标签:类型 网络模型 预测 扩大 不用 文件上传 编译 表示 安全

用认知计算处理现实生活中的业务是一件很有意义的事情,比如在IT服务管理领域。机器学习对处理现实案例中的分类与分配问题将会比人工更为有效,比如以下几种场景:
在服务台,几乎三至四成的事故票单没有被发送至相应的团队,这些票单一直毫无目的地漫游着。等相应团队收到票单,事故已经蔓延到高层管理人员处,引起许多麻烦。
假设用户使用打印机遇到问题。用户联络服务台,服务台分发票单给IT支持团队,然后他们通过更新用户系统里的配置系统,以解决票单所提事故。如果类型问题重复出现,就可以使用这一部分数据,并利用非结构化数据分析其潜在问题。这样就可以分析问题趋势并减少事故票单。
基于时间和资源上的限制,本文将以第一个案例为例进行分析。
· ServiceNow Instance (一个IT服务管理平台)
· AWS Lambda功能
· EC2 Instance
· Python
· 人工神经网络模型
· 开源获取的五万余票单样品

过程的整体工作流程可以分成几个部分。下图显示高级的概观。
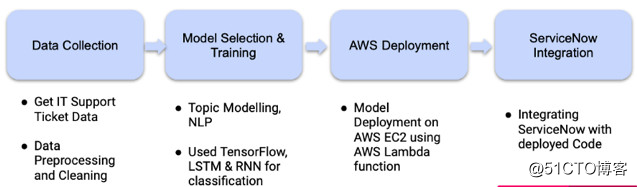
从ServiceNow平台直接抽取数据集,并尝试使用ML技术将其分类和贴上标签。只保留票单的描述和种类,然后利用解析学将事故分为五大类。
使用模型的方式将事故五大类分类后,以便给票单贴上标签。
在典型的IT环境下,多数关键问题是以票单形式进行追踪和处理的。IT的基础设施是一组在网络联在一起的成分。所以,当其中一个成分失效,其他成分也会受到影响。有时甚至需要几天时间才能知道哪里出错。所以通知组件拥有者是非常必要的。
人们必须迅速采取适当措施以阻止同类事件再次发生。
这些事故通常是用户拨打服务热线或者服务台报告,他们是IT服务的前线。不幸的是,并不是所有人都熟悉每个成分,因此票单才会被错误转送。如何让票单迅速转送至正确的团队呢?可以使用自然语言处理解决这个问题。
IT服务管理产生40多GB的数据,为我们提供了足够的数据训练与安装模型。
模型安装完毕后,可以为业务部门节省数十亿美金,这些部门曾因这个问题未能达成多个服务级别的协议。
云计算的发明,创造了机器学习算法和IT服务管理继承的可能性。


在本次用例中使用ServiceNow,这是一个基于云计算的IT服务管理应用程序。我们也利用API网关获取了AWS Lambda功能里的机械学习模型。
网络服务使应用程序能够通过网络与其他软件应用程序连接,从而实现提供者(服务器)和客户(消费者)之间的信息交换。
网络服务消费者(客户)向网络服务提供者(服务器)请求信息。网络服务提供者处理该要求后回复了状况代码和响应体。当收到响应体后,网络服务消费者将从响应体提取信息并使用该数据。
ServiceNow可从第三方提供者或者另一个ServiceNow instance获取网络服务。
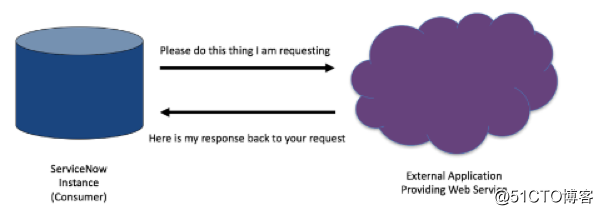
在本例中,利用Rest网络服务让API网关引发端点url,并使用发行票单时运行的JavaScript获取了该url。
发行票单时,JavaScript会被引发,导致事故描述被发送至安装在AWS的模型。随后,模型将执行机器学习运算并将预测类型和可能性发回。

