标签:原理 部署 首页 历史 code route 调优 async 另一个
大前端时代,如何做好C 端业务下的React ***?
作者|桑世龙(狼叔),阿里巴巴前端技术专家
编辑|覃云
React 在中后台业务里已经很好落地了,但对于 C 端(给用户使用的端,比如 PC/H5)业务有其特殊性,对性能要求比较苛刻,且有 SEO 需求。另外团队层面也希望能够统一技术栈,小伙伴们希望成长,那么如何能够完成既要、也要、还要呢?
本次分享主要围绕 C 端业务下得 React *** 实践,会讲解各种 *** 方案,包括 Next.js 同构开发,并以一次优化的过程作为实例进行讲解。其实这些铺垫都是在工作中做的 Web 框架的设计而衍生出来的总结。这里先卖个关子,自研框架基于 Umi 框架并支持 *** 的相关内容留到广州 QCon 上讲。下面开始正题。
曾和小弟讨论什么是 ***?他开始以为 React *** 就是 ***,这是不完全对的,忽略了 Server-side Render 的本质。其实从早期的 cgi,到 PHP、ASP,jsp 等 server page,这些动态网页技术都是服务器端渲染的。而 React *** 更多是强调基于 React 技术栈进行的服务器端渲染,是服务器端渲染的分类之一,本文会以 React *** 为主进行讲解。
对于 ***,大家的认知大概是以下 3 个方面。
*** 看起来很简单,如果细分一下,还是略微负责的,下面和我一起看一下从 CSR 到 *** 演进之路。
客户端渲染 (CSR)
客户端渲染是目前最简单的开发方式,以 React 为例,CSR 里所有逻辑,数据获取、模板编译、路由等都是在浏览器做的。
Webpack 在工程化与构建方便提供了足够多便利,除了提供 Loader 和 Plugin 机制外,还将所有构建相关步骤都进行了封装,甚至连模块按需加载都内置,还具备 Tree-shaking 等能力,外加 Node cluster 利用多核并行构建。很明显这是非常方便的,对前端意义重大的。开发者只需要关注业务模块即可。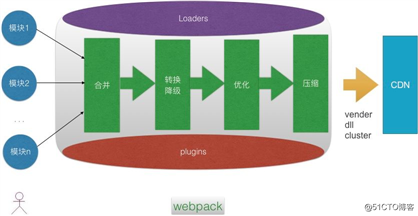
常见做法是本地通过 Webpack 打包出 bundle.js,嵌入到简单的 HTML 模板里,然后将 HTML 和 bundle.js 都发布到 CDN 上。这样开发方式是目前最常见的,对于做一些内部使用的管理系统是够的。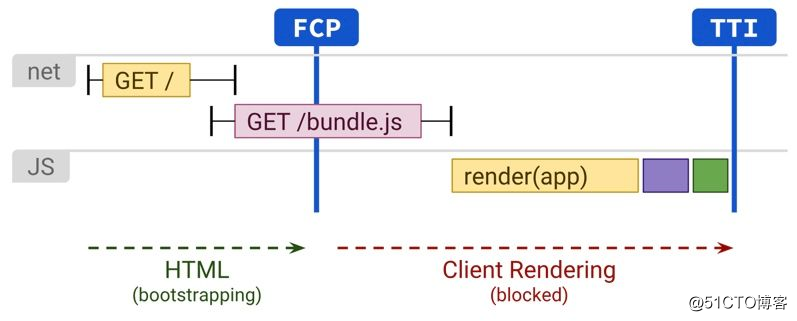
CSR 缺点也是非常明显的,首屏性能无法保障,毕竟 React 全家桶基础库就很大,外加业务模块,纵使按需加载,依然很难保证秒开的。
为了优化 CSR 性能,业界有很多最佳实践。在 2018 年,笔者以为 React 最成功的项目是 CRA(create-react-app),支付宝开发的 Umi 其实也是类似的。他们通过内置 Webpack 和常见 Webpack 中间件,解决了 Webpack 过于分散的问题。通过约定目录,统一开发者的开发习惯。
