标签:作用 十分 mat marker 表格 eve 取出 code str

大家好,我是卖萌屋的JayJay,好久不见啦~
最近在「夕小瑶@知识图谱与信息抽取」群里和群友交流时,JayJay发现了来自陈丹琦大佬(女神)的一篇最新的关系抽取SOTA《A Frustratingly Easy Approach for Joint Entity and Relation Extraction》,光看题目就让人眼前一亮:是啥子简单方法,让实体关系的联合抽取方法“沮丧”了?
仔细阅读原文后,发现这篇paper采取pipeline方式就超越了一众联合抽取模型(joint model),登顶ACE04/05、SciERC榜首!
也许你会问:咦?现在的关系抽取SOTA不都是各种joint方式吗?有木有搞错?JayJay也有各种疑问:
论文链接:
https://arxiv.org/pdf/2010.12812.pdf
Arxiv访问慢的小伙伴也可以在【夕小瑶的卖萌屋】订阅号后台回复关键词【1105】下载论文PDF~
这些年我们魔改过的joint模型
正式介绍本文的pipeline方法之前,我们先来回顾一下这些年我们魔改过的joint模型。实体关系的joint抽取模型可分为2大类:
第1类:多任务学习(共享参数的联合抽取模型)
多任务学习机制中,实体和关系共享同一个网络编码,但本质上仍然是采取pipeline的解码方式(故仍然存在误差传播问题)。近年来的大部分joint都采取这种共享参数的模式,集中在魔改各种Tag框架和解码方式。这里简单归纳几篇被大家熟知且容易实践的paper:
结构化预测则是一个全局优化问题,在推断的时候能够联合解码实体和关系(而不是像多任务学习那样,先抽取实体、再进行关系分类)。结构化预测的joint模型也有较多,比如统一的序列标注框架[4]、多轮QA+强化学习[5]等,不过有的联合解码方式通常很负责。
其实JayJay也有一段时间痴迷于各种joint魔改模型,如果大家有兴趣可以在知乎上直接搜索阅读JayJay的这篇文章《nlp中的实体关系抽取方法总结》。
如此简单的pipeline模型,居然可以登顶关系抽取SOTA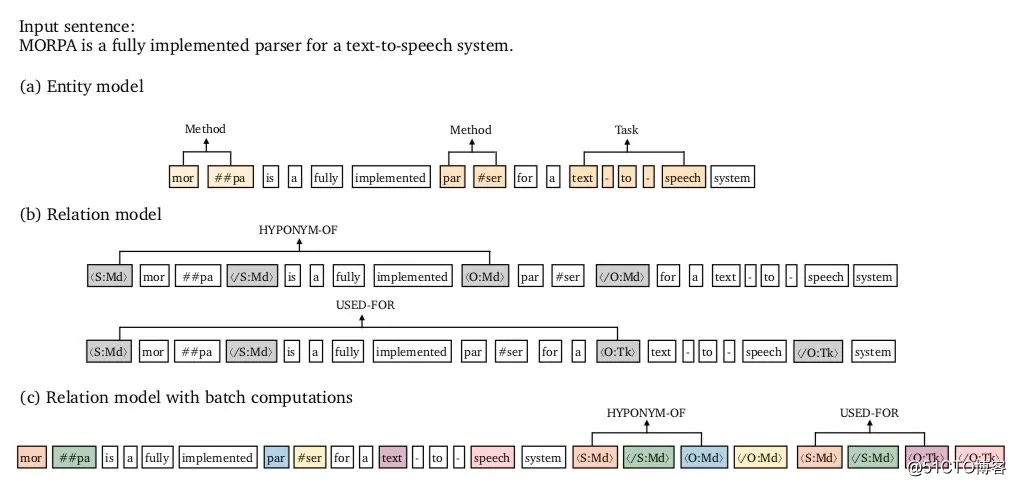
在这篇paper中,所采取的pipeline模型其实很简单:
需要特别指出的是,上述实体模型和关系模型采取的两个独立的预训练模型进行编码(不共享参数)。
对于这种关系模型,我们不难发现:对每个实体pair都要轮流进行关系分类,也就是同一文本要进行多次编码(呃~,心累,计算开销必然会很大啊)。