· 在不确定主题内容的情况下,可预先确定主题数量。
· 每个文档都可分为不同主题。
· 而每个主题都可分为不同字类。
我们使用了 NLTK’s Wordnet 来查找字义、同义词、反义词等。此外也使用了 WordNetLemmatizer 查出单词词根。
然后,逐行读取数据集,将每一行为 LDA (隐含狄利克雷分布)备好,再把它们存进列表。

首先从数据编写一个词典,并将其转换至词袋模型语料库,再储存词典和语料库以备将来使用。
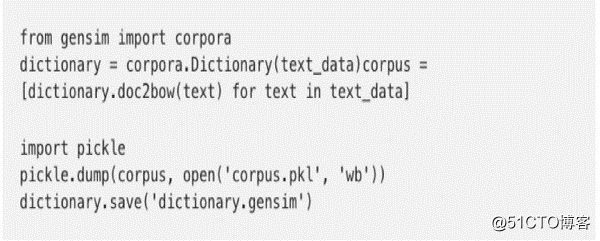
然后使用LDA尝试寻找五个主题:



pyLDAvis 旨在帮助用户诠释主题模型里的主题,主题模型是被放入文本数据语料库里的。该软件包从其中一个LDA主题模型中提取信息,以实现网络交互式可视化。


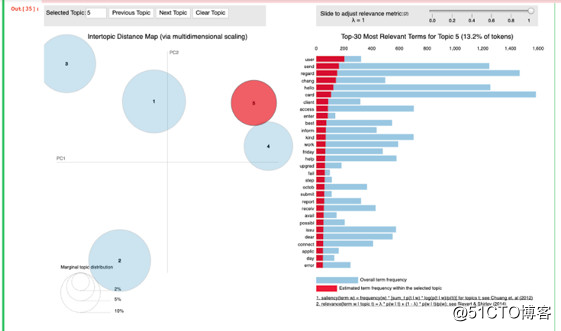
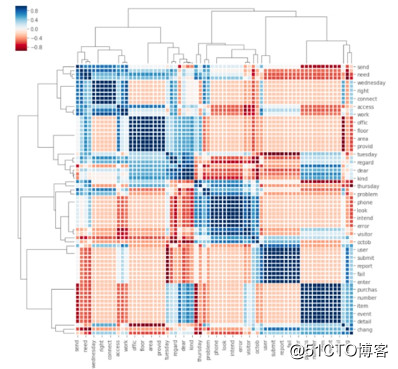
从主题模型这里,得到了一个结论。那就是整个数据集分为以下五类:
· 网络
· 用户维护
· 数据库
· 应用程式介面
· 安全
之后,依此给数据集贴了标记,并制作了一个数据集,以此在上面进行监督式学习。

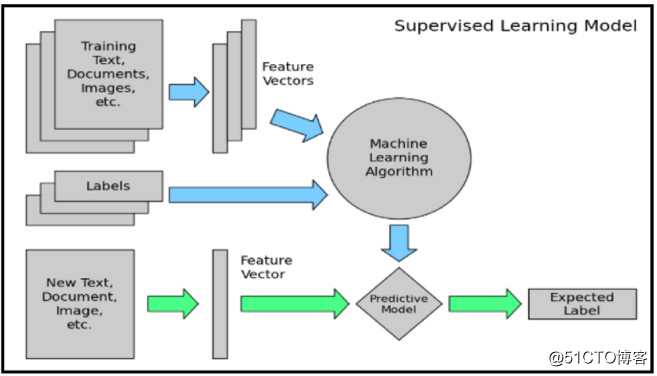
端到端文本分类管道由以下组件组成:
训练文本:这是监督式学习模型学习和预测所需类型的输入文本。
特征向量:该向量包含描述所输入数据特征的信息。
标签:这些是模型预测的预定义类型。
ML Algo: 模型通过这个算法处理文本分类【比如使用CNN(卷积神经网络), RNN(递归神经网络), HAN(多层注意力模型)】。

