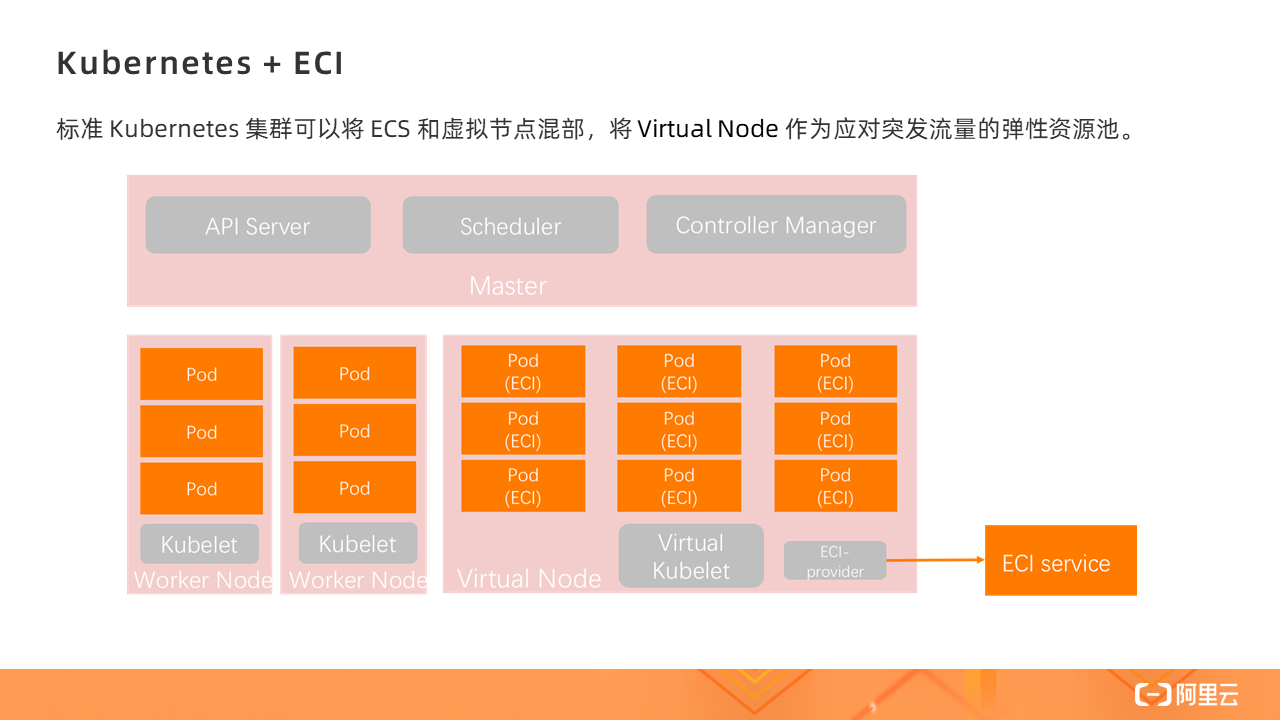
Serverless 集群中没有任何 ECS worker 节点,也无需预留、规划资源,只有一个 Virtual Node,所有的 Pod 的创建都是在 Virtual Node 上,即基于 ECI 实例。
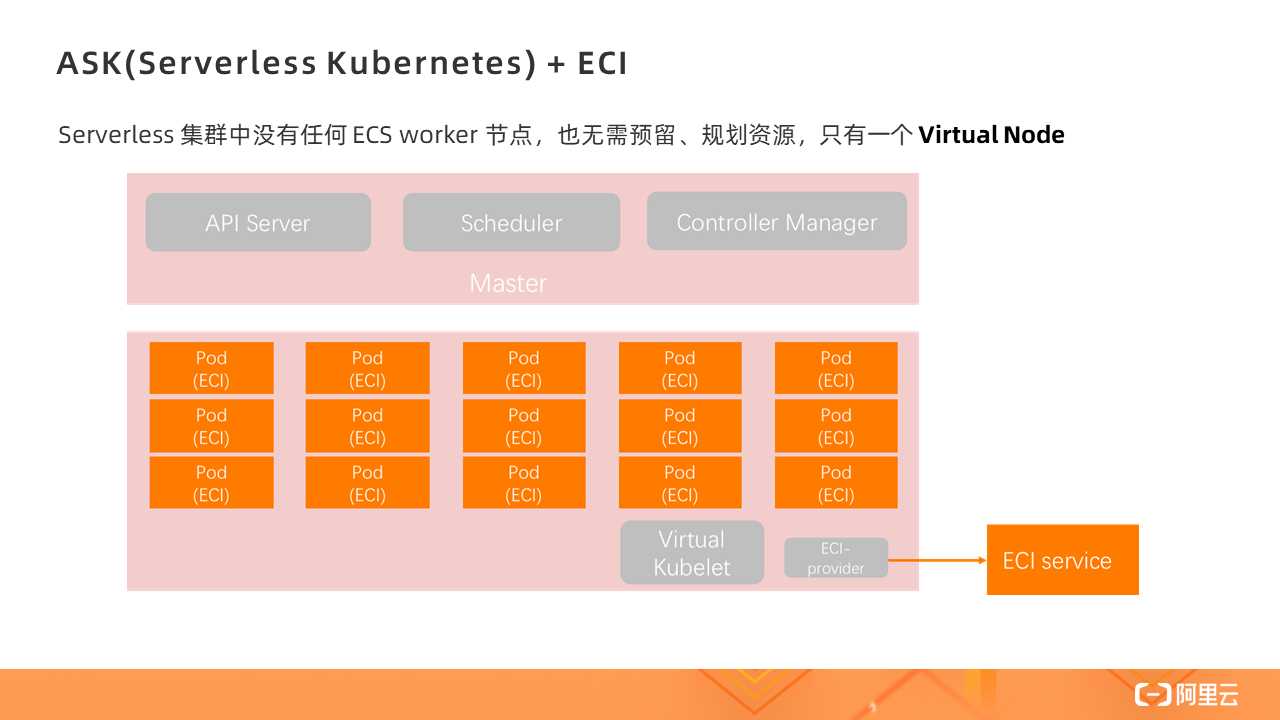
Serverless Kubernetes 是以容器和 Kubernetes 为基础的 Serverless 服务,它提供了一种简单易用、极致弹性、最优成本和按需付费的 Kubernetes 容器服务,其中无需节点管理和运维,无需容量规划,让用户更关注应用而非基础设施的管理。