为解决这一问题,提出了一种加速的近似模型(如上图c所示):可将实体边界和类型的标识符放入到文本之后,然后与原文对应实体共享位置向量。上图中相同的颜色代表共享相同的位置向量。具体地,在attention层中,文本token只去attend文本token、不去attend标识符token,而标识符token可以attend原文token。综上,通过这种「近似模型」可以实现一次编码文本就可以判断所有实体pair间的关系。
此外,由于跨句信息可用于帮助预测实体类型和关系(尤其是在代词性提及中),所以还通过简单方式引入了跨句信息,即文本输入的左右上下文中分别滑动个words,为文本长度, 为固定窗口大小。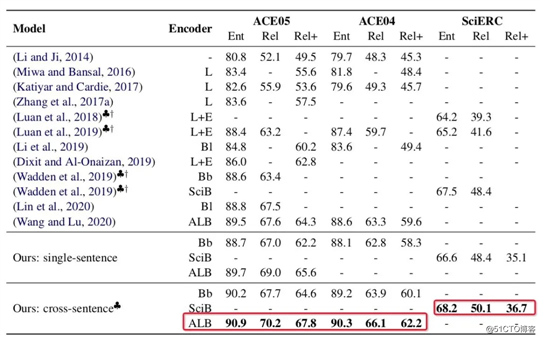
上图给出了各个关系抽取榜单的对比结果(梅花图标代表引入了跨句信息,Rel+为严格指标),可以看出:
使用跨句信息登顶了SciERC(文档级)的SOTA;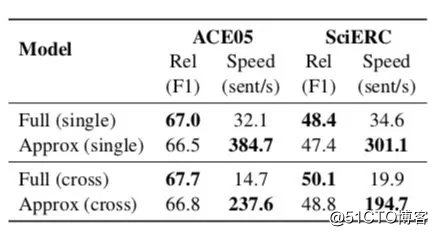
而上图也给出了加速版「近似模型」的效果,可以看出:
pipeline如此强悍,自有它的道理,也有“先兆”
pipeline为何如此强悍,是哪些因素让它可以“秒杀”众多joint模型?在这一部分我们以QA的形式逐一去揭晓(PS:最近几篇顶会paper中的论点,也和这篇SOTA互相佐证,原来早有先兆啊~)。
Q1、关系抽取最care什么?实体类型信息也太重要了吧
关系抽取最care什么?论文对关系模型起关键作用的因素进行了探究,首先就是分析不同实体表征方式的影响。文中共建了6种实体表征方式:
* TEXT*:直接提取原始文本中,实体span所对应的编码表示。
TEXTETYPE:在TEXT的基础上,concatenate实体类别向量。
MARKERS:将标识符S、/S、O、/O插入到原始文本中,但是标识符没有实体类别信息。
MARKERSETYPE**:在MARKERS的基础上,concatenate实体类别向量,这是一种隐式的融入实体类别的方法。
MARKERSELOSS:在关系模型中,构建判别实体类别的辅助loss。
* TYPEDMARKERS:就是本文所采取的方法,实体类别“显式”地插入到文本input中,如<S:Md> 和</S:Md>、<O:Md>和</O:Md>。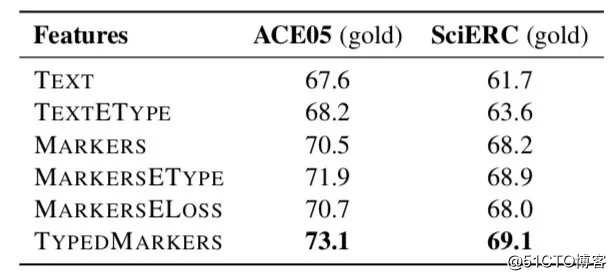
如上图所示(关系模型的实体是gold输入),我们可以发现:
JayJay还发现:实体类别信息对于关系模型很重要这一结论,在最新的EMNLP20的一篇刘知远老师团队的《Learning from Context or Names?An Empirical Study on Neural Relation Extraction》中也被提及和证明。
anyway,记住一点:引入实体类别信息会让你的关系模型有提升~
Q2、共享编码 VS 独立编码 哪家强?
