标签:png order 源码 爬取 pycha https load 记录 格式
首先打开考试系统,登录,进入考试,点击试题库。
按F12打开调试窗口,随便选择一个题目。
按F12打开调试窗口,Ctrl+Shift+C选择元素,随便选择一个题目
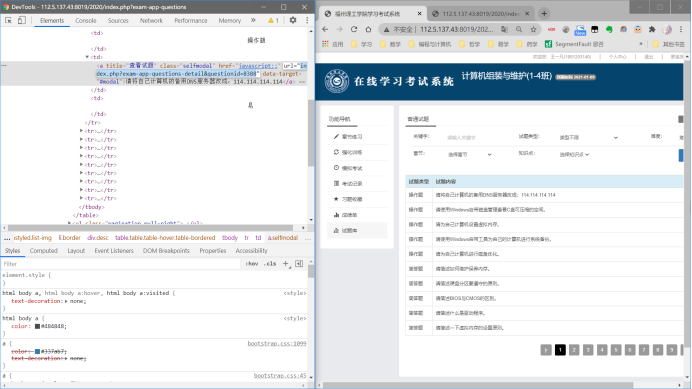
可以看到操作题第一题的 url="index.php?exam-app-questions-detail&questionid=8388"。
将考试系统的地址前缀复制进来得到网址:
"http://112.5.137.43:8019/2020/index.php?exam-app-questions-detail&questionid=8388"
