标签:type anything elf info hang 参数 block dia gpu

编 | YY
一提到模型加速,大家首先想到的就是蒸馏、(结构性)剪枝、量化(FP16),然而稀疏矩阵(sparse matrix)运算一直不被大家青睐。原因也很简单,一是手边没有现成的代码(懒),二是即使用了,速度也不一定有之前的稠密矩阵(dense matrix)快。
不过,框架的开发者们并没有停下他们的脚步,就在不久前,HuggingFace开心地宣布,他们可以支持稀疏矩阵运算啦!75%的sparsity换来了1/4的内存和2倍的速度提升!
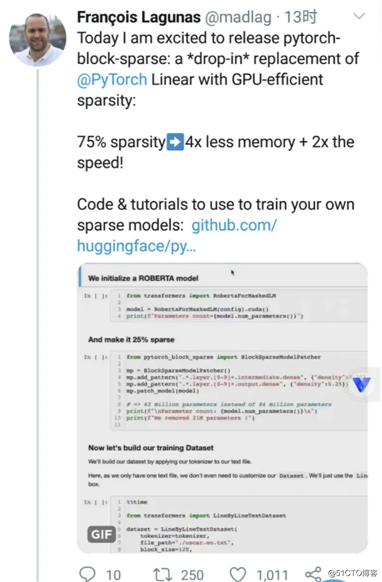
这个消息还是比较令人激动的,首先稀疏矩阵在存储上省略了0值,另外在计算上,也没必要计算和0值相关的结果。所以稀疏矩阵能显著提升运算速度,并节约大量存储空间。
不过老司机们的第一反应肯定是:效率不错,但效果(精度)怎么样?
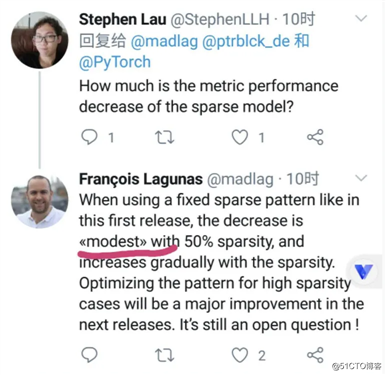
普普通通……(注意上图高亮的modest,感觉效果的确一般,否则就直接放结果了=。=)
Anyway,虽然精度有些美中不足,但单从速度上讲已经很好了。技术的进步要一步步来,以HuggingFace的效率,之后应该还会有更多动作。
细心的同学们看到这里一定很疑惑,为啥压缩了4倍,但只提升了2倍速呢?
在pytorch_block_sparse[1]的Github库中,官方详细解释了这个问题:主要是当前使用的CUTLASS库还不够快。
在继续下文的讨论前,先介绍些GPU编程的小知识:
可见如果深入研究出定制化的稀疏矩阵运算库,速度上可能还会有所提升。
对于想试用的同学,HuggingFace也一如既往地重视“拿来即用”的体验,提供了两种使用方法:
# from torch.nn import Linear
from pytorch_block_sparse import BlockSparseLinearself.fc = BlockSparseLinear(1024, 256, density=0.1)
2.想转换别人已经写完的网络,可以直接转整个模型。可惜不能自动转参数,需要重新训练。from pytorch_block_sparse import BlockSparseModelPatcher
mp = BlockSparseModelPatcher()
mp.add_pattern("roberta.encoder.layer.[0-9]+.intermediate.dense", {"density":0.5})
mp.add_pattern("roberta.encoder.layer.[0-9]+.output.dense", {"density":0.5})
mp.add_pattern("roberta.encoder.layer.[0-9]+.attention.output.dense", {"density":0.5})
mp.patch_model(model)
print(f"Final model parameters count={model.num_parameters()}")
目前HuggingFace只迈出了一小步,后续CUTLASS还会继续提升,作者也会复现更多的学术成果。除了他们之外,OpenAI在20年初也宣布要将Tensorflow的部分计算代码移植到Pytorch,谷歌和斯坦福在6月的Paper Sparse GPU Kernels for Deep Learning[2] 也承诺会放出源码,大家可以把稀疏矩阵的优化学习提上日程啦。
HuggingFace又出炼丹神器!稀疏矩阵运算进入平民化时代!
标签:type anything elf info hang 参数 block dia gpu
原文地址:https://blog.51cto.com/15061930/2567656