Spark 自 2.3.0 开始试验性支持 Standalone、on YARN 以及 on Mesos 之外的新的部署方式:Running Spark on Kubernetes,如今支持已经非常成熟。
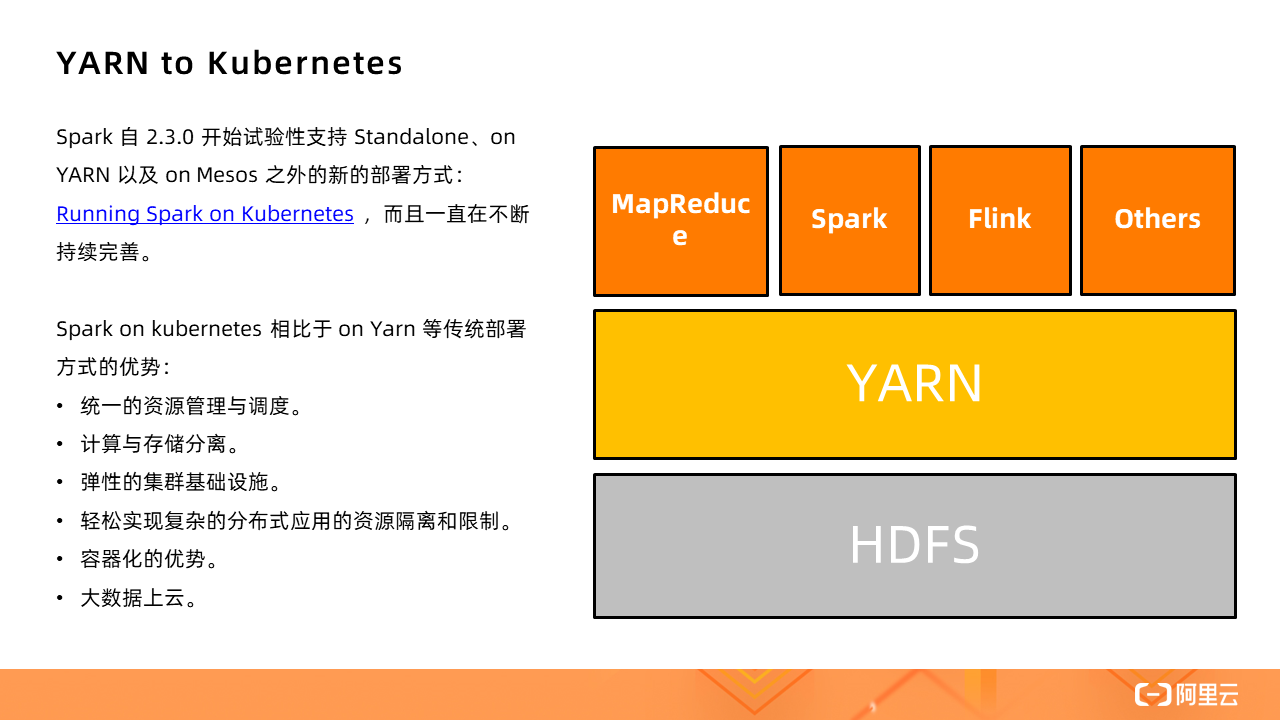
Spark on kubernetes 相比于 on Yarn 等传统部署方式的优势:
1、统一的资源管理。不论是什么类型的作业都可以在一个统一的 Kubernetes 集群中运行,不再需要单独为大数据作业维护一个独立的 YARN 集群。
2、传统的将计算和存储混合部署,常常会为了扩存储而带来额外的计算扩容,这其实就是一种浪费;同理,只为了提升计算能力,也会带来一段时期的存储浪费。Kubernetes 直接跳出了存储限制,将离线计算的计算和存储分离,可以更好地应对单方面的不足。
