标签:价值 pytho 这不 出现 词汇 splash 简便 了解 新闻

我们的生活中有许多地方会用到概要。看书的时候,书背后的简要使我们大概了解其内容;新闻软件往往会有关于文章内容的标题;而概要对于影评来说也是特别重要的。
随着自然语言处理和机器学习等技术的出现,我们为何不用它们来生成概要而无需介入人力呢?在你决定为了即将到来的考试概括教材之前,先来了解一些重要的概念吧。
文本摘要有两类,抽取式和生成式。
抽取式摘要可被定义为精心挑选出所有重要的句子,并保持原样将其添加至摘要。
· 阅读文本,拆分成句子;
· 解析每个句子,根据某些参数识别其中更为重要的句子,将其打分;
· 选出分数更高的句子;
· 将这些句子添加至摘要。
生成式摘要更像是人们平常总结一个文本的方式,理解并分析文章。
· 阅读文本;
· 分析文本和句子背后的深意;
· 选出重要主题,创造新的句子(是否运用原文词汇是不确定的);
· 将这些这句添加至摘要。
两相比较,抽取式摘要更加简便一些,因为它不必考虑语义或词汇。本文将讨论抽取式摘要,再从头创造自己的文本摘要。

看到一句话,我们能轻易地确认它的内容以及试图表达的信息。但是,一台电脑无法做到。该怎么做呢?如上述所说,将句子分级,并选出级别最高的句子。谁来决定这些句子的级别?TF-IDF来决定。
词频-逆文档频率对于增添至最终摘要的句子选择来说是基础。TF-IDF的数值计算是这样的:词频-逆文档频率=术语频率×逆文档频率。
词频(TF)
词频计算的是文档中一个词语出现的次数。仅看词频得出的结果很有可能是不准确的,因为同样的单词(‘w’)在长文档中会比短文档出现更多次。但是,如果我们将其除以总字数的话,最终数据便会变得更准确,这使词频得出的数量对我们来说更有价值。
词频(w,d)=某词‘w’在文档中的出现次数/该文档的总字数‘d’
这就结束了不是吗,为什么还需要其他计算呢?如果你仔细想想,特别常见的词(如“is,am,was”)的词频值会非常高。词频本身在这种情况下会变得很多余,这个时候就需要我们的救星IDF了。
在开始IDF之前,先讨论一下文档频率(DF)。DF是指在共N个文档中包含某词‘w’的文档数量,字母D即所有文档。
文档频率(w, D)=包含单词‘w’的文档数量
然而,文档频率并不是我们关注的内容,反之才相关。逆文档频率揭晓每个术语承载了多少信息。在逆文档效率的作用结果中,常见词将会有很低的IDF值,而少见的术语会有更高优先级。我们之所以使用这个数值的算法是因为,对于大型文档而言该术语的数值会异常升高。
IDF(w, D)=log(N/(DF(w, D)+1))
用(DF+1)作分母,以避免分母为零。在某些情况下,分母为零会导致严重的错误。
TF-IDF(w,d)=TF(w,d)*log(N/(DF+1))
所有计算完成后,根据TF-IDF分数和阈值将每个文档(在此处是句子)分级,最终得出文本的摘要。那么,现在开始编码吧!
输入库:

清扫文本:
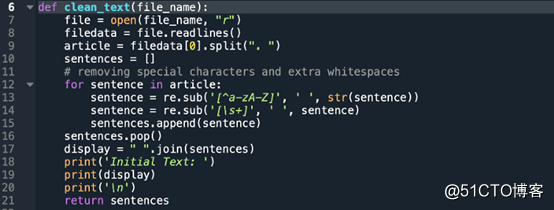
将文本文件转为一个个句子,这将成为我们的文档。
每个句子中的单词数量:
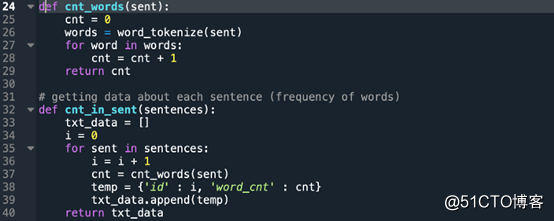
为所有文档中的每个单词创建频率列表:
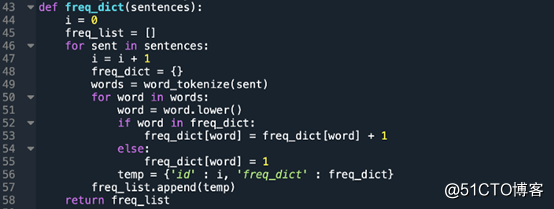
此处创建一个列表,其中存储了文档中每个单词的频率。
计算TF和IDF值:
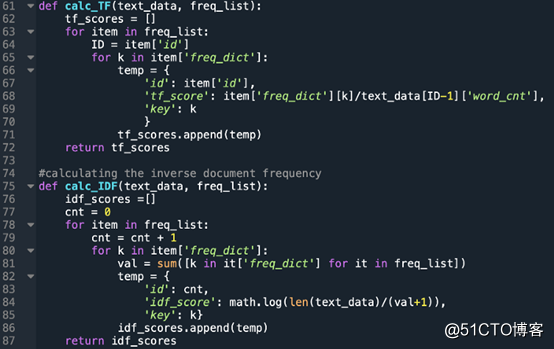
第一个功能计算每个文档(此处指句子)中单词的词频,第二个功能计算句子中每个单词的逆文档频率。
记算TF-IDF值:
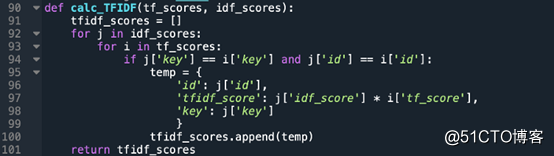
计算每个术语的TF-IDF值。
将所有文档分级:
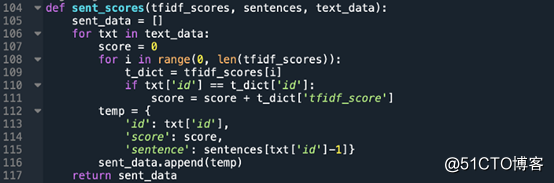
阈值根据句子中每个单词的TF-IDF值来计算每个句子的分数。
生成摘要:
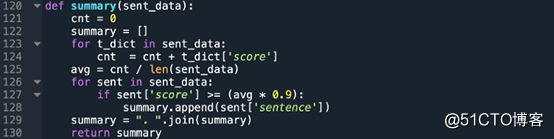
阈值是通过线性函数计算TF-IDF值的平均值得出。注意,平均值阈值可通过与标志相乘调整,以增减摘录规模。
是时候运行所有的功能啦!
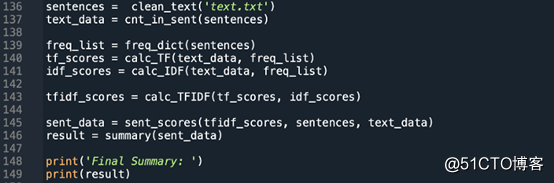
确保文档是在格式为(*.txt)的一个文件中,并和Python脚本在同一个目录中。
测试:
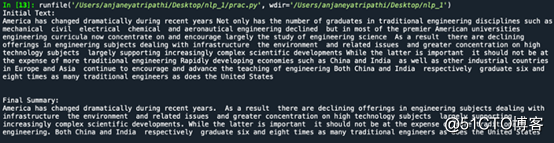
完成啦!不过这不是总结文本的唯一方式,除此之外还有很多技巧可以完成摘要。
一次美妙旅途的结束了,笔者感受到了很多乐趣,也希望你享受一起编程、学习文本摘要的过程。
编译组:石书宁、邓逸瑶
相关链接:
https://medium.com/spidernitt/how-to-build-a-text-summarizer-from-scratch-1a68e39558c4
如转载,请后台留言,遵守转载规范ACL2018论文集50篇解读
EMNLP2017论文集28篇论文解读
2018年AI三大顶会中国学术成果全链接
ACL2017论文集:34篇解读干货全在这里
10篇AAAI2017经典论文回顾长按识别二维码可添加关注
读芯君爱你

标签:价值 pytho 这不 出现 词汇 splash 简便 了解 新闻
原文地址:https://blog.51cto.com/15057819/2564768