与此同时,也产生了很多与时俱进的最佳实践。使用 react-router 结合 react-loadable,更优雅的做 dynamic import。在页面中切换路由时按需加载,在 Webpack 中做过代码分割,这是极好的实践。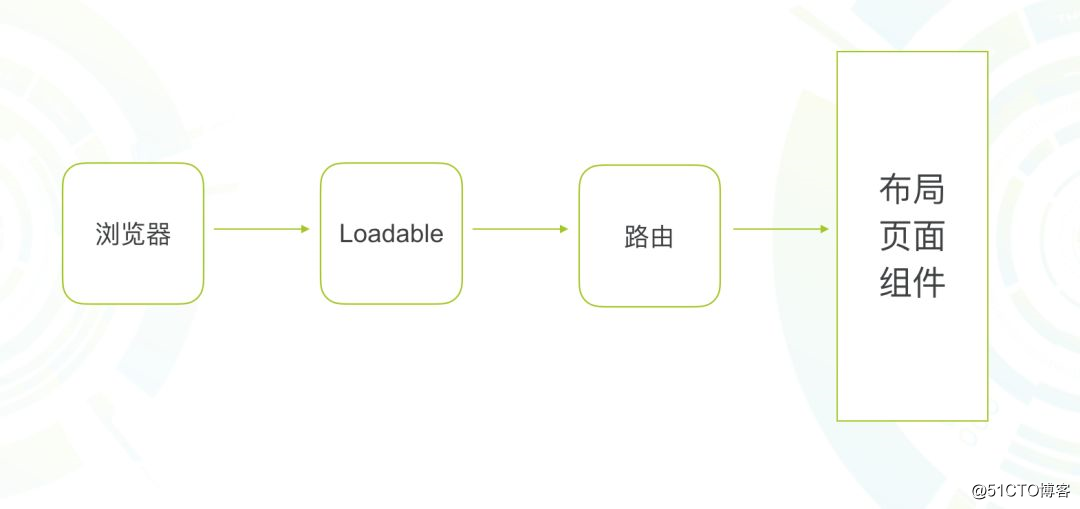
以前是打包 bundle 是非常大的,现在以路由为切分标准,按需加载,效率自然是高的。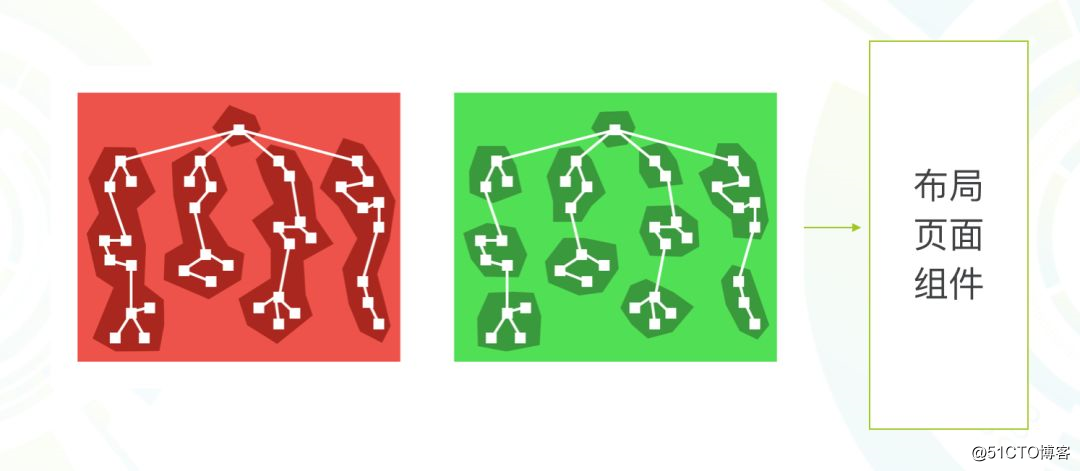
Umi 基于 react-router 又进步增强了,约定页面有布局的概念。
export default {
routes: [
{ path: ‘/‘, component: ‘./a‘ },
{ path: ‘/list‘, component: ‘./b‘, Routes: [‘./routes/PrivateRoute.js‘] },
{ path: ‘/users‘, component: ‘./users/_layout‘,
routes: [
{ path: ‘/users/detail‘, component: ‘./users/detail‘ },
{ path: ‘/users/:id‘, component: ‘./users/id‘ }
]
},
],
};这样做的好处,就有点模板引擎中 include 类似的效果。布局提效也是极其明显的。为了演示优化后的效果,这里以 Umi 为例。它首先会加载 index 页面,找到 index 布局,先加载布局,然后再加载 index 页面里的组件。下图加了断点,你可以很清楚的看出加载过程。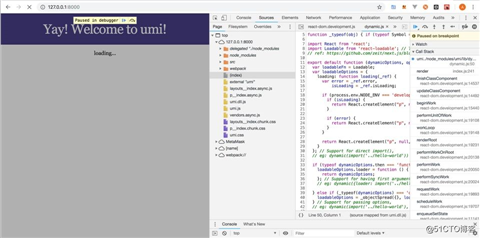
在 create-react-app(cra)和 Umi 类似,都是通过约定,隐藏具体实现细节,让开发者不需要关注构建。在未来,类似的封装还会有更多的封装,偏于应用层面。笔者以为前端开发成本在降低,未来有可能规模化的,因为框架一旦稳定,就有大量培训跟进,导致规模化开发。这是把双刃剑,能满足企业开发和招人的问题,但也在创新探索领域上了枷锁。
SPA(单页面应用) 的主要内容都依赖于 JavaScript(bundle.js) 的执行,当首页 HTML 下载下来的时候,并不是完整的页面,而是浏览器里加载 HTML 并 JavaScript 文件才能完成渲染。用户在访问的时候体验会很好,但是对于搜索引擎是不好收录的,因为它们不能执行 JavaScript,这种场景下预渲染 (Prerending) 就派上用场了,它可以帮忙把页面渲染完成之后再返回给爬虫工具,我们的页面也就能被解析到了。