3、弹性的集群基础设施。
4、轻松实现复杂的分布式应用的资源隔离和限制,从 YRAN 复杂的队列管理和队列分配中解脱。
5、容器化的优势。每个应用都可以通过 Docker 镜像打包自己的依赖,运行在独立的环境,甚至包括 Spark 的版本,所有的应用之间都是完全隔离的。
6、大数据上云。目前大数据应用上云常见的方式有两种:1)用 ECS 自建 YARN(不限于 YARN)集群;2)购买 EMR 服务,目前所有云厂商都有这类 PaaS,如今多了一个选择——Kubernetes。
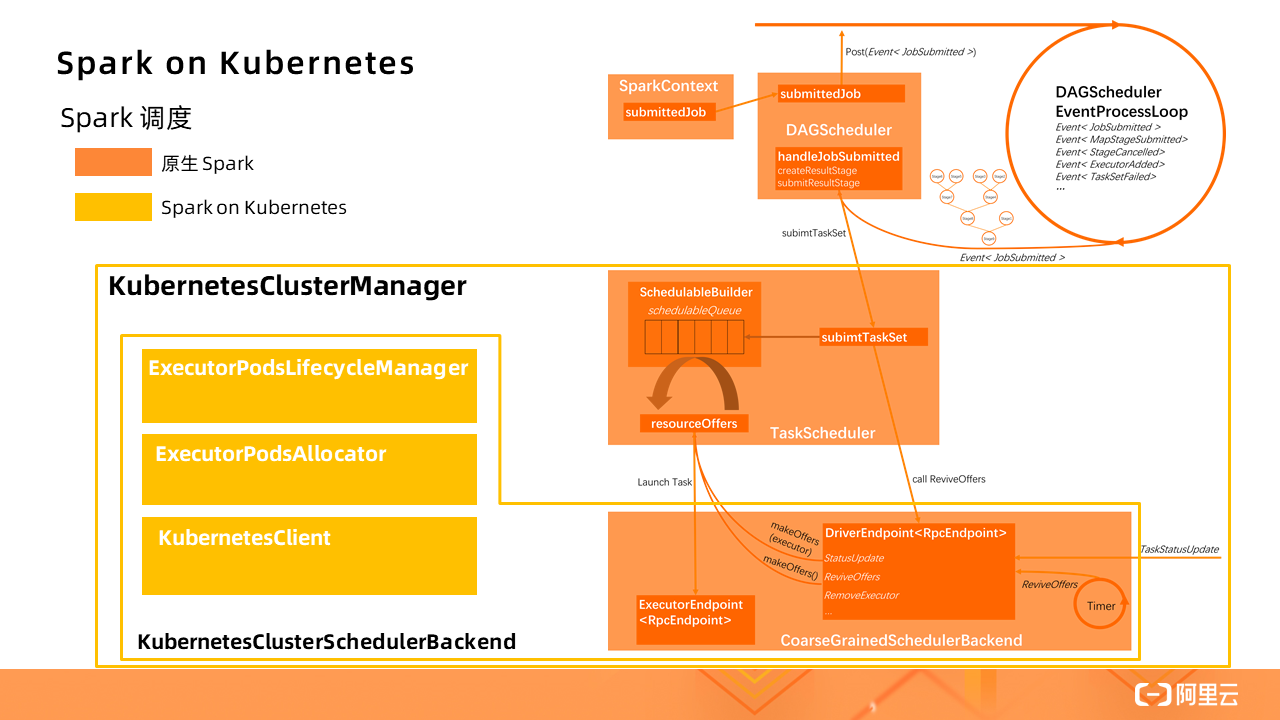
图中橙色部分是原生的 Spark 应用调度流程,而 Spark on Kubernetes 对此做了一定的扩展(黄色部分),实现了一个 KubernetesClusterManager。