标签:BMI sre 移动 win ted mode tfs make util
1、提交任务
//提交任务直到返回结果
job.waitForCompletion(true);
2、点击waitForCompletion方法到Job.java类
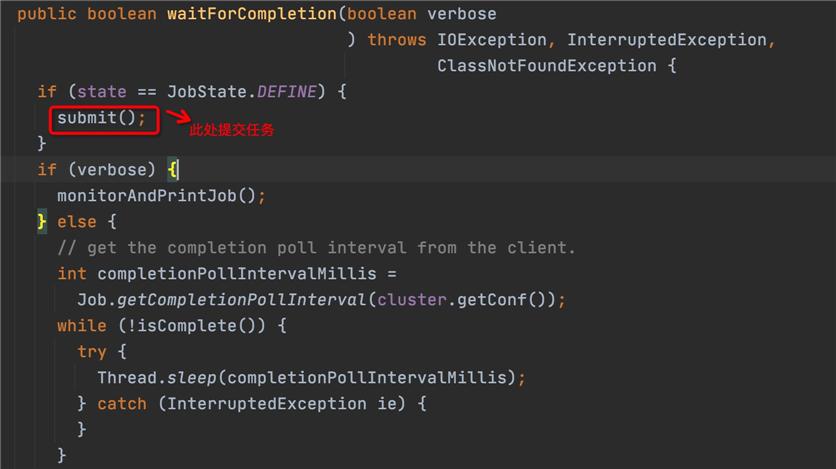
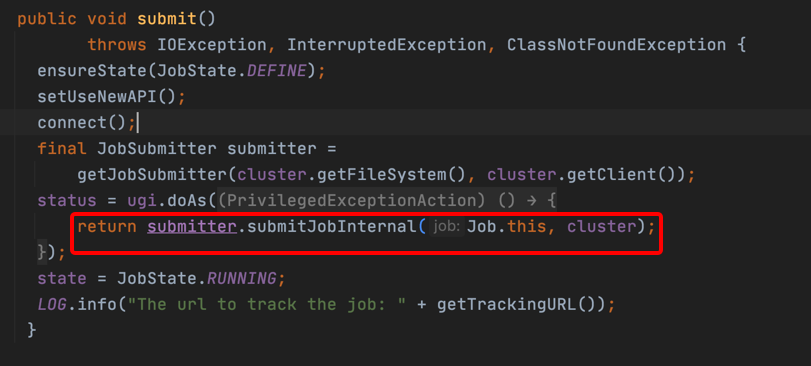
3、跟进到submit方法,调用方法:
return submitter.submitJobInternal(Job.this, cluster);
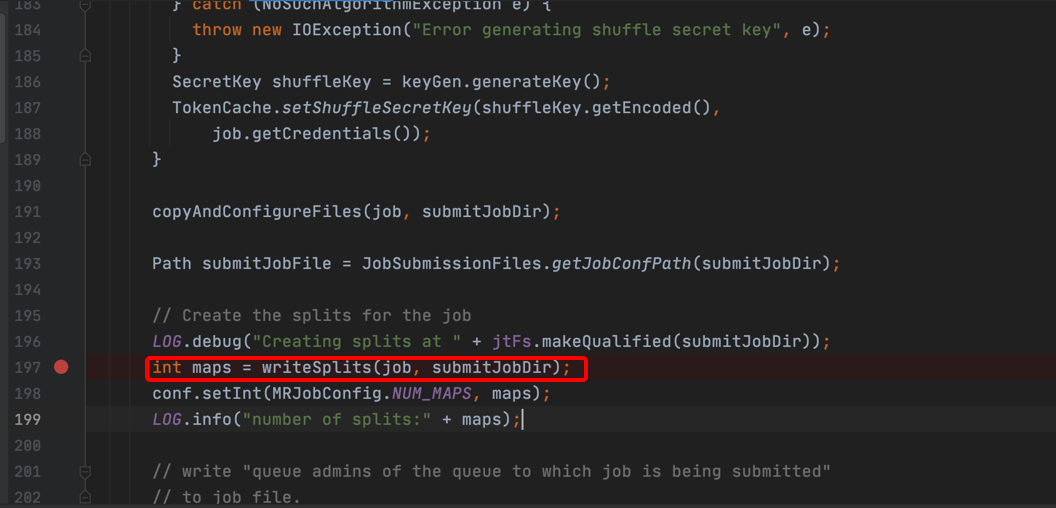
4、跟进submitJobInternal方法,跳转到JobSubmitter.java的submitJobInternal方法,经过读取配置和设置、上传信息到HDFS,开始写分片信息:
// Create the splits for the job
LOG.debug("Creating splits at " + jtFs.makeQualified(submitJobDir));
int maps = writeSplits(job, submitJobDir);