并且观察到整个题库中8388为最大编号(第一页第一个题目),最后面的8286为最小编号(最后一页最后一个题目)。
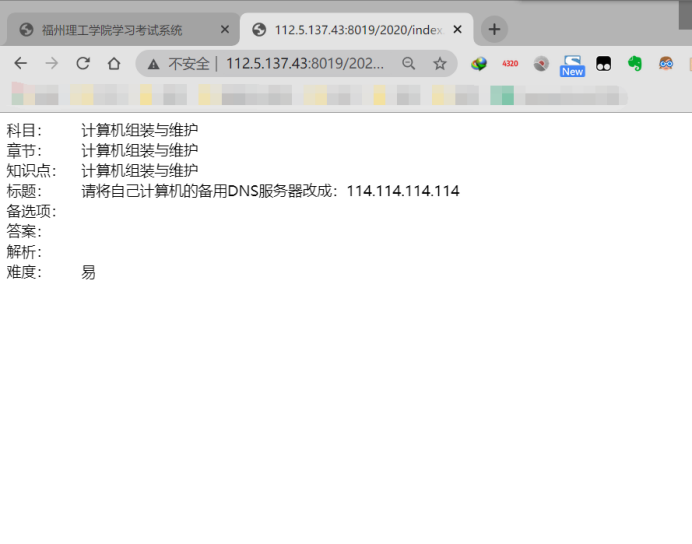
用浏览器访问上面那个题目的网址发现可以访问,并且打开F12调试工具发现body中只有一个表格,格式如下:
|
科目: |
计算机组装与维护 |
|
章节: |
计算机组装与维护 |
|
知识点: |
计算机组装与维护 |
|
标题: |
请将自己计算机的备用DNS服务器改成:114.114.114.114 |
|
备选项: |
|
|
答案: |
|
|
解析: |
|
|
难度: |
易 |
在网上搜索“用python爬取网站教程”得到了一个不错的简单教程:
