标签:抽象 纯粹 daemon too https eps lua 构建 time
近日 K8s 官方称最早将在 1.23版本弃用 docker 作为容器运行时,并在博客中强调可以使用如 containerd 等 CRI 运行时来代替 docker。本文会做详细解读,并介绍 docker 与 containerd 的关系,以及为什么 containerd 是更好的选择。这里先回答下TKE用户关心的问题:我们的集群该怎么办?Docker support in the kubelet is now deprecated and will be removed in a future release. The kubelet uses a module called "dockershim" which implements CRI support for Docker and it has seen maintenance issues in the Kubernetes community. We encourage you to evaluate moving to a container runtime that is a full-fledged implementation of CRI (v1alpha1 or v1 compliant) as they become available. (#94624, @dims) [SIG Node]
K8s 在 1.20的 change log 中提到 K8s 将于 1.20版本开始逐步放弃对 Docker 的支持。在 K8s 的官方博客中也提到具体的声明和一些 FAQ。
在博客中提到 K8s 将在 1.20版本中添加不推荐使用 docker 的信息,且最早将于 1.23版本中把 dockershim 从 kubelet 中移除,届时用户将无法使用 docker 作为 K8s 集群的运行时,不过通过 docker 构建的镜像在没有 docker 的 K8s 集群中依然可以使用。
本次改动主要内容是准备删除 kubelet 中的 dockershim,当然这种做法也是符合预期的。在早期 rkt 和 docker 争霸时,kubelet 中需要维护两坨代码分别来适配 docker 和 rkt ,这使得 kubelet 每次发布新功能都需要考虑对运行时组件的适配问题,严重拖慢了新版本发布速度。另外虚拟化已经是一个普遍的需求,如果出现了类型的运行时,SIG-Node 小组可能还需要把和新运行时适配的代码添加到 kubelet 中。这种做法并不是长久之计,于是在 2016 年,SIG-Node提出了容器操作接口 CRI(Container Runtime Interface)。 