标签:合并 判断 城市 压缩 产品 art 图片 增量 永久

作者介绍
@Super超
空间计算与城市大数据
塑造未来的科幻迷
持续更新大数据与数据科学系列
上篇讲了大数据治理的背景、目标、核心,本篇进入实践环节,聊聊具体如何实施大数据治理、大数据治理的步骤及效果验证。
数据膨胀是大数据治理最先要解决的问题,它直接关系到成本问题,解法是进行存储优化,也就是设计规范化的存储策略,提高数据的共享程度。
从空间方面思考:
第一个关键词是合并,即合并冗余表。一方面是扫描数据表的依赖关系,上游表相似,表字段也相似,判断可能是冗余表,只留一个。另一方面把高度重合的表合并,从小表变大表。
第二个关键词是舍弃,即舍弃冗余字段。有些字段并没有多大存储意义,或者可以从其他来源处获取,可以从数据表中剔除。
第三个关键词是拆分,即内容压缩。例如通过一个数据压缩节点把大json字段拆分成几个内容字段,把格式相关的部分舍弃,需要还原的时候再通过数据解压缩节点逆向还原回来。平均可带来30%的存储空间释放。
从时间方面思考
第一个关键词是生命周期。合理规划数据的生命周期,不同层的数据保留时间不一样。有的需要永久保存,有的不需要永久保存。
第二个关键词是冷热。对于那些暂时没有业务调用的冷数据,压缩归档。
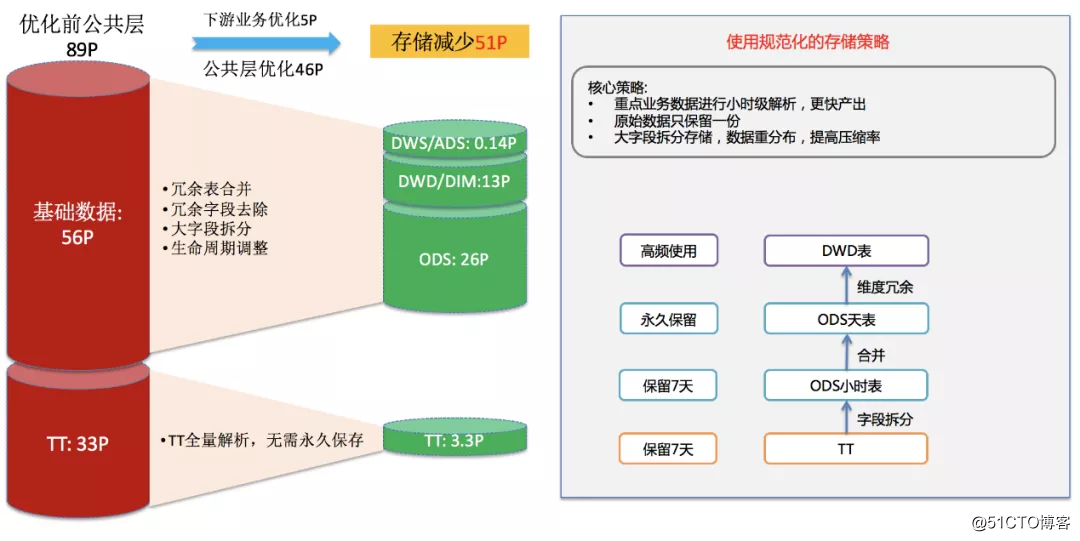
除了通用化的策略外,不同行业,不同类型的数据还有自身特性化的治理策略。例如设备在某一个位置停留时间过久,回传了大量的重复坐标。
计算优化的目的一是节省运算资源,二是提高数据加工处理的速度,缩短数据生产周期。
第一个优化点是避免在异常数据上浪费算力。有些数据虽然格式上没有问题,但实际上根据业务场景的定义是异常的,可以忽略。还例如某个设备是故障的,将它识别出来后它所产生的数据都不再参与计算。
第二个优化点是识别并应对数据倾斜。所谓数据倾斜有两种情况,一种是某一块区域的数据大于其他区域,另一种是某一些数据的大小要远远大于平均值。对存在数据倾斜的部分进一步分割,可以加速计算。
第三个优化点是提升核心UDF的性能。UDF 的性能很大程度上决定了处理流程的时间长短。通过代码审查,找出性能可以优化的节点进行代码优化。另外,将Python的UDF改成Java的UDF也可以提升一部分性能。
第四个优化点是引擎配置调优,例如开启数据压缩传输、合理设置map/reduce数、合理应用Hash/Range Cluster索引机制等。