https://blog.csdn.net/haoronge9921/article/details/103511467
试着在Pycharm中不设置cookie尝试爬取上面那个题目网址的网页
可以看到运行结果为要求用户登录的界面
接下来获取自己的cookie
打开题目页面且摁F12打开调试,刷新一下,切换到NETWORK栏
点下这玩意
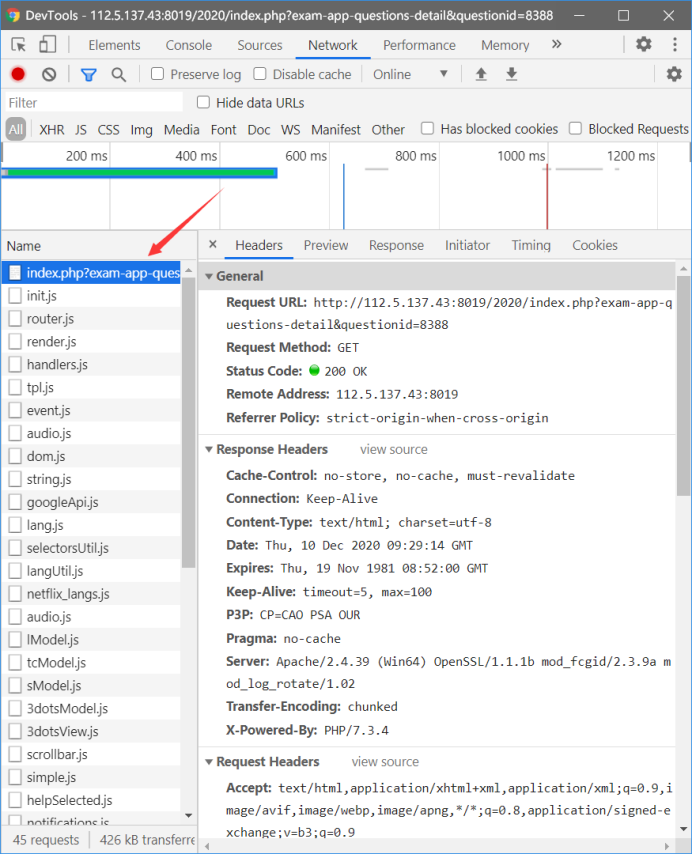
在Headers下面找到自己的cookie 和User-Agent
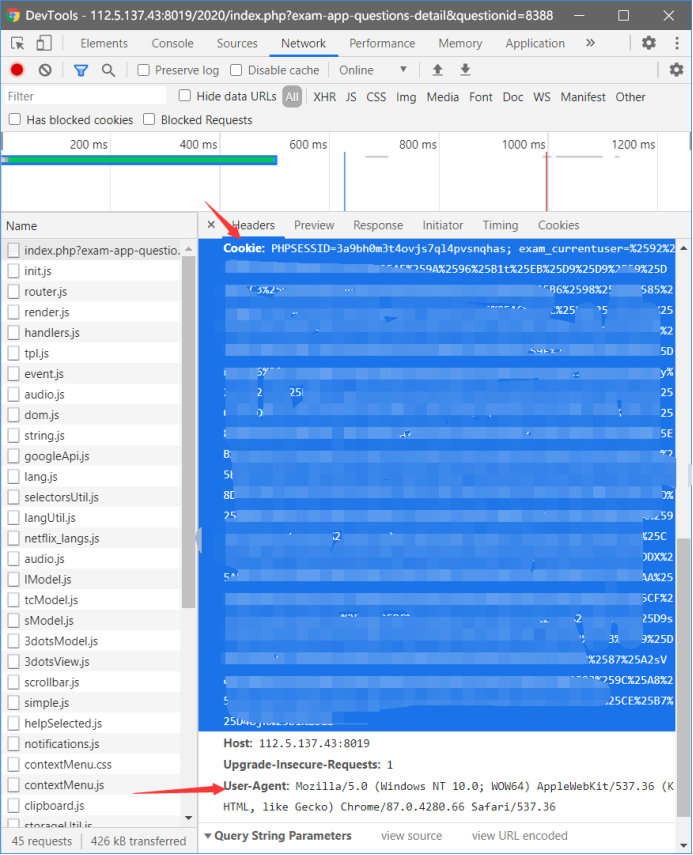
(其实这一步也可以在APPLICATION栏里完成)
把自己的coockie和User-Agent贴到上面那个教程里获得的代码

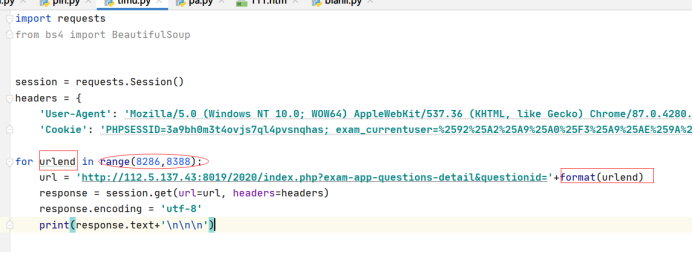