递归神经网络(RNN)是一种人工神经网络,各节点间可连接成一按序树状图。由此可以显示一个时间序列上的动态时间行为。
使用来自外部输入的知识可以提高RNN的准确度,它集成了关于各种字义和语义的信息。这些信息是在非常大的数据库中训练和提炼的,目前使用的是训练前嵌入的GloVe.
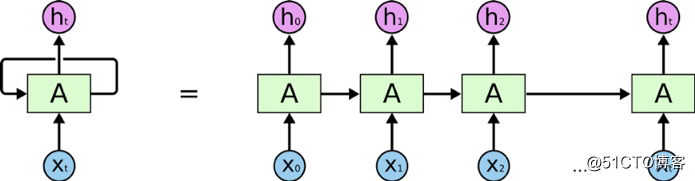
RNN是一系列的神经网络块。它们像铁链一样相互连接,每一块节点都在向下一个节点传递信息。
AA是一大块神经网络,它读取了输入文 xtxt 和输出值 htht。通过循环信息得以一节一节传递消息。
LSTM网络
长短期记忆网络,通常简称 LSTMs ,是一种特殊的 RNN ,具有长期学习的能力。它们由 Hochreiter 和 Schmidhuber 于1997年提出, 许多研究者进行了一系列的工作对其改进并使之发扬光大。1 LSTM在处理各类问题上效果都非常好,现今被广泛使用。
LSTMs 在设计上是为了避免长期依赖的问题。长时间记住信息是默认行为,而不是努力学习的结果。
所有 RNN 都具有一串重复的神经网络模块。在标准的 RNN 中,这些重复的模块结构简单,比如只有一个 tanh 层。
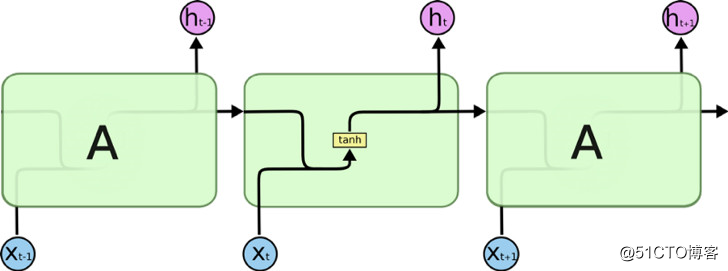
标准 RNN 的重复模块仅包含一个单层。
LSTM 也有类似的链状结构,但是其重复模块的结构却不同。他们不只拥有一层神经网络,而是有四层,它们以一种非常特殊的方式相互作用。
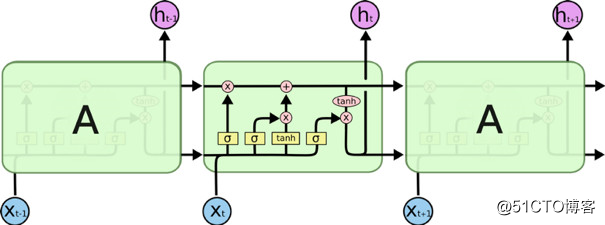
LSTM 的重复模块包含四个互相作用的神经网络层。
不用太担心其中的细节。之后将逐步探讨 LSTM 图里的每一部分。现在,先介绍一下将要使用的符号。
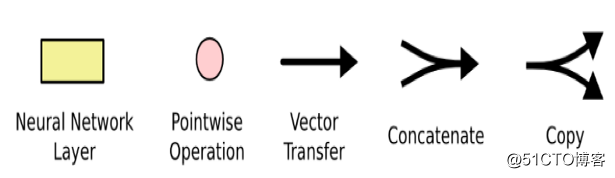
上图中,每条线表示一个完整的向量,从一个节点的输出传递到其他节点的输入。粉红圆圈表示点态运算,比如向量加法;而黄色格子则是已学习的神经网络层。如果两条线交汇,那代表着向量的连接;而相反的如果它们分叉,则表示其内容已被复制然后被送至其他位置。