在JayJay的刻板印象中:基于参数共享编码的joint模型能够建模实体和关系的交互、促进彼此。但这篇居然是采取两个独立的编码器分别构建实体模型和关系模型,WHY?
不过,论文也给出了两个模型共享编码进行联合优化的实验,如下图所示: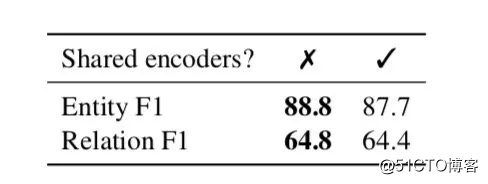
可以看出共享编码反而使实体和关系的F1都下降了,丹琦大佬也解释道:这是由于两个任务各自是不同的输入形式,并且需要不同的特征去进行实体和关系预测,也就是说:使用单独的编码器确实可以学习更好的特定任务特征。
不过,JayJay认为:不能一概而论地就认为独立编码就一定好于共享编码,或许是共享编码机制过于简单了呢?但不可否认,对于实体和关系确实需要特定的特征编码,在构建joint模型时如果只是简单的强行共享编码,真的可能会适得其反。
真是很巧,最近EMNLP20的一篇《Two are Better than One:Joint Entity and Relation Extraction with Table-Sequence Encoders》(这篇SOTA之前的SOTA)也认为:大多数joint模型都是共享同一个编码,但这种方式存在一个问题:针对一项任务提取的特征可能与针对另一项任务提取的特征一致或冲突,从而使学习模型混乱。于是乎,作者设计了2种不同的编码器(表格编码器和序列编码器),以在表示学习过程中互相帮助,最后通过实验表明使用2个编码器好于只使用1个编码。
anyway,记住一点:对于实体关系抽取,2个独立的编码器也许会更好~
Q3、误差传播不可避免?还是不存在?
众所周知,pipeline不是存在「误差传播」吗?也就是说,关系模型在训练的时候,输入的是gold实体进行关系判断,这会导致训练和推断时候的差异(暴露偏差)。
那是不是在训练的时候输入预测的实体进行关系判断,会在推断时效果变好呢?于是论文采用10-way jackknifing方式(一种交叉验证)做了相关实验,发现训练时输入预测实体反而降低了F1值,毕竟这种方式会在训练的时候引入噪音啊~
采取pipeline进行推断时,如果有些gold实体在实体模型中没有被抽取出来,那么关系模型也就不会预测与该实体相关联的任何关系了。那有没有可能通过召回更多的实体,来减轻这种误差传播呢?论文也尝试召回更多的实体进行了实验,发现并没有提升F1值。
通过上述实验发现一些尝试均未显着改善性能,而论文提出的简单的pipeline却证明是一种出乎意料的有效策略~但丹琦大佬也指出:并不认为误差传播问题不存在或无法解决,而需要探索更好的解决方案来解决此问题。
不过,JayJay认为:pipeline存在误差传播,而那些基于共享编码的joint模型也存在误差传播啊,至于是不是真的会减轻这种误差传播也有待考证。
anyway,留给我们的一个课题就是:误差传播怎么解决?
还好,我们NLPer一直在尝试。最近COLING2020的一篇paper[7]为了缓解这个问题,提出了一种单阶段的联合提取模型TPLinker,其不包含任何相互依赖的抽取步骤,因此避免了在训练时依赖于gold的情况,从而实现了训练和测试的一致性。是不是很神奇?感兴趣的小伙伴,赶快去阅读吧~
你打破“joint好于pipeline”的刻板印象了吗?
读完这篇SOTA,也许我们不会再有“joint好于pipeline”的感脚了。但这并不是说,joint就比不上pipeline了,或许我们未来可以设计出更好的joint框架还是会登顶SOTA。
对于JayJay来说,是不是SOTA其实没有那么重要~更重要的是,我们可以进一步尝试或验证这些trick:
* 引入实体类别信息会让你的关系模型有提升~*
对于实体关系抽取,2个独立的编码器也许会更好~**
当然还有一些需要我们进一步思考或解决的问题:
标签:作用 十分 mat marker 表格 eve 取出 code str
原文地址:https://blog.51cto.com/15061930/2567675