CRI 是对容器操作的一组抽象,只要每种容器运行时都实现这组接口,kubelet 就能通过这组接口来适配所有的运行时。但 Docker 当时并没有(也不打算)实现这组接口, kubelet 只能在内部维护一个称之为“dockershim”组件,这个组件充当了 docker 的 CRI 转接器,kubelet 在创建容器时通过 CRI 接口调用 dockershim ,而 dockershim 在通过 http 请求把请求交给 docker 。于是 kubelet 的架构变成下图这样: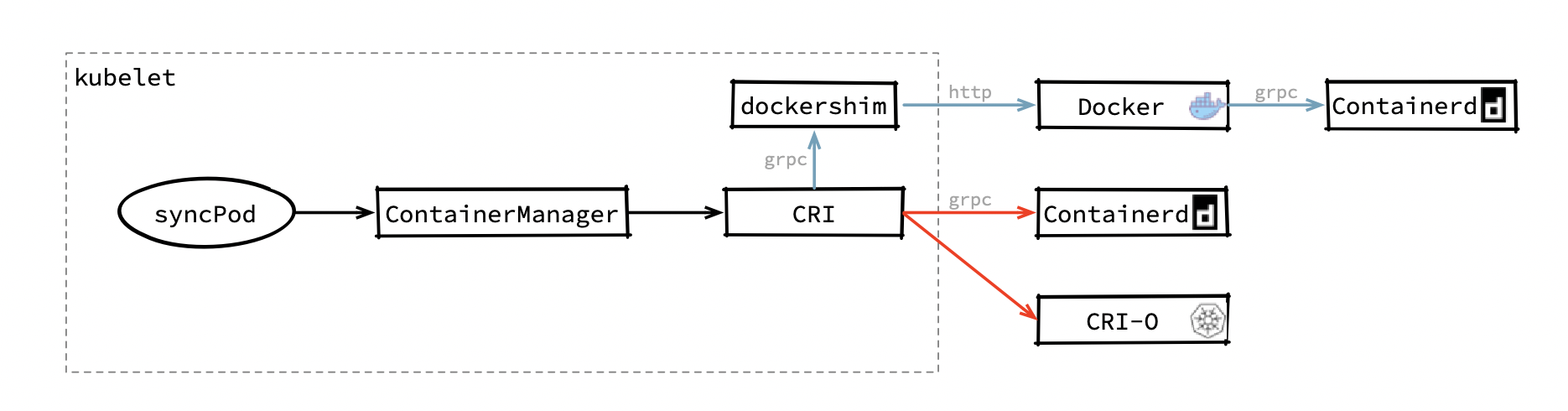
在使用实现了 CRI 接口的组件作为容器运行时的情况下,kubelet 创建容器的调用链如图中红色箭头所示,kubelet 中的 ContainerManager 可以直接通过 CRI 调用到容器运行时,这过程中只需要一次 grpc 请求;而在使用 docker 时,ContainerManager 会走图中蓝色的调用链, CRI 的请求通过 unix:///var/run/dockershim.sock 流向 dockershim,dockershim 做转换后把请求转发给 docker,至于为什么 docker 后面还有个 containerd 稍后会讲到。在 kubelet 中实现 docker 的转接器本来就是一种不优雅的实现,这种做法让调用链变长且不稳定性,还给 kubelet 的维护添加了额外工作,把这部分内容从 kubelet 删掉就是时间问题了。
If you’re an end-user of Kubernetes, not a whole lot will be changing for you. This doesn’t mean the death of Docker, and it doesn’t mean you can’t, or shouldn’t, use Docker as a development tool anymore. Docker is still a useful tool for building containers, and the images that result from running
docker buildcan still run in your Kubernetes cluster.
消息一出,大家最关心的事情应该就是弃用 docker 后到底会产生什么影响?
官方的答复是:Don‘t Panic!随后又重点解释了几个大家最关心的问题,我们来分析下官方提到的这些方面:
正常的 K8s 用户不会有任何影响