LSTM 的关键是元胞状态一一如下图横穿整个图表顶部的水平线。
元胞状态有点像是传送带。它直接闯过整个链,过程中线性交互很少出现。上面承载的信息可以很容易地随着这个过程流过而不受影响。
LSTM 可以对对元胞状态移除或添加信息,这能力由一种叫 “门” 的结构小心管理。
“门” 是一种选择性让信息通过的方式。它们由一个 sigmoid 神经网络层和一个点态相乘操作组成。
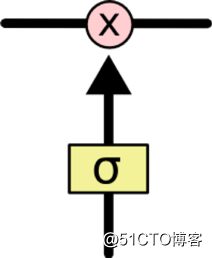
Sigmoid 层输出0~1间的值,表示多少成分可否通过。0值表示 “不允许通过” ,而1值表示 “让所有信息通过”。
一个 LSTM 有三个“门”,以保护和控制元胞状态。

LSTM 的第一步是决定将要中元胞状态从扔掉哪些信息,由一个叫做 “遗忘门层” 的sigmoid层来做此决定。它观察 ht-1ht-1 和 xtxt,然后针对元胞状态 Ct-1Ct-1 的每个数字输出00~11之间的值。11表示 “完全保留信息” ,00 表示 “完全丢弃信息” 。
回到语言模型的例子,该语言模型根据之前的单词预测下一个单词。在这样的问题中,元胞状态可能包含当前主语的性别,因此需要选择正确的代词。当遇到一个新的主语时,就需要忘掉旧主语的性别。
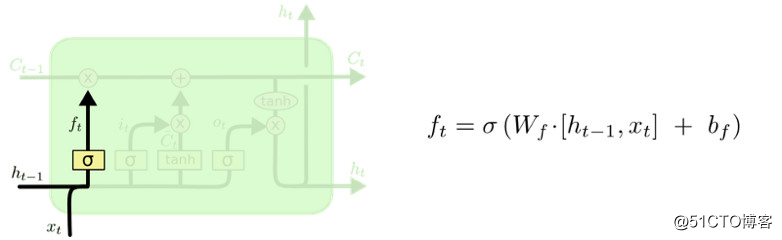
下一步决定将哪些新信息储存到元胞状态中。这里有两部分。第一,有一个称为“输入门层”的 Sigmoid 层决定我们要更新哪些数值。接下来,一个 tanh 层创造了一个新的候选值向量,C tC~t,并加进状态里。下一步,需要将以上两个数值结合,用于更新状态。
在语言模型的例子中,可以把新主语的性别加到元胞状态里,以取代正遗忘的旧主语性别。
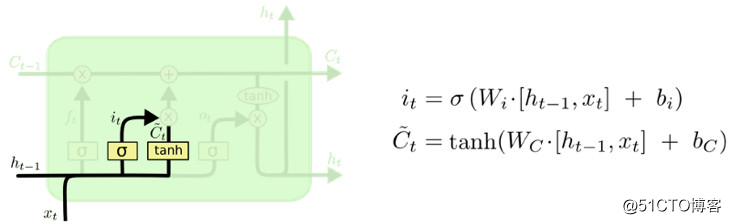
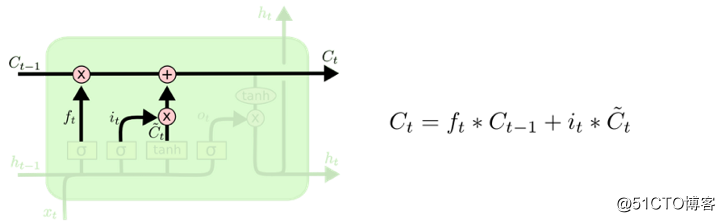
现在是更新旧元胞状态 Ct-tCt-t 到新元胞状态 CtCt 的时候了。根据上面的步骤执行即可。
将旧状态乘以 ftft,把之前决定遗忘的内容忘掉。然后再加上 it?C? tit?C~t。这个是新的候选值,按决定更新每个状态值的大小进行增减。
在这语言模型的例子,我们的做法如前面步骤,移除旧主语性别的信息,并添加新信息。
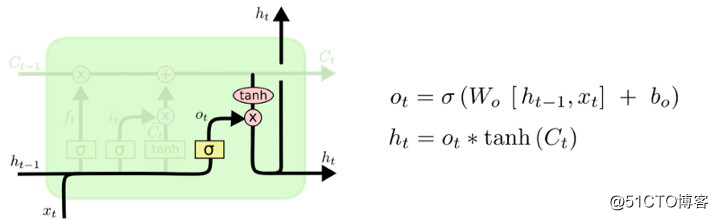
最后,需要决定输出。该输出将基于元胞状态,但却是经过过滤的。首先,建立一个 sigmoid 层以决定元胞状态要输出的部分。然后,将元胞状态通过 tanhtanh 之后(将值扩大至-1-1和11之间),与 sigmoid 门的输出值相乘,这样就只会输出想输出的部分。
比如这个语言模型的例子中已出现了主语,因此可能需要输出与动词相关的信息。举个例子,通过确定输出主语是单数还是复数,以便于接下来可以输出正确形式的动词。