其中 KubernetesClusterSchedulerBackend 扩展了原生的CoarseGrainedSchedulerBackend,新增了 ExecutorPodsLifecycleManager、ExecutorPodsAllocator 和KubernetesClient 等组件,实现了将标准的 Spark Driver 进程转换成 Kubernetes 的 Pod 进行管理。
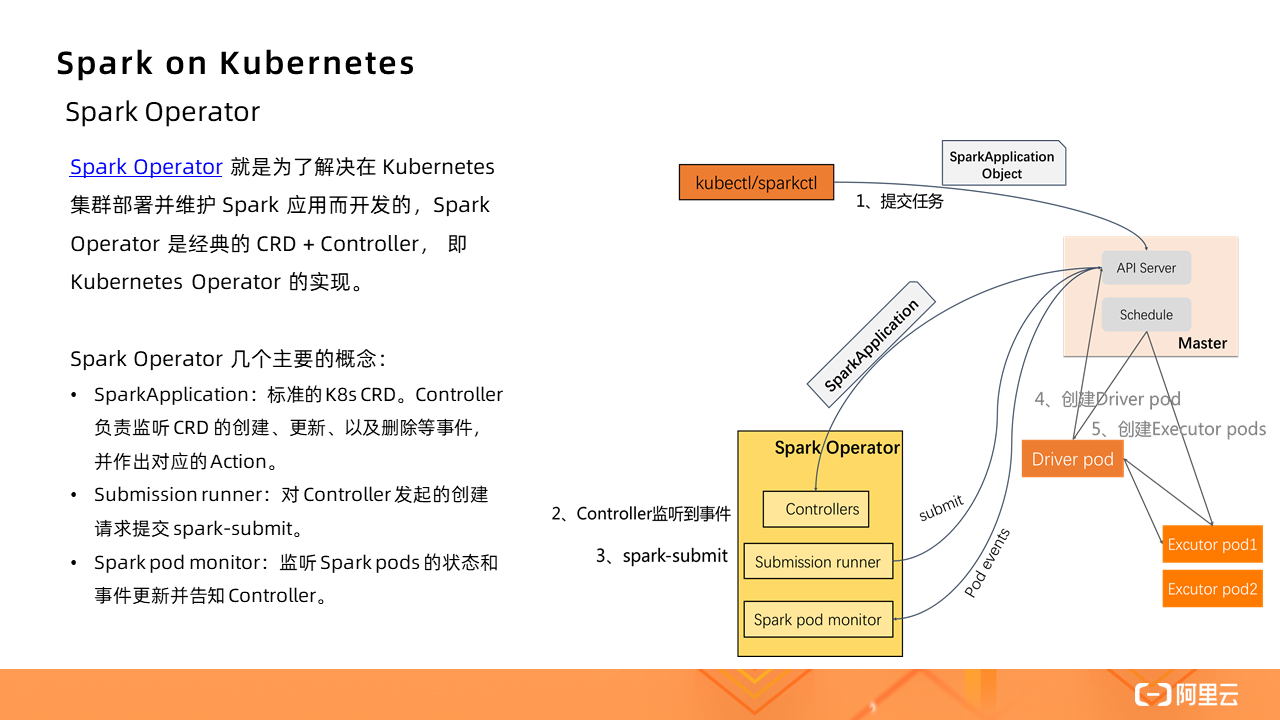
在 Spark Operator 出现之前,在 Kubernetes 集群提交 Spark 作业只能通过 Spark submit 的方式。创建好 Kubernetes 集群,在本地即可提交作业。