是的,生产环境中高版本的集群只需要把运行时从 docker 切换到其他的 runtime(如 containerd)即可。containerd 是 docker 中的一个底层组件,主要负责维护容器的生命周期,跟随 docker 经历了长期考验。同时 2019年初就从 CNCF 毕业,可以单独作为容器运行时用在集群中。TKE 也早在 2019 年就已经提供了 containerd 作为运行时选项,因此把 runtime 从 docker 转换到 containerd 是一个基本无痛的过程。CRI-O 是另一个常被提及的运行时组件,由 redhat 提供,比 containerd 更加轻量级,不过和 docker 的区别较大,可能转换时会有一些不同之处。
开发环境中通过docker build构建出来的镜像依然可以在集群中使用
镜像一直是容器生态的一大优势,虽然人们总是把镜像称之为“docker镜像”,但镜像早就成为了一种规范了。具体规范可以参考image-spec。在任何地方只要构建出符合 Image Spec 的镜像,就可以拿到其他符合 Image Spec 的容器运行时上运行。
在 Pod 中使用 DinD(Docker in Docker)的用户会受到影响
有些使用者会把 docker 的 socket (/run/docker.sock)挂载到 Pod 中,并在 Pod 中调用 docker 的 api 构建镜像或创建编译容器等,官方在这里的建议是使用 Kaniko、Img 或 Buildah。我们可以通过把 docker daemon 作为 DaemonSet 或者给想要使用 docker 的 Pod 添加一个 docker daemon 的 sidecar 的方式在任意运行时中使用 DinD 的方案。TKE 也专门为在 containerd 集群中使用 DinD 提供了方案,详见 在containerd中使用DinD。
所以 containerd 到底是个啥?和 docker 又是什么关系?可能有些同学看到博客后会发出这样的疑问,接下来就给同学们讲解下 containerd 和 docker 的渊源。
2016年,docker 把负责容器生命周期的模块拆分出来,并将其捐赠给了社区,也就是现在的 containerd。docker 拆分后结构如下图所示(当然 docker 公司还在 docker 中添加了部分编排的代码)。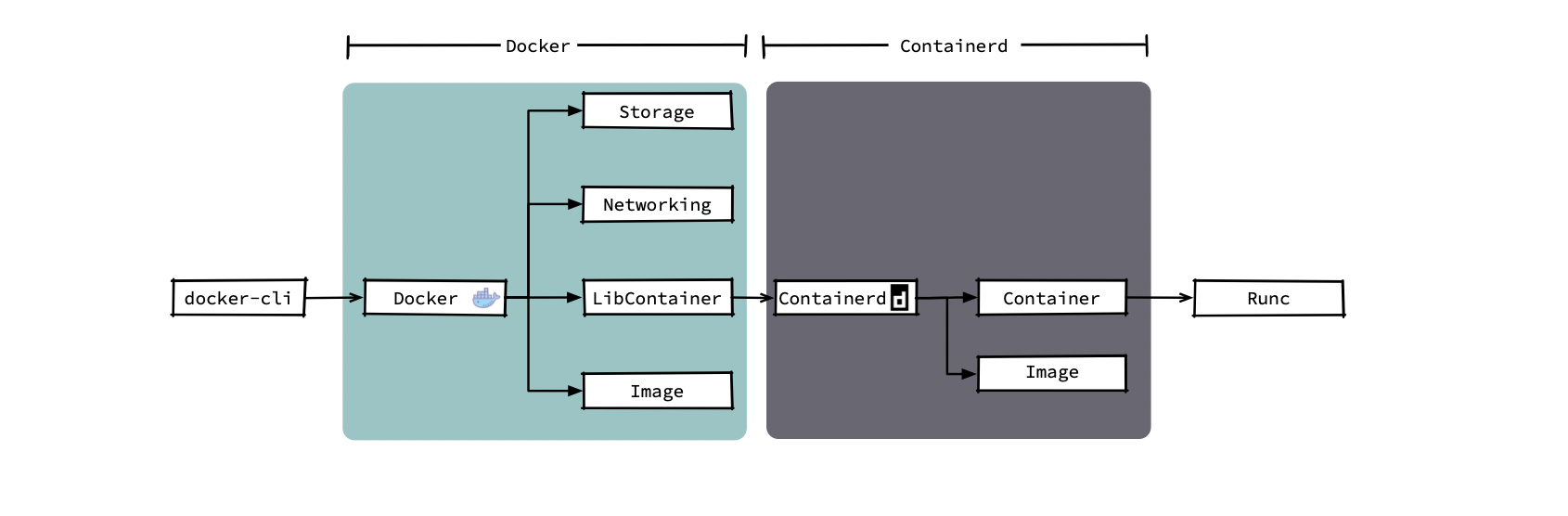