前面所形容的是很普通的 LSTM。并非所有的 LSTM都与上述所说的相同。似乎每一篇谈论 LSTM 的文章都使用的版本略有不同,其中微小的差异更值得注意。
Gers 和 Schmidhuber 曾于2000年提出一个流行的LSTM变体,即在原来的LSTM基础上加入了“窥视孔连接”。这表示我们让门层得以观察元胞状态。
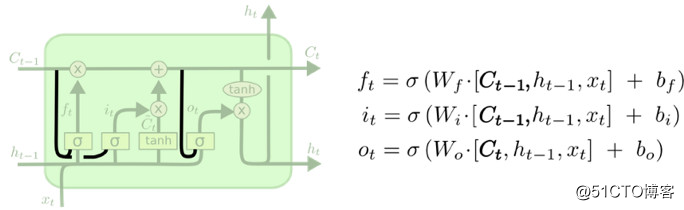
上图给所有的“门”加入了“窥视孔”,不过也有一些文章只加了一部分,并非所有。
另一种变体是使用对偶的遗忘门和输入门。不应该分开决定该忘记哪些信息、该添加哪些新信息;而应该同时作出以上的决定。操作时应在需要添加信息的地方忘记该处的旧信息。同理只会在忘记一些旧信息后往状态里添加新数值。
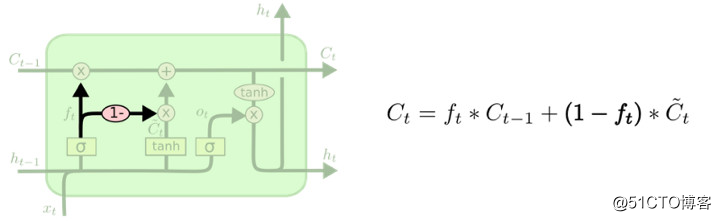
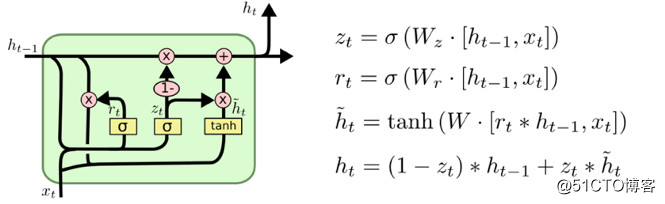
另一种 LSTM 变化比较大,它叫做门控循环单元网络,简称 GRU,由Cho等人于2014年提出。GRU 将遗忘门和输入门合并成为单一的 “更新门” 。它也将元胞状态和隐状态合并,同时作出其他一些变化。该模型比标准的 LSTM 模型更加简化,现在也愈发受欢迎。