conf.setInt(MRJobConfig.NUM_MAPS, maps);
LOG.info("number of splits:" + maps);
5、跟进到writeSplits方法,2.X会走writeNewSplits分支。
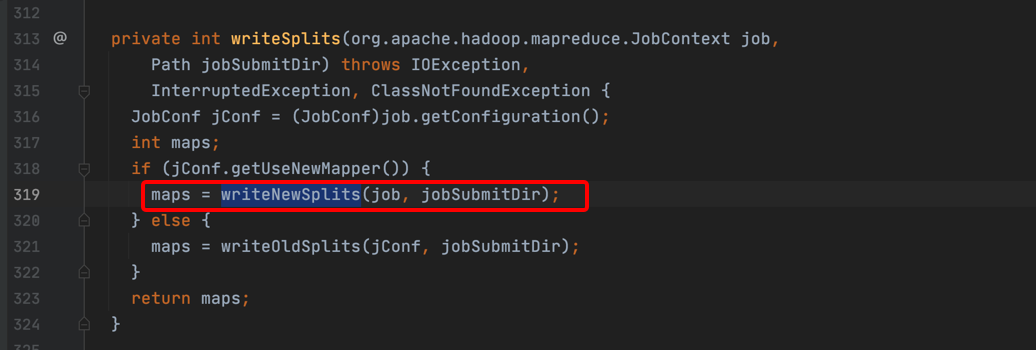
6、跟进到writeNewSplits方法,可以看到会通过反射创建一个输入类型实例。
InputFormat<?, ?> input =
ReflectionUtils.newInstance(job.getInputFormatClass(), conf);
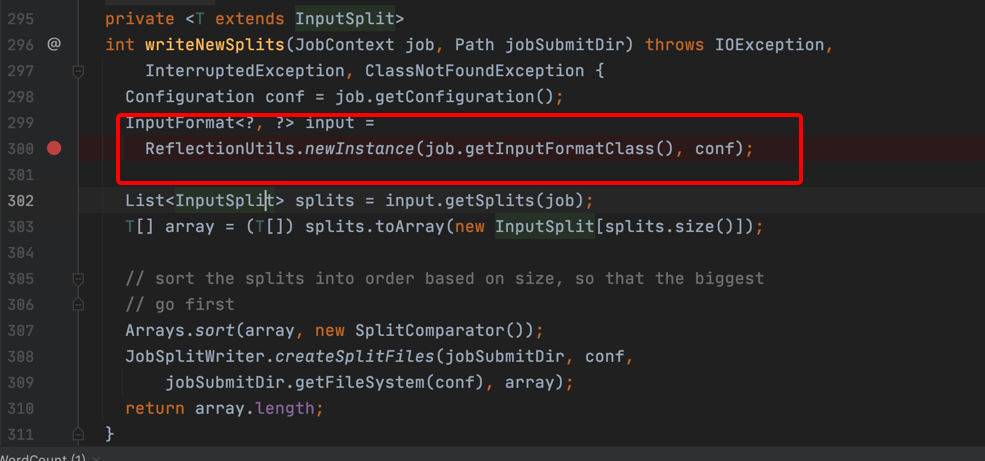
7、跟进到getInputFormatClass方法,会跳转到JobContext.java,是一个接口,不会实现getInputFormatClass方法。
/**
* Get the {@link InputFormat} class for the job.
*
* @return the {@link InputFormat} class for the job.