CSR 是由 bundle.js 来控制渲染的,所以它外层的 HTML 都很薄。对于首屏渲染来说,如果能够先展示一部分布局内容,然后在走 CSR 的其他加载,效果会更好。另外业内有太多类似的事件了,比如用 less 写 css,coffee 写 js,用 markdown 写博客,都是需要编译一次才能使用的。比如 Jekyll/Hexo 等著名项目,它们都非常好用。那么基于 React 技术,也必然会做预处理的,Gatsby/Next.js 都有类似的功能。将 React 组建编译成 HTML,可以编译全部,也可以只编译布局,对于页面性能来说,预渲染是非常简单的提升手段。其原理 JSX 模板和 Webpack stats 结合,进行预编译。
编译全部:纯静态页面。
只编译布局:对于 SPA 类项目是非常好,当然多页应用也可以只编译布局的。
生成纯 HTML,可以直接放到 CDN 上,这是简单的静态渲染。如果不直接生成 HTML,由 Node.js 来接管,那么就可以转换为简单的 ***。
无论 CSR 还是静态渲染,都不得不面对数据获取问题。如果 bundle.js 加载完成,Ajax 再获取的话,整个过程还要增加 50ms 以上的交互时间。如果预先能够得到数据,肯定是更好的。
类似上图中的数据,放在 Node.js 层去获取,并注入到页面,是服务器端渲染最常用的手段,当然,服务器端远不止这么简单。
纯服务器渲染其实很简单,就是服务器向浏览器写入 HTML。典型的 CGI 或 ASP、PHP、JSP 这些都算,其核心原理就是模板 + 数据,最终编译为 HTML 并写入到浏览器。
第一种方式是直接将 HTML 写入到浏览器,具体如下。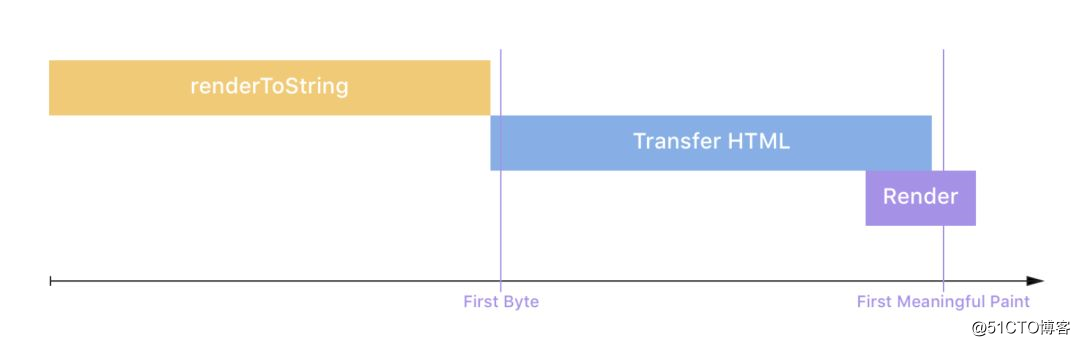
上图中的 renderToString 是 react *** 的 API,可以理解成将 React 组件编译成 HTML 字符串,通俗点,可以理解 React 就是当模板使用。在服务器向浏览器写入的第一个字节,就是 TTFB 时间,然后网络传输时间,然后浏览器渲染,一般关注首屏渲染。如果一次将所有 HTML 写入到浏览器,可能会比较大,在编译 React 组件和网络传输时间上会比较长,渲染时间也会拉长。
第二种方式是就采用 Bigpipe 进行分块传输,虽然 Bigpipe 是一个相对比较”古老“的技术,但在实战中还是非常好用的。在 Node.js 里,默认 res.write 就支持分块传输,所以使用 Node.js 做 Bigpipe 是非常合适的,在去哪儿的 PC 业务里就大量使用这种方式。
以上 2 种方法都是服务器渲染,在没有客户端 bundle.js 助力的情况下,第一种情况除了首屏后懒加载外,客户端能做的事儿不多。第二种情况下,还是有手段可以用的,比如在分块里写入脚本,可以做的的事情还是很多的。
res.write("<script>alert(‘something‘)</script>")渐进混搭法是将 CSR 和 *** 一起使用的方式。*** 负责接口请求和首屏渲染,并客户端准备数据或配合完成某些生命周期的操作。
首先,在服务器端生成布局文件,用于首屏渲染,在布局文件里会嵌入 bundle.js。当页面加载 bundle.js 成功后,客户端渲染就开始了。通常客户端渲染过程都会在 domReady 之前,所以优化效果是极其明显的。