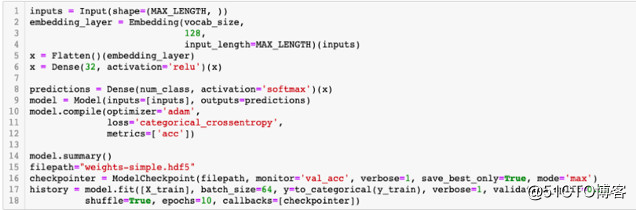

在对文本数据使用 Keras 前,必须先对文本进行预处理。此处可以使用 Keras 的词语切分器(Tokenizer)类型。这东西根据词频进行词语切分,然后将所保留的最大单词数做成 num_words 参数。
一旦在数据上安装好词语切分器后,可以使用它将问字符串转换为数字序列。这些数字代表着字典里每个单词的位置(可以将其视为映射)。
· 本项目尝试使用递归神经网络和Attention机制的 LSTM 编码器处理问题。
· 在操作前馈神经网络以分类前,通过 LSTM 编码器尝试将 RNN 最后输出的文本信息编码。
· 这与神经翻译机器和 Seq2Seq 学习模型很相似。
·使用 Keras 里的 LSTM 层来处理长期依赖的问题。

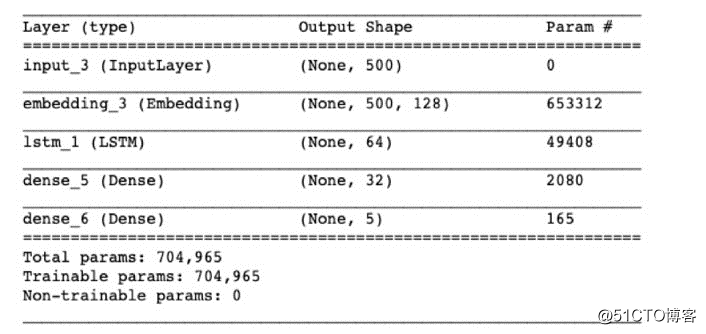
模型评分和挑选需根据一定的标准评价指标,包括:准确度、精密度、F1 评分,以下是定义:

其中:
· TP 表示真阳性分类的数量。也就是说,带有实际标签A的记录被正确归类,或“被预测”为标签A。
· TN是真阴性分类的数量。也就是说, 实际上不带标签A的记录被正确归类为不属于标签A。
· FP 是假阳性分类的数量。例如,实际上带着标签A以外的记录被错误归类为属于A类型。
· FN 是假阴性分类的数量。例如,实际上导带有标签 A 的记录被错误归类为不属于A 类型。
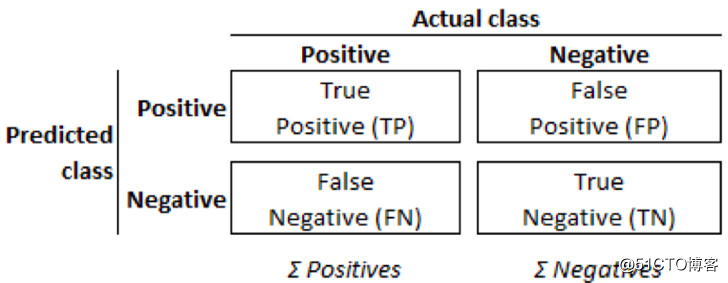
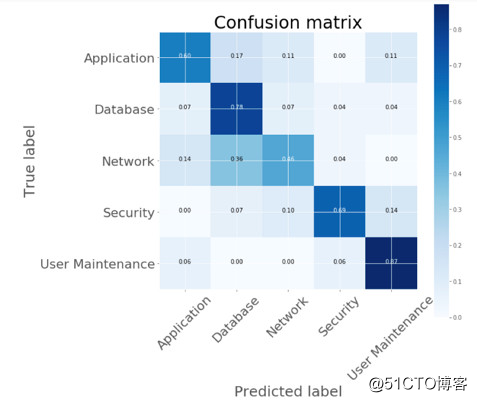
预测分类的“混淆矩阵”vs实际分类的“混淆矩阵”
如图所示,预测分类和实际分类合称为“混淆矩阵”。在这些定义背景下,各种评估指标提供了以下见解:
· 准确度:模型预测正确的总数所占的比例
· 精密度(也称阳性预测值):在特定类型里预测正确相对于所有预测所占的比例。
· 召回率(也称真阳性率、TPR、命中率或灵敏度):真阳性相对于实际阳性所占的比例。
· 假阳性率(也称虚警率):假阳性相对于实际阳性所占的比例(FPR)。
· F1:(较为稳固的)精密度和召回率间的调和平均数。