作业启动的基本流程:
1、Spark 先在 K8s 集群中创建 Spark Driver(pod)。
2、Driver 起来后,调用 K8s API 创建 Executors(pods),Executors 才是执行作业的载体。
3、作业计算结束,Executor Pods 会被自动回收,Driver Pod 处于 Completed 状态(终态)。可以供用户查看日志等。
4、Driver Pod 只能被用户手动清理,或者被 K8s GC 回收。
直接通过这种 Spark submit 的方式,参数非常不好维护,而且不够直观,尤其是当自定义参数增加的时候;此外,没有 Spark Application 的概念了,都是零散的 Kubernetes Pod 和 Service 这些基本的单元,当应用增多时,维护成本提高,缺少统一管理的机制。
Spark Operator?就是为了解决在 Kubernetes 集群部署并维护 Spark 应用而开发的,Spark Operator 是经典的 CRD + Controller,即 Kubernetes Operator 的实现。
下图为 SparkApplication 状态机:
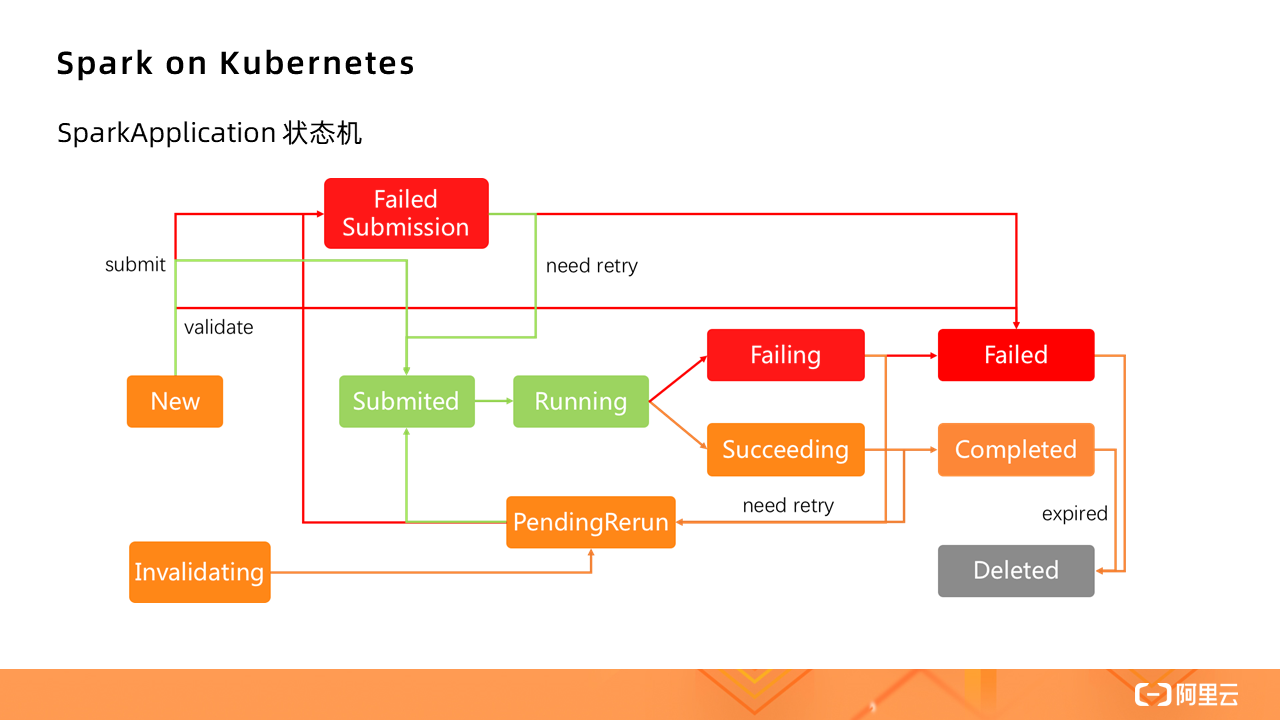
那么,如果在 Serverless Kubernetes 集群中运行 Spark,其实际上是对原生 Spark 的进一步精简。
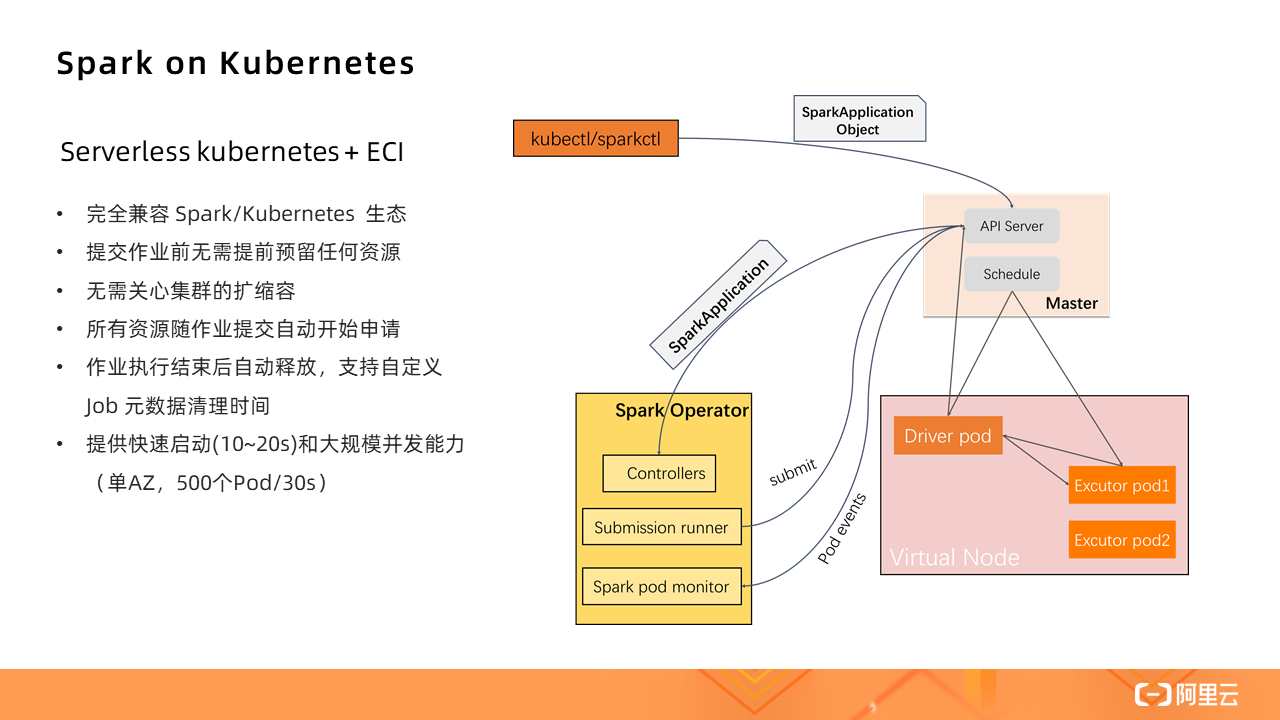
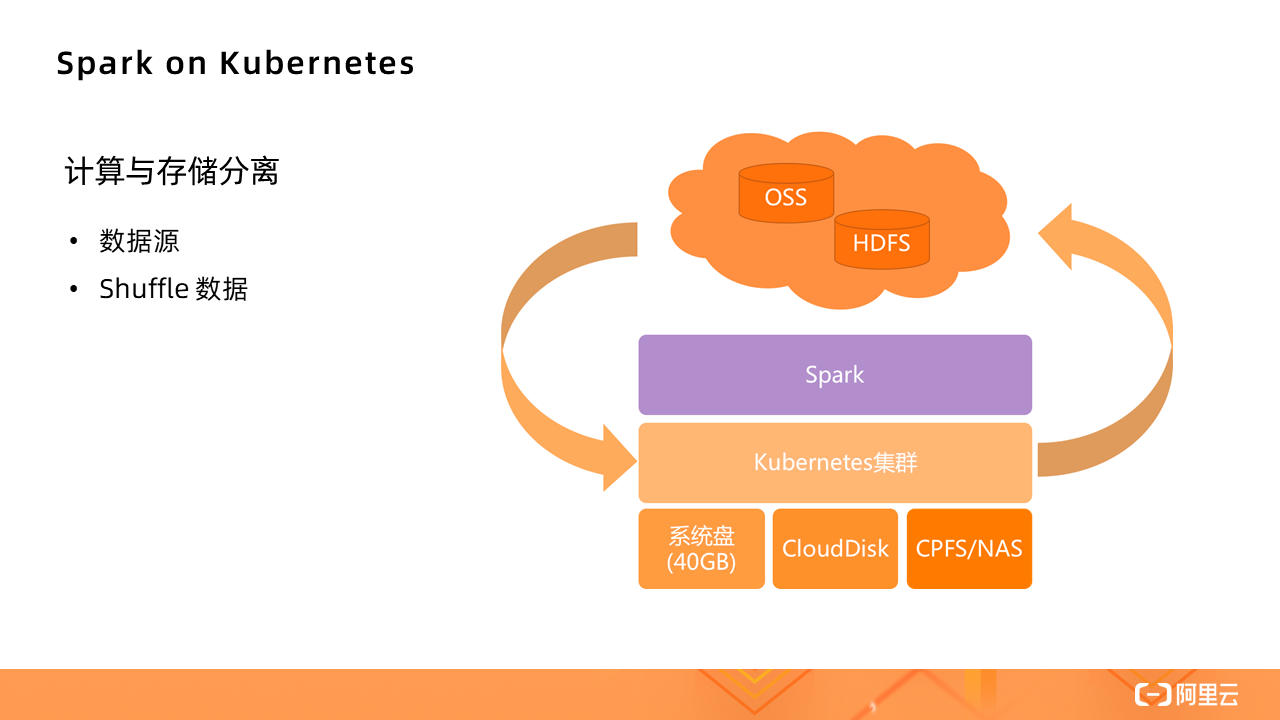
对于批量处理的数据源,由于集群不是基于 HDFS 的,所以数据源会有不同,需要计算与存储分离,Kubernetes 集群只负责提供计算资源。
本次实操分别展示 TPC-DS 和 WordCount 两个应用,点击即可观看具体操作演示过程
Serverless 公众号,发布 Serverless 技术最新资讯,汇集 Serverless 技术最全内容,关注 Serverless 趋势,更关注你落地实践中的遇到的困惑和问题。
如何在 Serverless K8s 集群中低成本运行 Spark 数据计算?
标签:限制 exec allocator nod ecs driver 资源管理 演示 erb
原文地址:https://blog.51cto.com/14902238/2562984