Bigpipe 可以使用在分块里写入脚本,在 React *** 里也可以使用 renderToNodeStream 搞定。React 16 现在支持直接渲染到节点流。渲染到流可以减少你的内容的第一个字节(TTFB)的时间,在文档的下一部分生成之前,将文档的开头至结尾发送到浏览器。当内容从服务器流式传输时,浏览器将开始解析 HTML 文档。渲染到流的另一个好处是能够响应。 实际上,这意味着如果网络被备份并且不能接受更多的字节,则渲染器会获得信号并暂停渲染,直到堵塞清除。这意味着您的服务器使用更少的内存,并更加适应 I / O 条件,这两者都可以帮助您的服务器处于具有挑战性的条件。
最简单的示例,你只需要 stream.pipe(res, { end: false })。
// 服务器端
// using Express
import { renderToNodeStream } from "react-dom/server"
import MyPage from "./MyPage"
app.get("/", (req, res) => {
res.write("<!DOCTYPE HTML><HTML><head><title>My Page</title></head><body>");
res.write("<div id=‘content‘>");
const stream = renderToNodeStream(<MyPage/>);
stream.pipe(res, { end: false });
stream.on(‘end‘, () => {
res.write("</div></body></HTML>");
res.end();
});
});当 MyPage 组件的 HTML 片段写到浏览器里,你需要通过 hydrate 进行绑定。
// 浏览器端
import { hydrate } from "react-dom"
import MyPage from "./MyPage"
hydrate(<MyPage/>, document.getElementById("content"))至此,你大概能够了解 React *** 的原理了。服务器编译后的组件更多的是偏于 HTML 模板,而具体事件和 vdom 操作需要依赖前端 bundle.js 做,即前端 hydrate 时需要做的事儿。 可是,如果有多个组件,需要写入多次流呢?使用 renderToString 就简单很多,普通模板的方式,流却使得这种玩法变得很麻烦。
React *** 里还有一个新增 API:renderToNodeStream,结合 Stream 也能实现 Bigpipe 一样的效果,而且可以有效的提高 TTFB 时间。
伪代码:
const stream1 = renderToNodeStream(<MyPage/>);
const stream2 = renderToNodeStream(<MyTab/>);
res.write(stream1)
