标签:com 信息增益 red 应该 生成 art ima 推导 朋友圈

图片来源:pexels
试想一下,如果一群宇航员发现了一个新星球,那么问题就来了:这个星球能否成为下一个地球?
在现实生活中,决策树有许多类似的例子,也影响着机器学习的许多领域,比如说分类和回归分析。在进行决策分析时,决策树可以明确直观地表示决策和决策制定的过程。
决策树是一系列相关选择的可能结果的映射。决策者可以基于不同选择的成本、可能性和收益来进行权衡。
决策树,顾名思义,是树状的决策模型。它们既可以推动非正式讨论的进程,也可以制定能够预测数学上的最优解算法。决策树通常从一个节点开始,引申出不同的结果。每个结果又引向另一个节点,这些节点又会产生其他的结果。最后形成了一个树状图形。
节点有三种类型:机会节点、决策节点和结束节点。机会节点,用圆表示,显示结果的概率;决策节点,用正方形表示,显示做出的决策;结束节点则显示决策的最终结果。

· 决策树生成的规则都是可理解的。
· 决策树执行分类不需要太多的计算。
· 决策树能够处理连续变量和分类变量。
· 决策树可以清楚地指出在预测和分类中哪些字段最重要。
· 决策树不适用于评估预测连续值域的价值。
· 决策树在分类类别多而训练实例相对较少的情况下容易出现分类错误。
· 训练决策树需要大量计算,创建决策树也是如此。在每个节点上都必须对所有候选分割字段进行排序,然后才能找到其最佳分割。在一些使用了字段组合的算法中,必须搜索才能得到最优的组合权值。修剪算法也很复杂,因为需要生成许多候选子树并且进行比较。

再回到一开始宇航员发现新星球的例子,要做出正确的决定需要对大量的因素进行全面的研究。比如说,这个星球上有水吗?温度是多少?易发生连续性暴雨吗?动植物能否适应那里的气候?
现在创建一棵决策树,看看是否可以发现一个新的栖息地。
人类适宜居住的温度在0到100摄氏度之间。
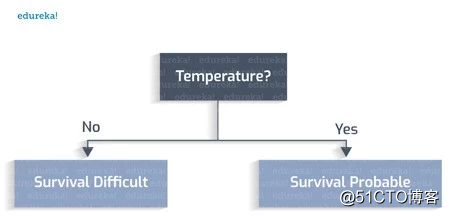
有水吗?
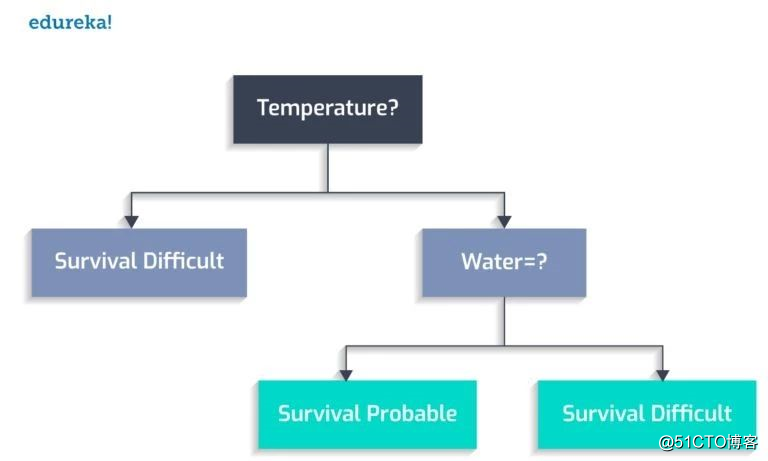
动植物能繁衍下去吗?
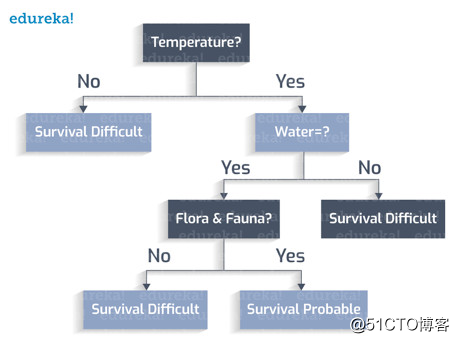
这颗行星表面有暴风雨吗?
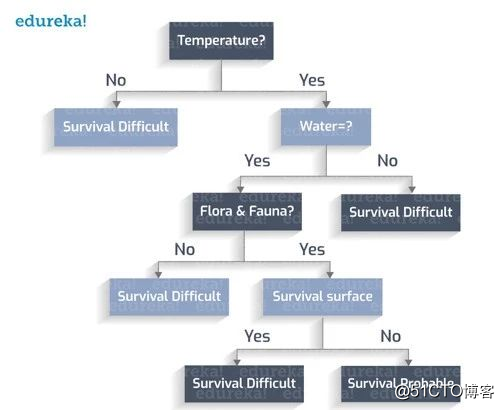
这样就有了一颗完整的决策树。