*/
public Class<? extends InputFormat<?,?>> getInputFormatClass()
throws ClassNotFoundException;
点击其实现类,JobContextImpl.java
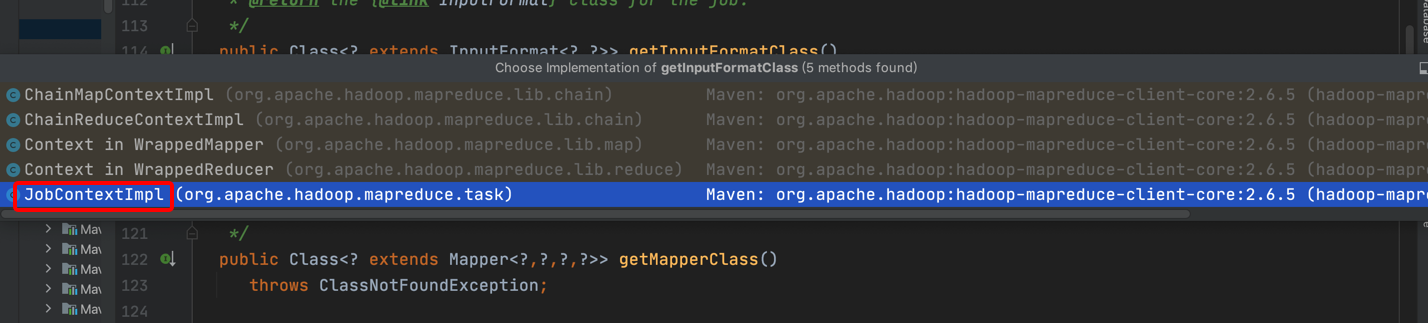
public Class<? extends InputFormat<?,?>> getInputFormatClass()
throws ClassNotFoundException {
return (Class<? extends InputFormat<?,?>>)
conf.getClass(INPUT_FORMAT_CLASS_ATTR, TextInputFormat.class);
}
可以看到conf.getClass(INPUT_FORMAT_CLASS_ATTR, TextInputFormat.class);如果不设置输入类型,hadoop默认为TextInputFormat
其继承关系如下:
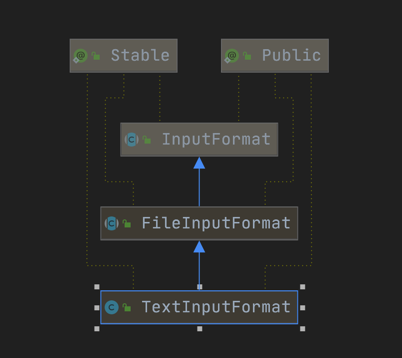
到此,获取到了InputFormatClass。
8、在获取输入类型的,回到writeNewSplits方法中继续执行,如下代码开始获取分片:
List<InputSplit> splits = input.getSplits(job);
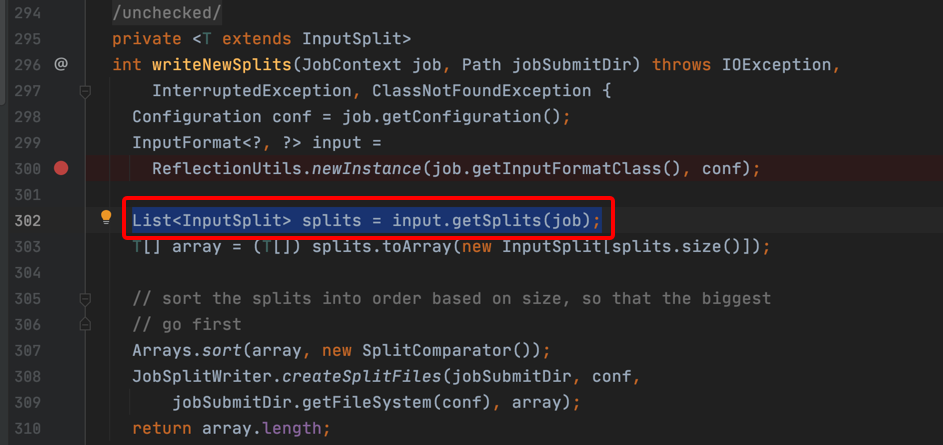
9、跟进到input.getSplits方法,跳转到InputFormat.java抽象类里,也没有实现这个方法。
查找其实现类,发现在FileInputFormat子类里有实现。
10、跟进到FileInputFormat子类里的实现,首先获取split的minSize和maxSize
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
long maxSize = getMaxSplitSize(job);
跟进到getFormatMinSplitSize,代码如下,直接返回1

跟进到getMinSplitSize(job)方法,代码如下:
public static long getMinSplitSize(JobContext job) {
return job.getConfiguration().getLong(SPLIT_MINSIZE, 1L);
}
参数SPLIT_MINSIZE,如果没有设置,也取1L
public static final String SPLIT_MINSIZE =
