标签:统计 一个人 智能 nas 成绩 2018年 实现 图表 要求

有人认为,数据科学就是创建可用来预测的模型。这句话可以这样理解:我们有了数据,探测发展模式,把这些再应用于预测未来,获得结果。这个逻辑说得通,其背后的理论,我们称之为统计。
整个历史长河中,有关预测的代名词先后涌现,比如数据挖掘、分析、商业智能、运筹学、新兴的数据科学。不过在这里我们没必要深究统计与数据科学之间是否能划等号,也大可不必对数据信息获取的无数流行词吹毛求疵。今天笔者想聊点儿别的。
你无法预测未来,这一点毋庸置疑,但你依然试图在用图表乐此不疲地做着预测。你认为数据中一定存在些信息,有偏差的“地图”总比没“地图”强吧。
在NassimTaleb最出名的一本书中,他借助隐喻说明人类之前对于预测未来的了解经不起推敲。多个世纪前,人们不相信这世上有黑天鹅的存在,因为从未有人见过。直到第一批探险队伍抵达澳大利亚,他们发现原来也会有黑色的羽毛。
单一只黑色家禽让多年存在的“白天鹅定律”不攻自破。哲学家Karl Popper(1902-1994)认为科学是彻底纠正理论的事业。Popper认为理论只可能是错的,我们会需要无数证据验证理论是否实事求是,但这不太可能。

你可能会说“这算个什么哲学,这也太糟糕了!”让实践来说明一切吧!看一下国际货币基金组织2020年1月份的GDP增速预测:
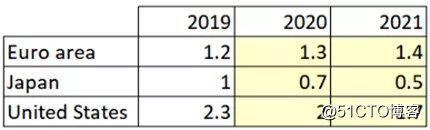
2020年1月IMF的GDP增速预测
这里是8月份的预测数据:
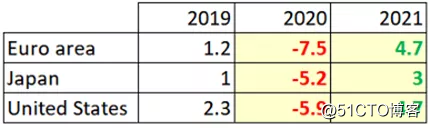
2020年8月IMF的GDP增速预测
他们怎么做到的短短几个月就可以迅速改变预测?2019年12月31日,中国报道了武汉“连续几件不明原因疫情”,几周后被称之为COVID-19,世界卫生组织将其升级为全球性流行病。由于该疾病会人传人,整个世界的经济会因此受到了影响。
国际货币基金组织是预测经济的一个前沿机构,它传达的信息变化非常快,会让你对任何预测产生怀疑。假如你碰巧是所谓的“数据科学家”,希望你在预测时也持有怀疑的态度。
你也许会认为IMF从来没打算准确预测未来,他们仅仅预测未来可能出现的情况从而帮助决策制定者。我同意你的说法,但关键是是稳增经济有过山车式发展的风险并未考虑在内。

图源:unsplash
IMF“单纯预估”会让决策制定者在未来几个月中错过最关键的信息。IMF并非没有能力预测或故意使坏,而是无法预测。这正是Taleb 想传达的:我们无法预测最重要的事件,因为没有消息指向。数据也不难获取,只是答案根本不在那!
对于黑天鹅事件,就算是数据也帮不了你。

股市几乎完全预测了近期的五次衰退。如果你还在臣服于数据科学的魔力,赶紧停下来吧。把时间投资在更容易获利的领域:股市。
股市对数据科学家来说是一个再好不过的环境了。有无数需要计算的数据,这些不仅是公共的资源,格式也正确。实际上,一些机器学习的文字介绍会将股市作为主要对象,建立最好的模型。
如果你的预测准确,就会赢得一大笔钱。抛售下行股票,买上行股票。很不幸,这不太能实现,我打赌。