在我们调用 docker 命令创建容器后,docker daemon 会通过 Image 模块下载镜像并保存到 Graph Driver 模块中,之后通过 client 调用containerd 创建并运行容器。我们在使用 docker 创建容器时可能需要使用--volume给容器添加持久化存储;还有可能通过--network连接我们用 docker 命令创建的几个容器,当然,这些功能是 docker 中的 Storage 模块和 Networking 模块提供给我们的。但 K8s 提供了更强的卷挂载能力和集群级别的网络能力,在集群中 kubelet 只会使用到 docker 提供的镜像下载和容器管理功能,而编排、网络、存储等功能都不会用到。下图中可以看出当前的模式下各模块的调用链,同时图中被红框标注出的几个模块就是 kubelet 创建 Pod 时所依赖的几个运行时的模块。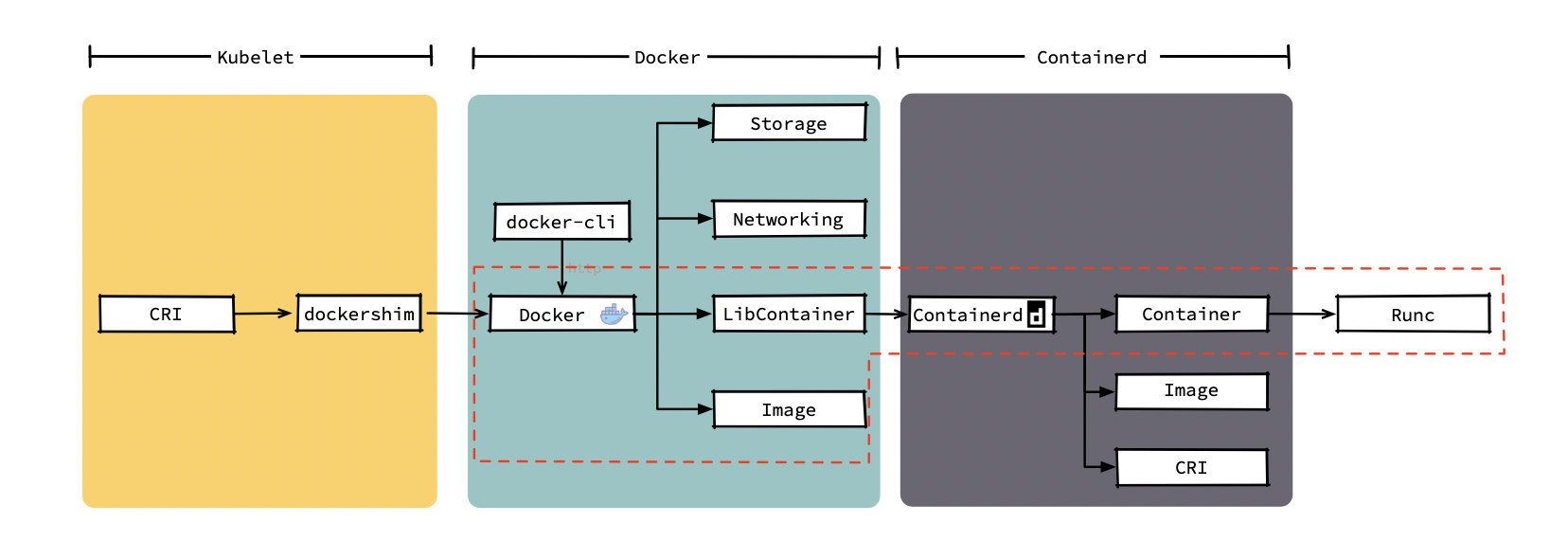
containerd 被捐赠给CNCF社区后,社区给其添加了镜像管理模块和 CRI 模块,这样 containerd 不只可以管理容器的生命周期,还可以直接作为 K8s 的运行时使用。于是 containerd 在 2019年2月从 CNCF 社区毕业,正式进入生产环境。下图中能看出以 containerd 作为容器运行时,可以给 kubelet 带来创建 Pod 所需的全部功能,同时还得到了更纯粹的功能模块以及更短的调用链。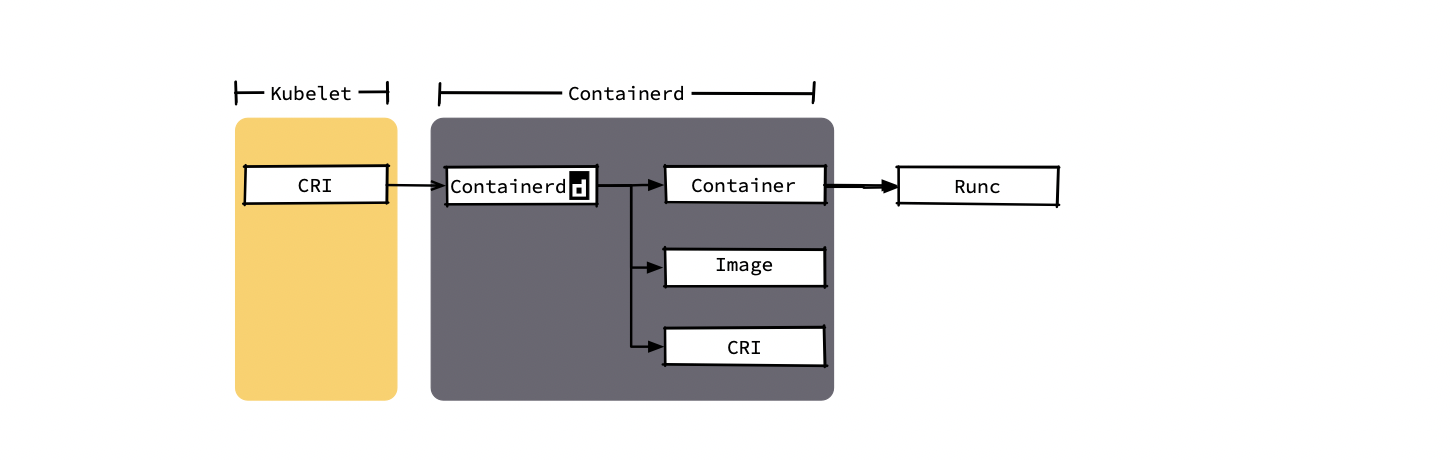
从上面的对比可以看出从 containerd 被捐赠给社区开始,就一直以成为简单、稳定且可靠的容器运行时为目标;而 docker 则是希望能成为一个完整的产品。官方文档中也提到了这一点,docker 为了给用户更好的交互和使用体验以及更多的功能,提供了很多开发人员所需要的特性,同时为了给 swarm 做基础,提供了网络和卷的功能。而这些功能其实都是是 K8s 用不上的;containerd 则相反,仅提供了 kubelet 创建 Pod 所需要的基础功能,当然这换来的就是更高的鲁棒性以及更好的性能。在一定程度上讲,即使在 kubelet 1.23 版本之后 docker 提供了 CRI 接口,containerd 仍然是更好的选择。
当然现在有诸多的 CRI 实现者,比较主要的除了 containerd 还有 CRI-O。CRI-O 是主要由 Red Hat 员工开发的 CRI 运行时,完全和 docker 没有关系,因此从 docker 迁移过来可能会比较困难。无疑 containerd 才是 docker 被抛弃后的 CRI 运行时的最佳人选,对于开发同学来说整个迁移过程应该是无感知的,不过对于部分运维同学可能会比较在意部署和运行中细节上的差异。接下来我们重点介绍下在 K8s 中使用 containerd 和 docker 的几处区别。