res.write(stream2)
res.end()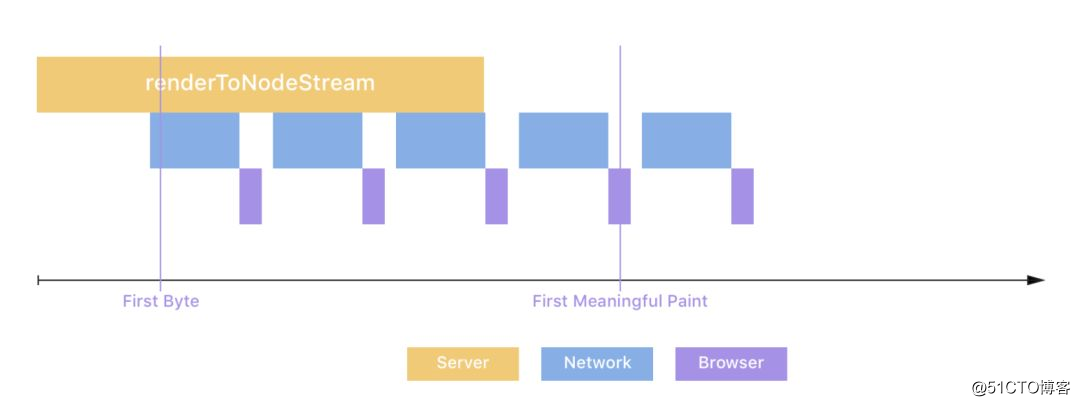
如果每个 React 组件都用 renderToNodeStream 编译,并写入浏览器,那么流的优势就极其明显了,边读边写,都是内存操作,效率非常高。后端写入一个 React 组件,前端就 hydrate 绑定一下,如此循环往复,其做法和 Bigpipe 如出一辙。
Node.js 成熟的标志是以 MEAN 架构开始替换 LAMP。在 MEAN 之后,很多关于同构的探索层出不穷,比如 Meteor,将同构进程的非常彻底,使用 JavaScript 搞定前后端,开创性的提出了 Realtime、Date on the Wire、Database Everywhere、Latency Compensation,零部署等特性,其核心还是围绕 Full Stack Reactivity 做的,这里不展开。简言之,当数据发生改变的时候,所有依赖该数据的地方自动发生相应的改变。本身这些概念是很牛的,参与的开发者也都很牛,但问题是过于超前了。熟悉 Node.js 又熟悉前端的人那时候还没那么多,所以前期开发是非常快的,但一旦遇到问题,调试和解决的成本高,过程是非常难受的。所以至今发布了 Meteor 1.8 也是不温不火的情况。
Next.js 是一个轻量级的 React 应用框架。这里需要强调一下,它不只是 React 服务端渲染框架。它几乎覆盖了 CSR 和 *** 的绝大部分场景。Next.js 自己实现的路由,然后 react-loadable 进行按照路由进行代码分割,整体效果是非常不错的。Next.js 约定组件写法,在 React 组件上,增加静态的 getInitialProps 方法,用于 API 请求处理之用。这样做,相当于将 API 和渲染分开,API 获得的结果作为 props 传给 React 组件,可以说,这种设计确实很赞,可圈可点。
Nextjs 式的一键开启 CSR 和 ***,比如下面这段代码。
import React from ‘react‘
import Link from ‘next/link‘
import ‘isomorphic-unfetch‘
export default class Index extends React.Component {
static async getInitialProps () {
// eslint-disable-next-line no-undef
const res = await fetch(‘https://api.github.com/repos/zeit/next.js‘)
const json = await res.json()
return { stars: json.stargazers_count }
}
render () {
return (
<div>
<p>Next.js has {this.props.stars} ??</p>
