标签:slave 负载 一个 生产 深度 主从 原来 tin 通过
前言
上文我们聊了基于Sentinel的Redis高可用架构,了解了Redis基于读写分离的主从架构,同时也知道当Redis的master发生故障之后,Sentinel集群是如何执行failover的,以及其执行failover的原理是什么。
这里大概再提一下,Sentinel集群会对Redis的主从架构中的Redis实例进行监控,一旦发现了master节点宕机了,就会选举出一个Sentinel节点来执行故障转移,从原来的slave节点中选举出一个,将其提升为master节点,然后让其他的节点去复制新选举出来的master节点。
你可能会觉得这样没有问题啊,甚至能够满足我们生产环境的使用需求了,那我们为什么还需要Redis Cluster呢?
为什么需要Redis Cluster
的确,在数据上,有replication副本做保证;可用性上,master宕机会自动的执行failover。
首先Redis Sentinel说白了也是基于主从复制,在主从复制中slave的数据是完全来自于master。
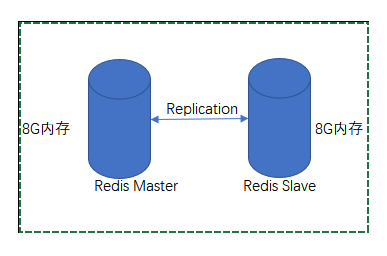
主从复制架构中是读写分离的,我们可以通过增加slave节点来扩展主从的读并发能力,但是写能力和存储能力是无法进行扩展的,就只能是master节点能够承载的上限。
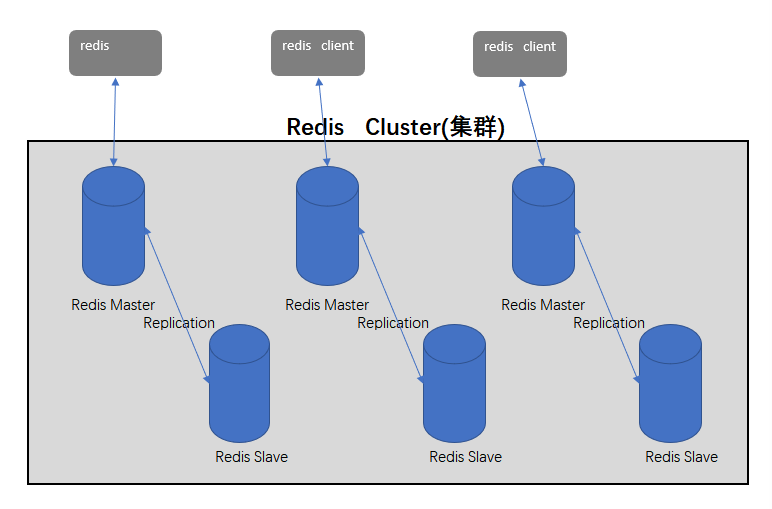
Redis Cluster是N个主从架构组合在一起对外服务,Redis Cluster要求至少3个Master,同时每个master至少需要有一个slave节点。们知道,主从架构中,可以通过增加slave节点的方式来扩展读请求的并发量,那Redis Cluster中是如何做的呢?虽然每个master下都挂载了一个slave节点,但是在Redis Cluster中的读、写请求其实都是在master上完成的。
slave节点只是充当了一个数据备份的角色,当master发生了宕机,就会将对应的slave节点提拔为master,来重新对外提供服务。

这么多的master节点。我存储的时候,到底该选择哪个节点呢?一般这种负载均衡算法,会选择哈希算法。哈希算法是怎么做的呢?
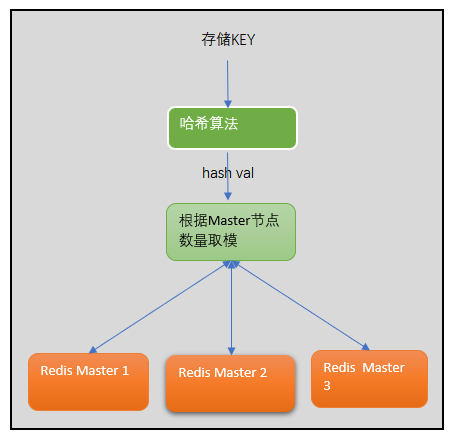
(1)对KEY计算出一个Hash值,然后用哈希值对Master数值进行取模,将KEY负载均衡到每一个Redis 节点上去,(
(2)Redis Cluster采取的时类似于一致性哈希的算法来实现节点选择的。

标签:slave 负载 一个 生产 深度 主从 原来 tin 通过
原文地址:https://www.cnblogs.com/yyuuee/p/14158820.html