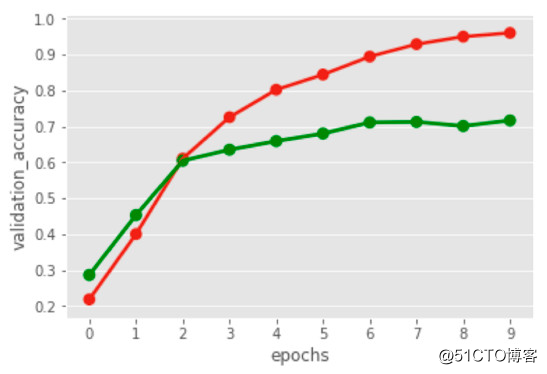
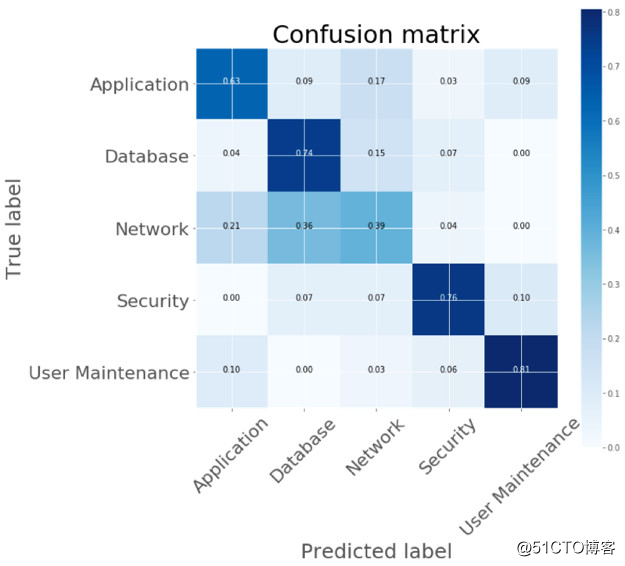
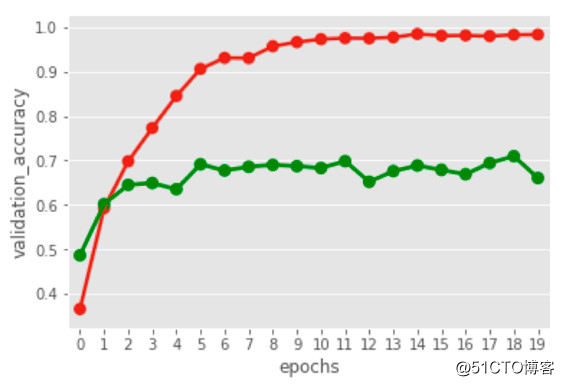
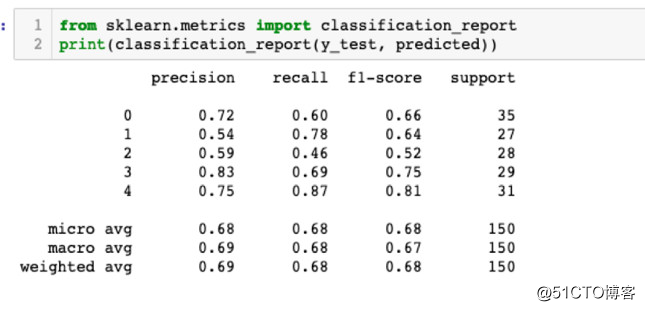