第五个优化点是将MR streaming节点改写为SELECT TRANSFORM方式。SELECT TRANSFORM的性能很好,而且也更灵活,能够提高计算节点的可扩展性。
【拓展】SELECT TRANSFORM介绍
很多时候我们面对的是这么一种场景,SQL内置的函数不能支持把数据A变成数据B的功能,所以我们用一个脚本来实现,而我们又想让它分布式的执行。这样的场景可以用使用SELECT TRANSFORM来实现。
SELECT TRANSFORM功能允许SQL用户指定启动一个子进程,将输入数据按照一定的格式通过stdin输入子进程,并且通过解析子进程的stdout输出来获取输出数据。SELECT TRANSFORM非常灵活,不仅支持java和python,还支持shell,perl等其它脚本和工具。
大数据治理需要牵扯到大量的表和节点上线、下线、测试、添加监控等,如果每个环节都需要人工操作,都要耗费很多人力,因此使用一些自动化和半自动工具可以显著提高效率,减少人工成本。
主要涉及到了数据比对工具、节点批量下线工具、自动化测试工具等。
大数据治理与业务的正常发展是同步进行的,这就需要一个平滑的过渡过程。
业务的迁移按照灰度原则,先迁业务轻体量小的,后迁业务重体量大的。分批次迁移之后持续跟踪、分析数据波动情况,一旦发现问题及早修复,以保障数据质量的可靠性。
在增量数据上验证通过后,下一步就是迁移存量数据了。这一步需要关注的是存储空间的问题,一次性增加太多的新数据存储,旧数据来不及释放,会使得存储压力大增。
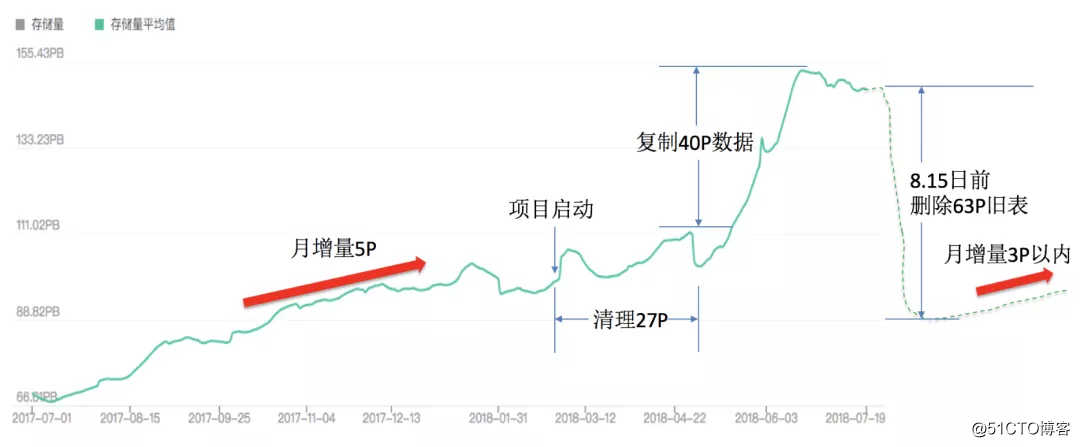
大数据治理的效果体现在数据存储成本是否降低、数据产出周期是否缩短、数据质量是否提高、数据量增长势头是否减缓等方面。
总结
大数据治理的过程是一个很好的梳理现有业务的机会。一次成功的数据治理不仅给企业带来成本、效能上的改善,还锻炼了数据团队,为数据价值体系建设奠定了基础。
一个数据人的自留地是一个助力数据人成长的大家庭,帮助对数据感兴趣的伙伴们明确学习方向、精准提升技能。关注我,带你探索数据的神奇奥秘
1、回“数据产品”,获取<大厂数据产品面试题>
2、回“数据中台”,获取<大厂数据中台资料>
3、回“商业分析”,获取<大厂商业分析面试题>;
4、回“交个朋友”,进交流群,认识更多的数据小伙伴。
标签:合并 判断 城市 压缩 产品 art 图片 增量 永久
原文地址:https://blog.51cto.com/13526224/2565937