url替换成题目的url,执行代码发现可以输出
接下来直接定义一个for循环,从8286题一直输出到8388题并打印
结果全部103题都以网页源码输出了:
复制输出结果出来到txt中。
103题总共是103个table
用SublimeText的批量替换功能去除不需要的行:科目、章节、知识点、解析、难度。
最后将txt后缀改为html得效果如下
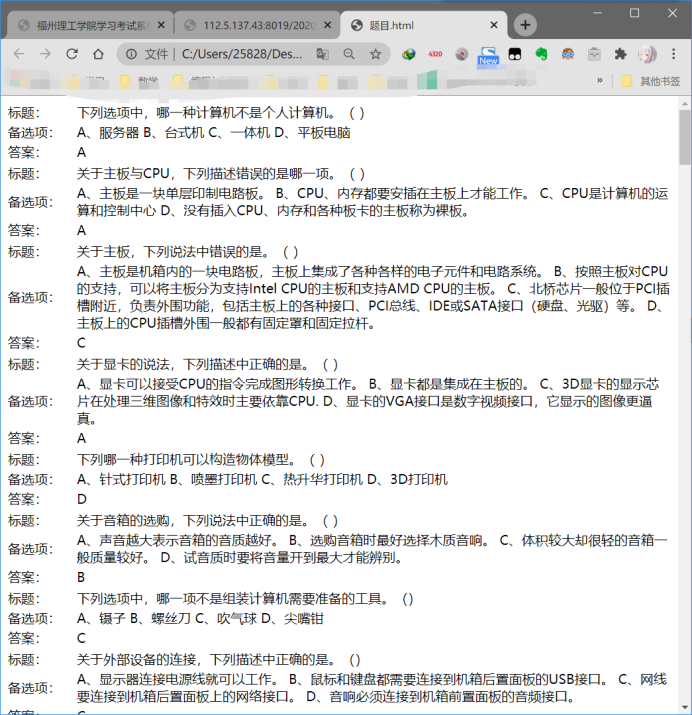
接下来把这个网页导入到Excel表格里(上网查了下才知道有这个功能),顺序是:新建个表格,数据->从文本或csv
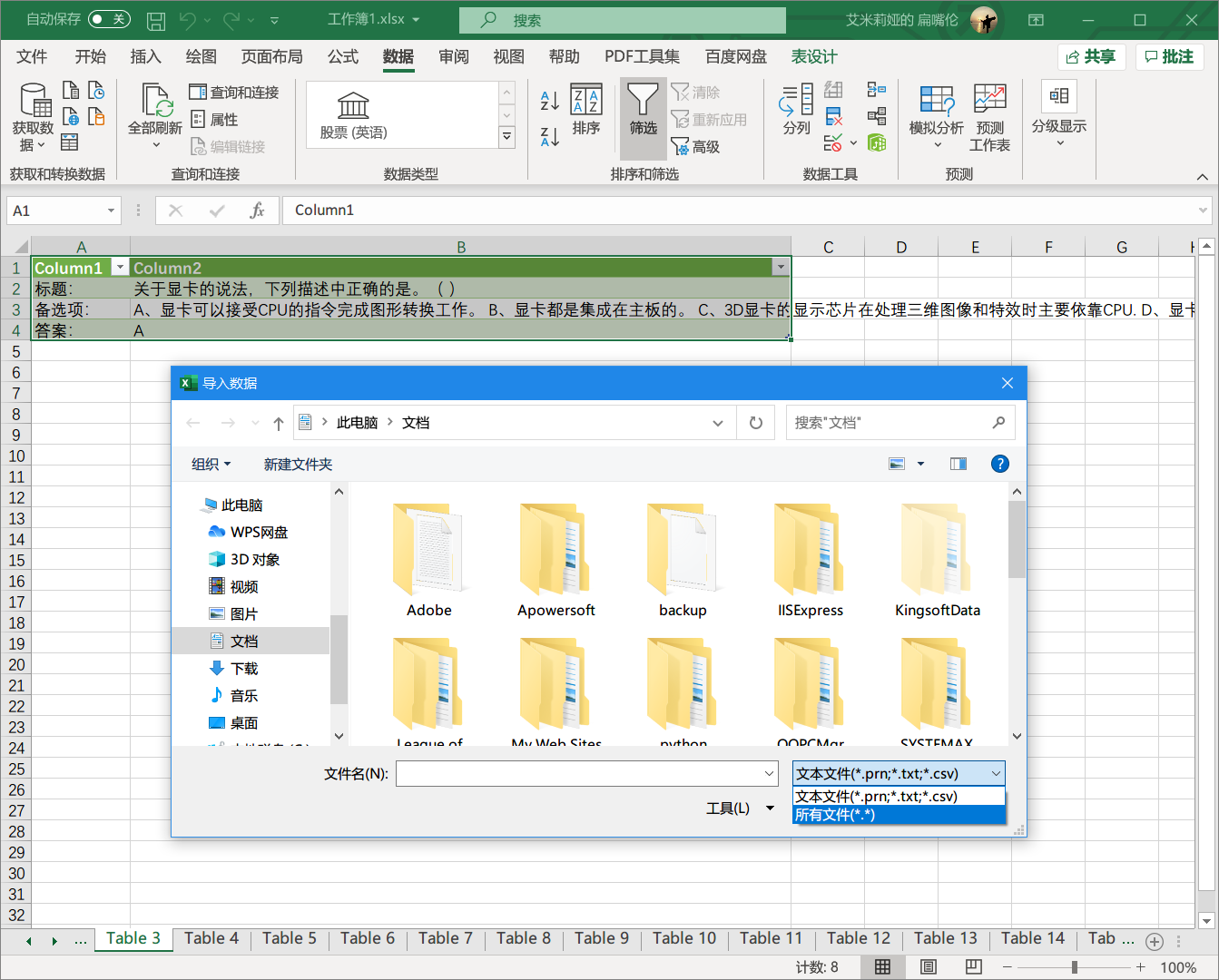 这里选所有文件
这里选所有文件
选择处理好的网页文件,导入