| 对比项 | Docker | Containerd |
|---|---|---|
| 存储路径 | 如果 docker 作为 K8s 容器运行时,容器日志的落盘将由 docker 来完成,保存在类似/var/lib/docker/containers/$CONTAINERID 目录下。kubelet 会在 /var/log/pods 和 /var/log/containers 下面建立软链接,指向 /var/lib/docker/containers/$CONTAINERID 该目录下的容器日志文件。 | 如果 Containerd 作为 K8s 容器运行时, 容器日志的落盘由 kubelet 来完成,保存至 /var/log/pods/$CONTAINER_NAME 目录下,同时在 /var/log/containers 目录下创建软链接,指向日志文件。 |
| 配置参数 | 在 docker 配置文件中指定:"log-driver": "json-file","log-opts": {"max-size": "100m","max-file": "5"} | 方法一:在 kubelet 参数中指定:--container-log-max-files=5 --container-log-max-size="100Mi" 方法二:在 KubeletConfiguration 中指定: "containerLogMaxSize": "100Mi", "containerLogMaxFiles": 5, |
| 把容器日志保存到数据盘 | 把数据盘挂载到 “data-root”(缺省是 /var/lib/docker)即可。 | 创建一个软链接 /var/log/pods 指向数据盘挂载点下的某个目录。在 TKE 中选择“将容器和镜像存储在数据盘”,会自动创建软链接 /var/log/pods。 |
cni 配置方式的区别
在使用 docker 时,kubelet 中的 dockershim 负责调用 cni 插件,而 containerd 的场景中 containerd 中内置的 containerd-cri 插件负责调用 cni,因此关于 cni 的配置文件需要放在 containerd 的配置文件中(/etc/containerd/containerd.toml):
[plugins.cri.cni]
bin_dir = "/opt/cni/bin"
conf_dir = "/etc/cni/net.d"stream 服务的区别
说明:
Kubectl exec/logs 等命令需要在 apiserver 跟容器运行时之间建立流转发通道。
如何在 containerd 中使用并配置 Stream 服务?
