标签:验证 技巧 比例 两种 img src 情况 重复 上进

单位 | 追一科技
编 | 兔子酱
不管是打比赛、做实验还是搞工程,我们经常会遇到训练集与测试集分布不一致的情况。一般来说我们会从训练集中划分出来一个验证集,通过这个验证集来调整一些超参数[1],比如控制模型的训练轮数以防止过拟合。然而,如果验证集本身跟测试集差别比较大,那么验证集上很好的模型也不代表在测试集上很好,因此如何让划分出来的验证集跟测试集的分布差异更小一些,是一个值得研究的题目。
为什么分布不一致
首先,明确一下本文所考虑的场景,就是我们只有测试集数据本身、但不知道测试集标签的场景。如果是那种提交模型封闭评测的场景,我们完全看不到测试集的,那就没什么办法了。为什么会出现测试集跟训练集分布不一致的现象呢?主要有两种情况。
第一种是标签的分布不一致。如果只看输入x,分布基本上是差不多的,但是对应的y分布不一样。典型的例子就是信息抽取任务。训练集往往是通过“远程监督+人工粗标”的方式构建的,量很大,但是里边可能错漏比较多,而测试集可能是通过“人工反复精标”构建的,错漏很少。这种情况下就无法通过划分数据的方式构建一个更好的验证集了。
第二种是输入的分布不一致。说白了就是x的分布不一致,但是y的标注情况基本上是正确的。比如分类问题中,训练集的类别分布跟测试集的类别分布可能不一样;又或者在阅读理解问题中,训练集的事实类/非事实类题型比例跟测试集不一样。这种情况下我们可以适当调整采样策略,使得验证集跟测试集分布更一致些,从而验证集的结果能够更好反映测试集的结果。
判别器
为了达到我们的目的,我们让训练集的标签为0,测试集的标签为1,训练一个二分类判别器D(x):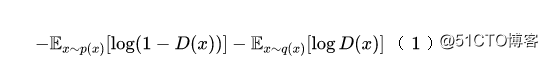
(向右滑动查看完整公式)
其中p(x)代表了训练集的分布,q(x)则是测试集的分布。要注意的是,我们不是要将训练集和测试集直接混合起来采样训练,而是分别从训练集和测试集采样同样数量的样本来组成每一个batch,也就是说需要过采样到类别均衡。
可能有读者担心过拟合问题,即判别器彻底地将训练集和测试集分开了。事实上,在训练判别器的时候,我们应该也要像普通监督训练一样,划分个验证集出来,通过验证集决定训练的epoch数,这样就不会严重过拟合了;或者像网上有些案例一样,直接用逻辑回归做判别器,因为逻辑回归足够简单,过拟合风险也更小了。
跟GAN的判别器类似,不难推导D(x)的理论最优解是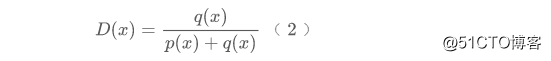
也就是说,判别器训练完后,可以认为它就等于两个分布的相对大小。
重要性采样
优化模型也好,算指标也好,其实我们是希望在测试集上进行,也就是说,对于给定目标f(x)(比如模型的loss),我们希望算的是
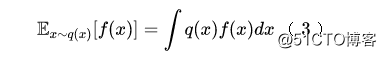
但是要算目标f(x),通常要知道x的真实标签,但对于测试集来说我们不知道它的标签,所以不能直接算。不过我们知道训练集的标签,于是我们可以解决它来做重要性采样: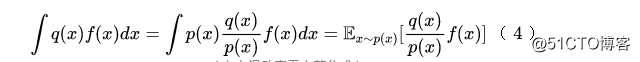
(向右滑动查看完整公式)
根据公式(2),我们知道,所以最终变成
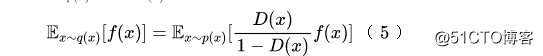
(向右滑动查看完整公式)
说白了,重要性采样的思想就是从训练集里边“挑出”那些跟测试集相近的样本,赋予更高的权重。
最终策略
从公式(5)我们可以得到两个策略:
第一是直接按照公式加权,也就是说,还是按随机打乱的方式划分训练集和验证集,但是给每个样本配上权重 。值得指出的是,类似的做法有些选手做比赛时已经用过了,只不过流传的权重是 D(x),当然哪个好我没法断言,只是从理论推导的角度来看应该是更加合理一些。
另一个策略就是实际地把对应的验证集采样出来。这也不难,假设训练集的所有样本为 ,我们把权重归一化。
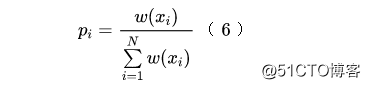
然后按照 为分布做独立重复采样,直到采样到指定数目即可。注意需要做 有放回的独立重复采样,因此同一个样本可能被采样多次,在验证集里边也要保留多次,不能去重,去重后分布就不一致了。
文末小结
本文从训练判别器的角度来比较训练集和测试集的差异,并且结合重要性采样,我们可以得到一个跟测试集更接近的验证集,或者对训练样本进行加权,从而使得训练集的优化过程和测试集差异性更小。
标签:验证 技巧 比例 两种 img src 情况 重复 上进
原文地址:https://blog.51cto.com/15061930/2567662