分类规则是要考虑到所有的场景以及其中的类变量。
每个叶子节点都有一个类变量。类变量是引向决策的最终输出。
从所创建的决策树中推导出分类规则:
如果温度不在273 ~ 373K之间,->难以存活
如果温度在273到373K之间,没有水,->难以存活
如果温度在273到373K之间,有水,没有动植物,->难以存活
如果温度在273到373K之间,有水,有动植物,表面没有暴风雨,->可能存活

决策树由以下部分组成:
· 根节点:本例中“温度”即为根。
· 内部节点:有一个传入边,两个或多个传出边的节点。
· 叶子节点:终端节点,没有传出边。
在构建决策树时,从根节点开始,检查测试条件并将控件分配给一个输出边,这样就测试好了条件也创建好了节点。当所有测试条件都指向叶子节点时,决策树就创建好了。叶子节点包含了评估决策是好是坏的类标签。
你可能想知道为什么选择从温度属性开始?如果选择其他任何属性,所构造出的决策树将是不同的。
是的,对于一组特定的属性,可以创建许多不同的树,需要按照算法来选择最优。接下来,我们将学习使用“贪婪算法”来创建完美的决策树。

贪婪算法基于启发式问题求解的思想,在每个节点上进行最优局部选择。通过这些局部最优解,得到了全局的近似最优解。
——维基百科
这种算法可以总结为:
在每个节点,选出测试条件的最优项。
将节点分出可能的结果(内部节点)。
开始操作这个算法时,就会产生第一个问题:怎么确定第一个测试条件呢?
可以从熵增和信息增益的值来得到问题的答案。首先看看它们是什么,然后了解它们是如何影响决策树的创建的。
熵:决策树中的熵表示同质性。如果数据完全同质,熵为0;如果数据被分为(50-50%),熵为1。
信息增益:信息增益是节点发散时熵值的减小/增大。
用于切分的属性应该最高信息增益。根据熵和信息增益的计算值,在每个步骤中选择最优的属性。
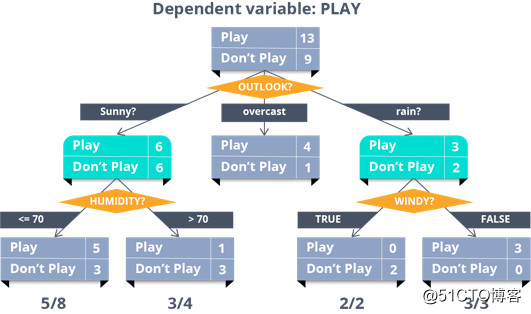
看下面的数据:
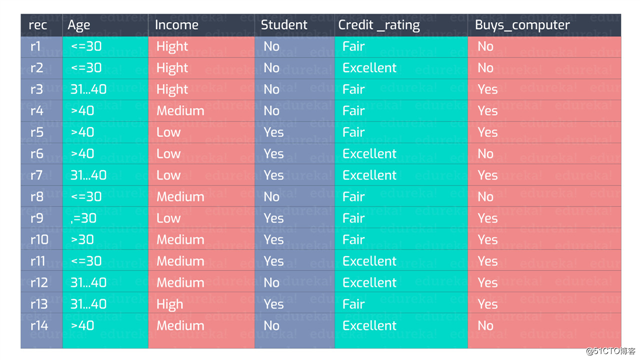
这些数据可以生成无数棵决策树。
决策树创建尝试1:
将“学生”属性作为第一个测试条件。
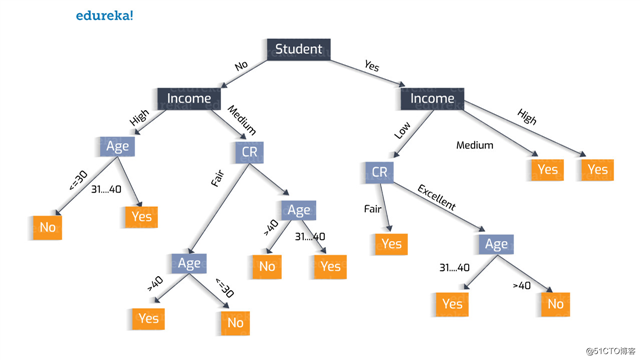
决策树创建尝试2:
为什么选择“学生”属性呢?也可以试试用“收入”开头。
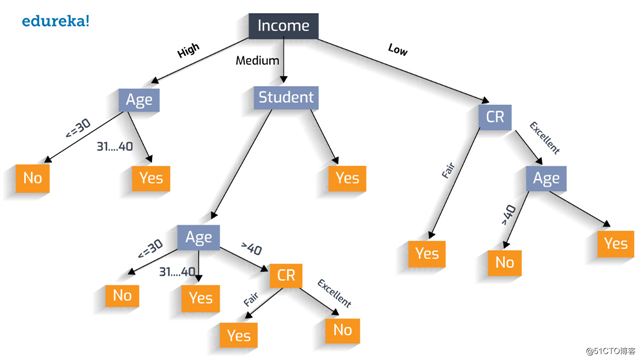

