标签:降维 很多 机器学习算法 支持 随机梯度 情况下 可靠 模型 data

作为一切科学的基础,数学在数据科学领域也占据着重要地位。如果你是一名数据科学爱好者,一定想过这些问题:
· 我可以在几乎没有数学背景的情况下,成为一名数据科学家吗?
· 在数据科学中,哪些基本的数学技能是重要的?
有很多好用的包可以用来构建预测模型,或生成数据可视化。一些最常用的描述性分析和预测性分析包包括:Ggplot2、Matplotlib、Seaborn、Scikit-learn、Caret、TensorFlow、PyTorch、Keras等。
有了这些包,任何人都可以构建模型或者生成数据可视化。然而,想要微调模型,使之能产生具有最佳性能的可靠模型,确实需要非常扎实的数学基础知识。
建立模型是一回事,但是解释模型,并且总结出有意义的,且可用于数据驱动的决策制定的结论是另一回事。重要的是,在使用这些包之前,读者必须要对每一个包的数学基础有所了解,不仅限将这些包作为黑盒子工具来使用。

假设现在要建立一个多元回归模型。在此之前,我们需要问自己几个问题:
· 数据集有多大?
· 我的特征变量和目标变量是什么?
· 哪些预测特征与目标变量最相关?
· 哪些功能很重要?
· 应该缩放特征吗?
· 如何提高模型的预测能力?
· 应该使用正则回归模型吗?
· 回归系数是多少?
· 什么是拦截?
· 如何将数据集划分为训练集和测试集?
· 什么是主成分分析(PCA)?
· 应该使用主成分分析来删除冗余的特征吗?
· 应不应该使用非参数回归模型,如k邻近回归(或支持向量回归)?
· 模型中有哪些超参数,如何对它们进行微调以获得性能最优的模型?
· 如何评估模型?是用R2-score(决定系数),MSE(均方误差),还是MAE(平均绝对误差)?
图源:pixabay
没有良好的数学背景,就无法回答上述问题。在数据科学和机器学习中,数学技能和编程技能同等重要。作为一名数据科学爱好者,一定要投入时间来研究数据科学和机器学习的理论和数学基础。
能否建立可靠而有效的模型,使其应用于现实世界的问题,取决于读者的数学技能有多好。接下来我们来讨论一下在数据科学和机器学习中所需要的一些基本数学技能。

线性代数是机器学习中最重要的数学技能。数据集表示为矩阵,线性代数用于数据预处理、数据转换、降维和模型评估。
以下是大家需要熟悉的:向量;向量的范数;矩阵;矩阵的转置;逆矩阵;矩阵的行列式;矩阵的迹;点积;特征值;特征向量。

图源:pixabay
统计与概率用于特征可视化、数据预处理、特征转换、数据插补、降维、特征工程、模型评价等。
以下是大家需要熟悉的:均值、中值、模式、标准差/方差、相关系数和协方差矩阵、概率分布(二项式、泊松分布、正态分布)、p值、贝叶斯定理(精度、召回率、正预测值、负预测值、混淆矩阵、ROC曲线)、中心极限定理,R-2 score,均方误差(MSE),A/B检验,蒙特卡罗模拟。
大多数机器学习模型都是由一个具有多个特征或预测器的数据集建立的。因此,熟悉多变量微积分对于建立机器学习模型非常重要。
以下是大家需要熟悉的:多元函数;导数和梯度;阶跃函数、S形函数、Logit效用函数、ReLU(修正线性单元)函数;成本函数;函数绘图;函数的最小值和最大值。
大多数机器学习算法是通过最小化目标函数进行预测建模,从而学习为获得预测标签而必须应用于测试数据的权重。
以下是大家需要熟悉的:成本函数/目标函数;似然函数;误差函数;梯度下降算法及其变体(例如随机梯度下降算法)。
图源:pixabay
本文讨论了数据科学和机器学习所需的基本数学和理论技能。互联网时代,你能很轻松找到学习资源。作为数据科学爱好者一定要记住,数据科学的理论基础对于高效可靠的模型建立至关重要。你应该花足够的时间来钻研每种机器学习算法背后的数学理论,这对于数据科学来说是必不可少的。
编译组:王俊博、贺宇
相关链接:
https://medium.com/towards-artificial-intelligence/how-much-math-do-i-need-in-data-science-d05d83f8cb19
如转载,请后台留言,遵守转载规范ACL2018论文集50篇解读
EMNLP2017论文集28篇论文解读
2018年AI三大顶会中国学术成果全链接
ACL2017论文集:34篇解读干货全在这里
10篇AAAI2017经典论文回顾
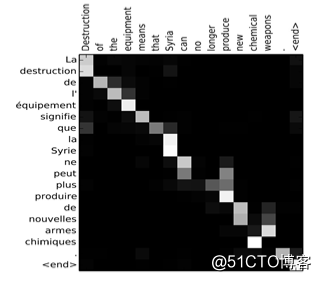
标签:降维 很多 机器学习算法 支持 随机梯度 情况下 可靠 模型 data
原文地址:https://blog.51cto.com/15057819/2565208