"mapreduce.input.fileinputformat.split.minsize";
所以总得来说splitSize默认最小值为1。
再跟进到getMaxSplitSize方法,代码如下:
public static long getMaxSplitSize(JobContext context) {
return context.getConfiguration().getLong(SPLIT_MAXSIZE,
Long.MAX_VALUE);
}
如果没有设置参数SPLIT_MAXSIZE,splitSize默认最大值为Long.MAX_VALUE。
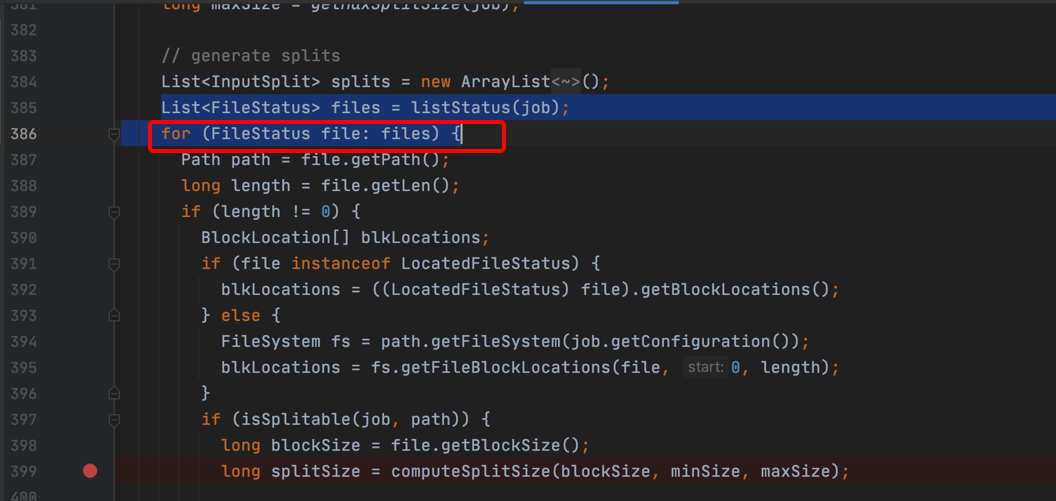
11、继续往下执行,针对每一个输入的文件进行遍历:
12、每次遍历文件,很重要的方法就是计算split大小,即computeSplitSize方法,跟进到这个方法的实现。
protected long computeSplitSize(long blockSize, long minSize,
long maxSize) {
return Math.max(minSize, Math.min(maxSize, blockSize));
}
通过这个逻辑,可以得出以下调整split大小的方法,如果要将split大小调整的比blockSize小,则调整maxSize大小比较blockSize值小即可。如果要将split大小调整到比blockSize大,则调整minSize的大小比blockSize值大即可。
13、继续执行,以下代码实现将生成分片与文件块的位置对应关系,为后续计算向数据移动,提供必要的信息。
long bytesRemaining = length;
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
bytesRemaining -= splitSize;
}
path:文件路径
length-bytesRemaining:split起始的offset
splitSize:split的大小,可以获取结束的offset blkLocations[blkIndex].getHosts():分片分布的主机。 blkLocations[blkIndex].getCachedHosts()):缓存
到此,client计算出split分配信息,为下一步map运算,计算向数据移动提供了需要的信息,至于如何移动,还要结合资源的情况。
mapreduce任务中client生成split的源码过程
标签:BMI sre 移动 win ted mode tfs make util
原文地址:https://www.cnblogs.com/windtalker/p/14141560.html