Docker API 本身提供 stream 服务,kubelet 内部的 docker-shim 会通过 docker API 做流转发。而containerd 的 stream 服务需要单独配置:
[plugins.cri]
stream_server_address = "127.0.0.1"
stream_server_port = "0"
enable_tls_streaming = false [plugins.cri] stream_server_address = "127.0.0.1" stream_server_port = "0" enable_tls_streaming = falsecontainerd 的 stream 服务在 K8s 不同版本运行时场景下配置不同。
从 2019年5月份开始,TKE就开始支持把 containerd 作为容器运行时选项之一。随着TKE逐步在 containerd 集群中支持日志收集服务和 GPU 能力,2020年 9月份 containerd 在 TKE 也摘掉了 Beta 版本的标签,可以正式用于生产环境中了。在长期使用中,我们也发现了一些 containerd 的问题并且及时进行了修复,如:
想要在TKE集群中使用 containerd 作为运行时有三种方式:
在创建集群时,选择 1.12.4 及以上版本的 K8s 后,选择 containerd 为运行时组件即可
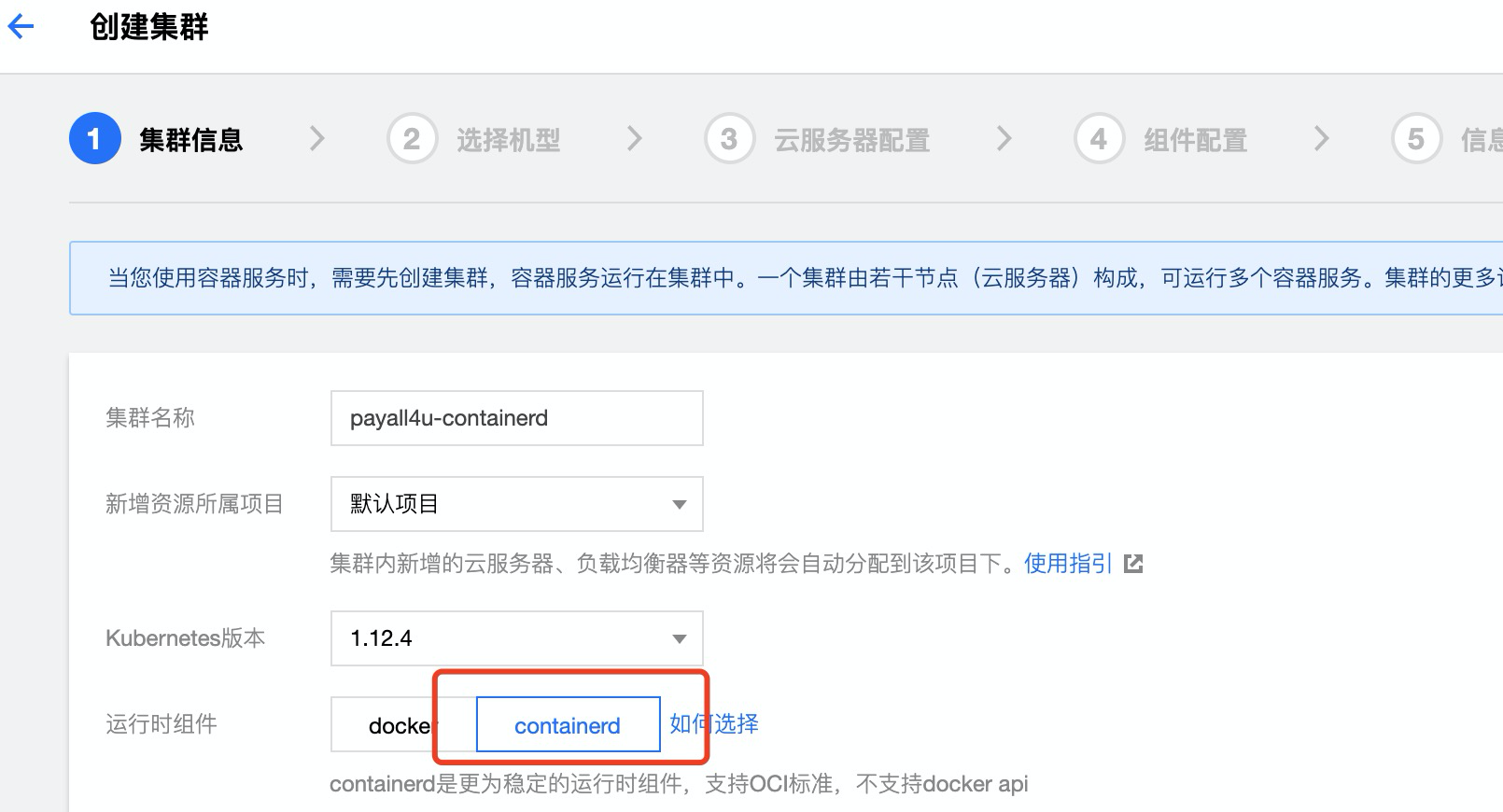
在已有 docker 集群中,通过创建运行时为 containerd 的节点池来创建一部分 containerd 节点(新建节点池 > 更多设置 > 运行时组件)
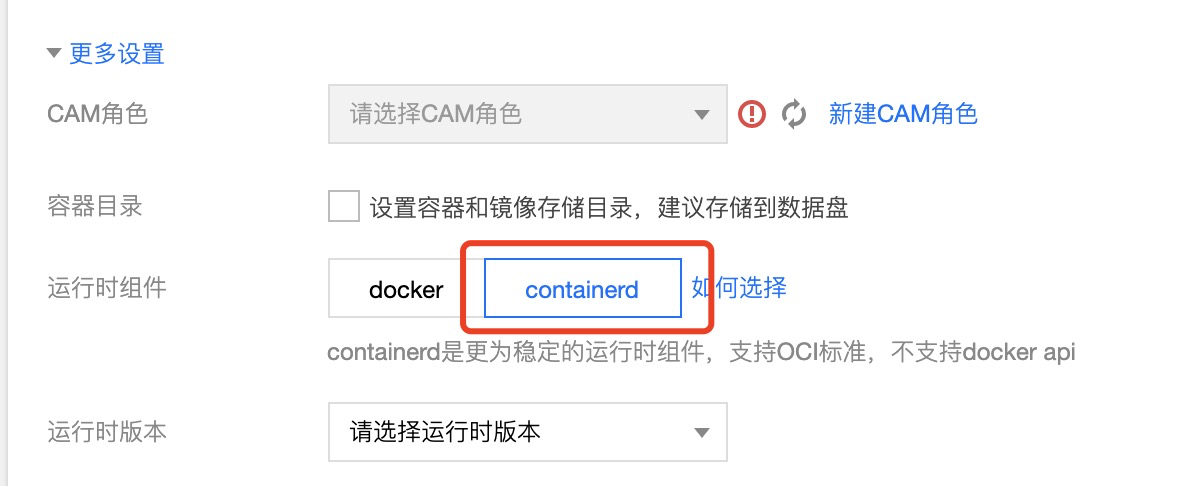
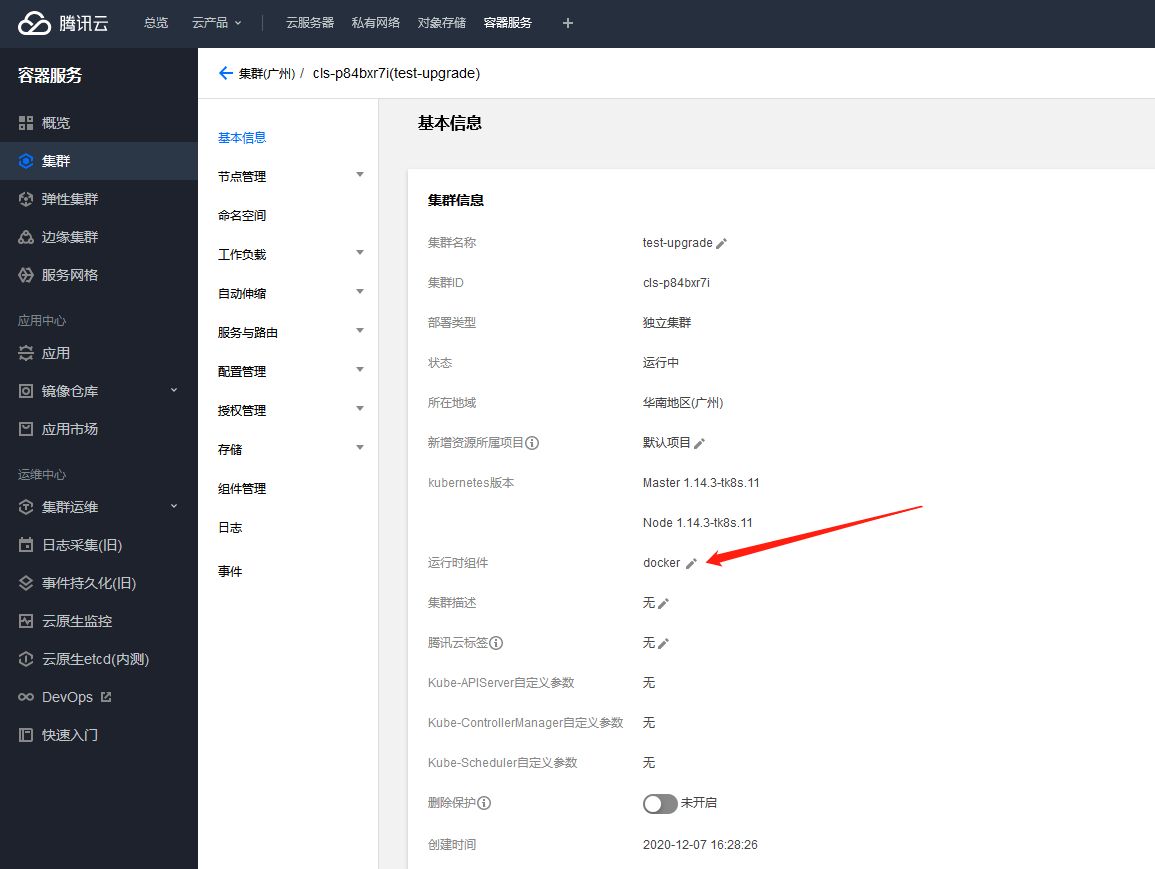
注意: 后两种方式会造成同一集群中 docker 节点与 containerd 节点共存,如果有使用 Docker in Docker, 或者其他依赖节点上 docker daemon 与 docker.sock 的业务,需要提前采取措施来避免产生问题,例如通过按节点标签调度,保证这类业务调度到 docker 节点;或者采用如前文所述在 containerd 集群运行 Docker in Docker 的方案。
现阶段关于 containerd 和 docker 选择问题可以查看这里。
[1] Don‘t Panic: Kubernetes and Docker
[2] Dockershim FAQ
[3] Dockershim Removal Kubernetes Enhancement Proposal
K8s 终将废弃 docker,TKE 早已支持 containerd
标签:抽象 纯粹 daemon too https eps lua 构建 time
原文地址:https://blog.51cto.com/14120339/2564061