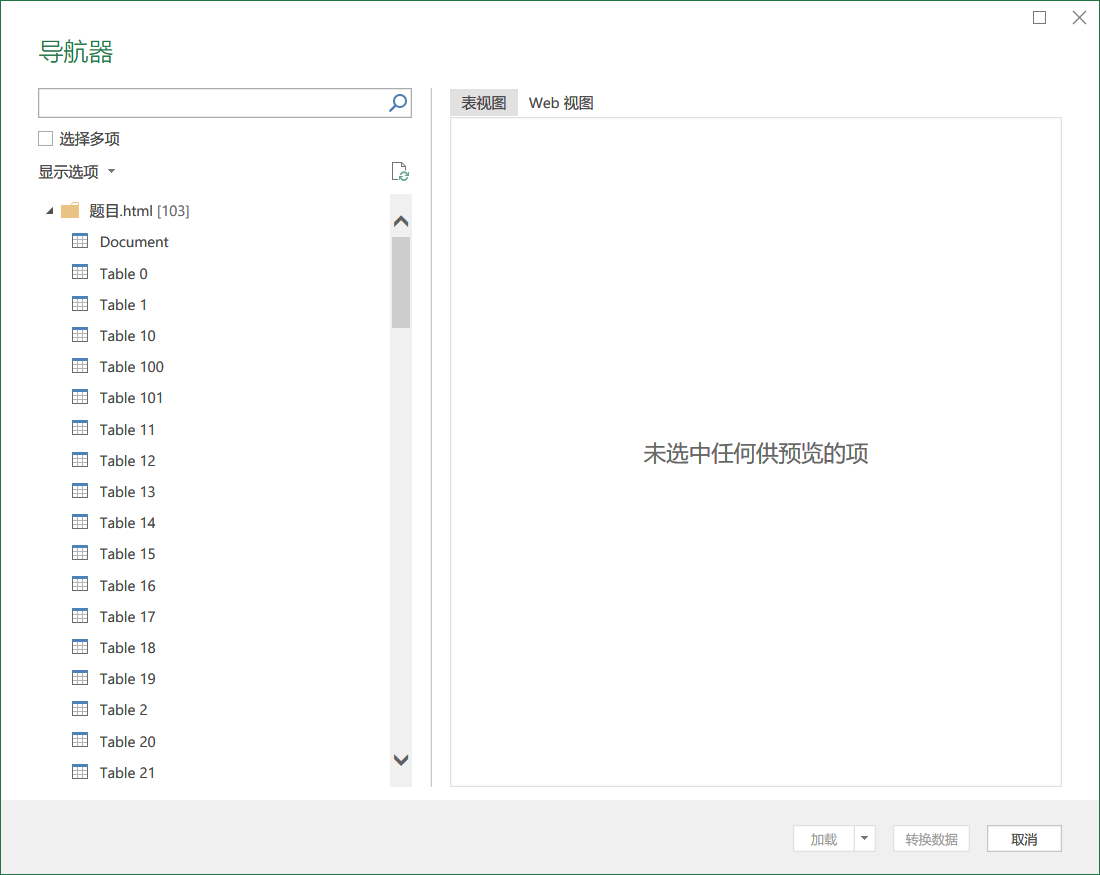
之后选择多项,选择所有题目表格。
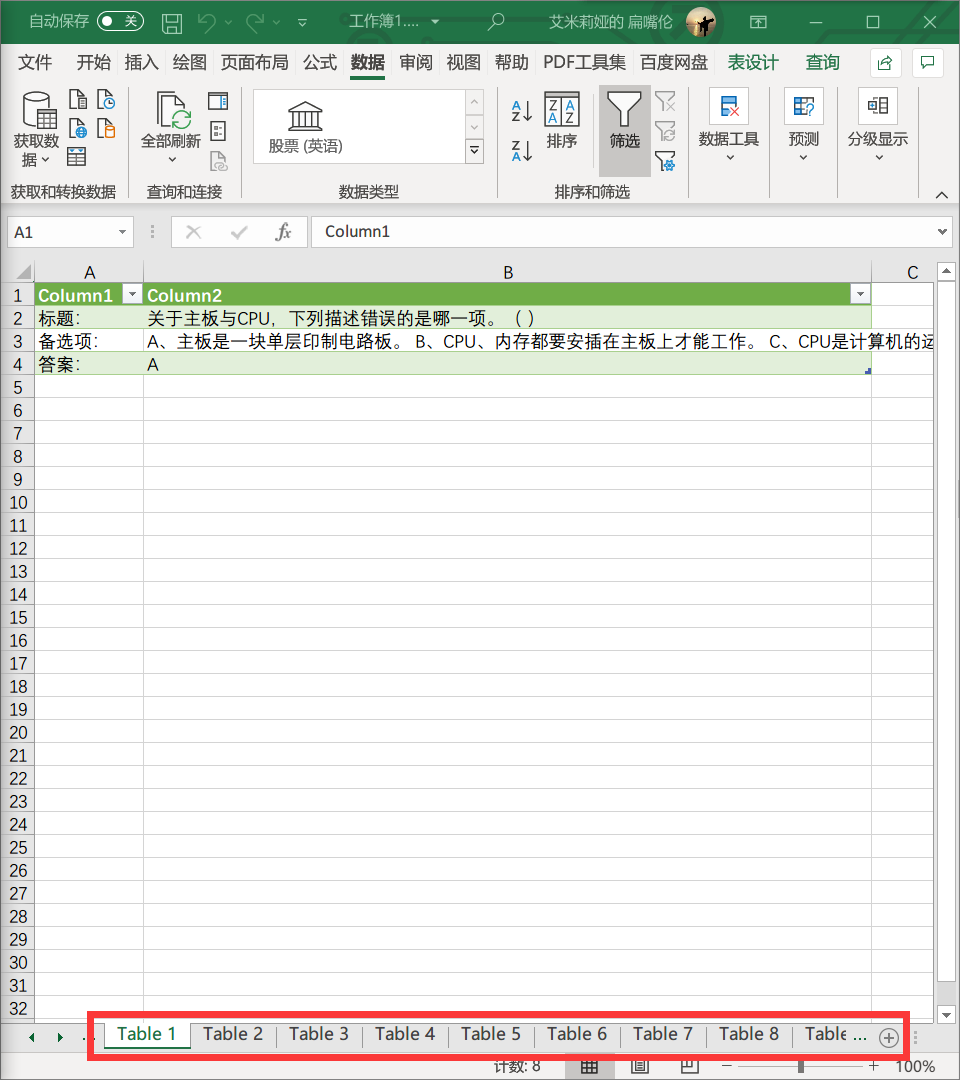
处理好后是这样有一百多个工作表
用WPS合并所有工作表,这功能需要WPS会员,巧的是这软件突然就送我了个7天体验会员,就用上了。
合并表格后,用WPS将其复制到WORD中。
稍微修改一下格式,美化下,就得到了新鲜出炉的题库Word文件。
记录一下自己是如何将题库中的所有题目爬出来并整理成Wrod文档的
标签:png order 源码 爬取 pycha https load 记录 格式
原文地址:https://www.cnblogs.com/lunlunlun/p/14123415.html