图源:unsplash
根据S&P 的观点(一家追踪全世界平均股价的企业),“从以往来看,主动式管理基金在短期核长期以来不如基准”。主动式管理基金需要工作人员预测市场趋势,告知大家要卖哪个或买哪个股票。即便如此,他们也无法超越基准,所以只购买每只股票的一小部分来获取平均回报的人会更占优势。
用历史数据预测股市是贸易中的传统,这种方法属于技术分析。这个话题存在争议,时至今日一些人非常信誓旦旦地认为这个方法奏效。他们认为市场中有这样的趋势,许多亿万富翁的财富都要归功于数据信号的利用。
也许这是对的。或许股市中确有趋势,但80%的公司无法利用此途径,哪怕信息是真的,因为旧潮流后会有新的出现。事实证明世界是不断变化的,万事万物变化得飞快,所以任何预测都无济于事。
数据科学无法预测股市是真实情况。将“股市”变为“公司收益”、“客户选择”或其他老板让你预测的利益点,你还会认为自己预测的数字是好的吗?我们无法预测最重要的事情,哪怕这些事即将发生,小概率事件即使可以预测也提不出什么有价值的信息。

未来无法预测,但可以被创造。
就像我之前提到的,商业环境下从数据中抽取信息的历史长达整整两个世纪。所以我们就该预测到所谓正常情况下发生的事情。一个人必须是其领域中是最好的预测者,我们才会称之为专家。
Philip Tetlock开展了调查,想了解专家是否真的需要预测未来重要的事情。没有成绩的人如何能称之为专家呢?我认为,就算这些人不擅长预测,也是善于编造故事的,只挑选最有用的信息然后另创一个故事,这足以让很多人信服。
专家们都很谨慎,不会做一些容易被推翻的预测,不会告诉你准确的时间。他们一般会说“未来的路很难走”,怎么个难法留给大众去自行解读。
我们可以用数字撒谎。在数据科学家眼中,这不是需要解决的重要问题,而是他们工作的一部分。他们是在讲故事,现在用数字说服人也是一种技巧。或者用我最喜欢的TED讲者的话说,“再添几行,我会给你提供更多的数字”。

图源:unsplash
任一家公司的员工都会被要求做出成绩。在特特洛克看来,数据科学家很容易成为“专家”。在企业政治游戏中,一些分析师会运用各种编故事的技俩呈现最佳预测,即便是错误的关联、没有预测的能力,而且比不过测试数据集。
如果你从数据科学家那里得到了预测的话,问问你自己:这些数字在告诉我一些重要的事吗?还是特定程序给你呈现想要的结果?
事实如此不便多说,学术研究登记之前是有协议的。研究人员需要先提出问题再寻找答案,否则数据提示的信息都有可能成为答案。至少你要知道这些数字可能什么也说明不了,哪怕是背后的模型设计得再精密。

错误不代表完全没有价值,有用的东西蕴含在其中。在每天工作结束的时候,数据科学家给公司创造的价值就是:
· 没有预测重大事件或意外发生的事件——比如黑天鹅。
· 就算没有意外发生,数据中一定有一些重要的模式,这些模式可能无法继续利用,毕竟世界在变化——比如主动式基金。
· 即使某种方式会不断受用,预测结果可能只是个美好的谎言——比如“那些专家”。
不是说数据科学家没必要存在。我们会定决策,但得看是基于金钱还是数据,我倾向于后者。数据科学家越被鼓励进行实验,找到错误的速度就越快。

图源:unsplash
但如果你相信了宣传语投身数据的话,就大错特错了。独角兽企业这么做没问题,因为首先,关联并不代表因果;其次是无需为那些迷信数据圣经的公司的失败负责,用Taleb的话来说,这些公司深陷数字教条爬不出来了。
你可能觉得笔者有点儿偏激了,但我的目的在于:把你带离数据驱动的乌托邦世界。数据科学并非灵丹妙药,它也有许多缺点,需要抱有怀疑态度,请跳出迷信理解数据科学。
编译组:孙梦琪
相关链接:
https://towardsdatascience.com/data-science-is-a-lie-d9157b9ed29c
如转载,请后台留言,遵守转载规范ACL2018论文集50篇解读
EMNLP2017论文集28篇论文解读
2018年AI三大顶会中国学术成果全链接
ACL2017论文集:34篇解读干货全在这里
10篇AAAI2017经典论文回顾
标签:统计 一个人 智能 nas 成绩 2018年 实现 图表 要求
原文地址:https://blog.51cto.com/15057819/2565220