<Link prefetch href=‘/preact‘>
<a>How about preact?</a>
</Link>
</div>
)
}
}在 scr/pages/*.js 都是遵守文件名即 path 的做法,内部使用 react-router 封装。在执行过程中:
用 *** 最大的问题是场景区分,如果区分不好,还是非常容易有性能问题的。上面 5 种渲染方式里,预渲染里可以使用服务器端路由,此时无任何问题,就当普通的静态托管服务就好,如果在递进一点,你可以把它理解成是 Web 模板渲染。这里重点讲一下混搭法和纯 ***。
混搭法通常只有简单请求,能玩的事情有限。一般是 Node.js 请求接口,然后渲染首屏,在正常情况性能很好的,TTFB 很好,整体 rt 也很短,使用于简单的场景。此时最怕 API 组装,如果是几个 API 组合在一起,然后在返回首屏,就会导致 rt 很长,性能下降的非常明显。当然,也可以解,你需要加缓存策略,减少不必要的网络请求,将结果放到 Redis 里。另外将一些个性化需求,比如千人千面的推荐放到页面中做懒加载。
如果是纯服务器渲染,那么要求会更加苛刻,有时 rt 有 10 几秒,甚至更长,此时要保证 QPS 还是有很大难度的。除了合并接口,对接口进行缓存,还能做的就是对页面模块进行分级处理,从布局,核心展示模块,以及其他模块。
除了上面这些业务方法外,剩下的就是 Node.js 自身的性能调优了。比如内存溢出,耗时函数定位等,cpu 采样等,推荐使用成熟的 alinode 和 node-clinic。毕竟 Node.js 专项性能调优模块过多,不如直接用这种套装方案。
Node.js 在大前端布局里意义重大,除了基本构建和 Web 服务外,这里我还想讲 2 点。首先它打破了原有的前端边界,之前应用开发只分前端和 API 开发。但通过引入 Node.js 做 BFF 这样的 API Proxy 中间层,使 API 开发也成了前端的工作范围,让后端同学专注于开发 RPC 服务,很明显这样明确的分工是极好的。其次,在前端开发过程中,有很多问题不依赖服务器端是做不到的,比如场景的性能优化,在使用 React 后,导致 bundle 过大,首屏渲染时间过长,而且存在 SEO 问题,这时候使用 Node.js 做 *** 就是非常好的。
当然,前端开发使用 Node.js 还是存在一些成本,要了解运维等技能,会略微复杂一些,不过也有解决方案,比如 Servlerless 就可以降级运维成本,又能完成前端开发。直白点讲,在已有 Node.js 拓展的边界内,降级运维成本,提高开发的灵活性,这一定会是一个大趋势。
未来,API Proxy 层和 *** 都真正的落在 Servlerless,对于前端的演进会更上一层楼。向前是 *** 渲染,先后是 API 包装,***兼备,提效利器,自然是趋势。
标签:原理 部署 首页 历史 code route 调优 async 另一个
原文地址:https://blog.51cto.com/15057848/2567665