让我们按照贪婪算法的步骤创建最优决策树。
这里涉及到两个选择:“Yes”表示此人购买了一台计算机,“No”表示他没有购买计算机。为了计算熵增和信息增益的值,需要先计算这两个选择的概率值。
?肯定:" 是否买了电脑=yes "可能性是:
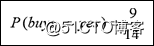
?否定:"是否买了电脑=no"可能性是:

D中的熵:现在把概率值代入上面的公式来计算熵。
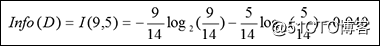
我们已经对熵值进行了分类,分别为:
熵= 0:数据完全同质(纯)
熵= 1:数据被分成50%/ 50%(不纯)
现在我们的熵值是0.940,几乎是不纯的。
继续深入研究,找出合适的属性然后计算信息增益。
如果细分“年龄”属性,信息增益会是多少呢?
这个数据代表了不同年龄阶段的人对产品的购买情况。
例如,对于30岁以下的人,2人购买(Yes),3人不购买(No)。在最后一列中表示的信息值(D)是对这3类人进行计算。
年龄属性的信息值 (D)是这三个年龄值范围的总和计算。现在的问题是,如果我们将“年龄”属性继续细分,那么“信息增益”是什么?
总信息值(0.940)与年龄属性计算的信息值(0.694)之差则为“信息增益”。
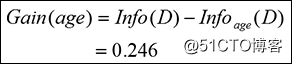
这就是决定我们是否应该在“年龄”或其他任何属性上继续细分的因素。同样地,可以计算其余属性的“信息增益”:
信息增益(年龄)= 0.246
信息收益(收益)= 0.029
信息增益(学生身份) = 0.151
信息增益(信用评估) = 0.048
比较所有属性的增益值,我们发现“年龄”的“信息增益”最高。因此,需要将“年龄”属性细分。
类似地,每次在决定是否细分时,比较一下信息增益,以确定是否选择该属性进行细分。
因此,最终创建的最优树如下:
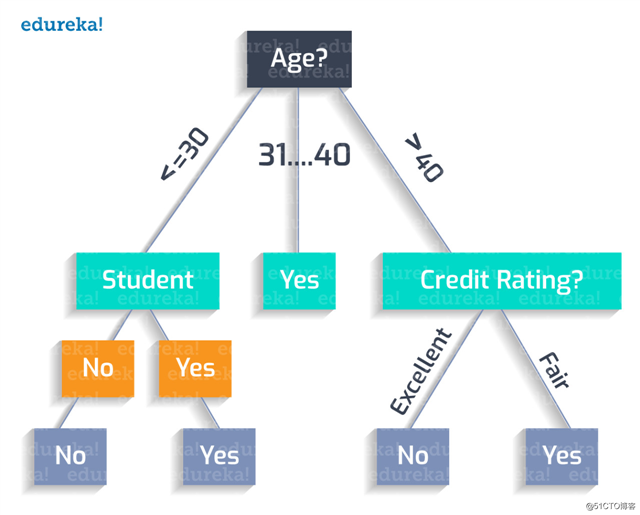
该树的分类规则可记为:
如果年龄小于30岁,且不是学生,则不会购买该产品。
Age (<30) ^ student(no) = NO
如果年龄小于30岁,且是一名学生,则会购买该产品。
Age (<30) ^ student(yes) = YES
如果年龄在31岁到40岁之间,极有可能购买该产品。
Age (31…40) = YES
如果年龄大于40岁,且信用评估良好,则不会购买该产品。
Age (>40) ^ credit_rating(excellent) = NO
如果年龄大于40岁,且信用评估一般,则可能会购买该产品。
Age (>40) ^ credit_rating(fair) = Yes
这样,就创建了一棵完美的决策树!

编译组:胡婷、王泽泽
相关链接:
https://dzone.com/articles/how-to-create-a-perfect-decision-tree
如需转载,请后台留言,遵守转载规范ACL2018论文集50篇解读
EMNLP2017论文集28篇论文解读
2018年AI三大顶会中国学术成果全链接
ACL2017论文集:34篇解读干货全在这里
10篇AAAI2017经典论文回顾
标签:com 信息增益 red 应该 生成 art ima 推导 朋友圈
原文地址:https://blog.51cto.com/15057819/2567633