一般无 LSTM 的 RNN 模型提供了高达66%的准确度,而当 RNN 使用 LSTM 网络层之后准确度可以提升至69%。
少量数据导致准确度只能停滞在70%,而就如图中所示,增加图上x轴的节点也毫无影响。
然而69%的分类准确度是足够的。因为我们打算在线培训它,并随着数据量的增长不断提高准确度。

在这一部分项目中,我们计划在Amazon AWS上运行这个模型,并将其与 Service Now 组合起来,以便模型可以在线上实时预测。为此,首先将模型放进 pickle 文件将其导出。此外,编写一个函数,这函数将连接到 S3 储存桶,并从那里获取和读取 pickle 文件并重新创建模型。
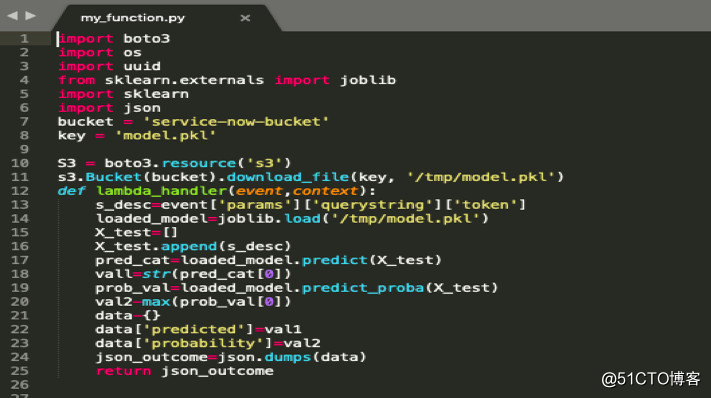
工作流程如下:
在 ServiceNow 制造时间。
AWS 接收到事件,然后AWS EC2 实例或服务开始运行。
从 S3 储存桶取 function.py 文件,它将从 Pickle 文件读取并重建模型。
它将从服务请求中提取特征,比如事件描述。
现在,代码将在 AWS Lambda 执行,它将提供事件所属类型。
在 AWS 制造一个 EC2实例。
首先,先创建一个 AWS 账户。可在一年内免费使用它的有限服务。
创建一个 EC2 实例并选择免费方案机器。或者如果账户里有积分,并且需要更强大的机器,也可以选择其他选项。
在 AWS 上为 Python 配置一个虚拟运行环境,完成后将所有配置文件压缩到一个文件中,并将 function.py 文件包括在内将把这个文件上传到 AWS S3 储存桶。
AWS Lambda 是个计算服务,允许在无需提供或管理服务器的情况下运行代码。它可以自己处理这部分。而 AWS Lambda 最大的优势是只需要为所消耗的计算时间付费,代码不运行时不计费。可以使用 AWS Lambda 运行任何应用程序或后段服务运行代码,且无需任何管理工作。AWS Lambda 在高度可用的计算基础设施上运行代码,并执行计算资源的所有管理工作,包括服务器和操作系统的维护、容量分配、自动缩放、代码监视和记录。唯一需要做的就是用 AWS Lambda所支持的语言之一提供代码。
由于不熟悉,此项目暂时无法设置 AWS Lambda,需要翻阅其文档导致时间不足。因此需要计划延长项目至其他课程以完成它。

网络服务使应用程序能够通过网络与其他软件应用程序连接,从而实现提供者(服务器)和客户(消费者)之间的信息交换。
网络服务消费者(客户)向网络服务提供者(服务器)要求信息。网络服务提供者处理该要求后回复状况代码和响应体。当收到响应体后,网络服务消费者将从响应体提取信息并使用该数据。
ServiceNow可从第三方提供者或者另一个ServiceNow instance获取网络服务。
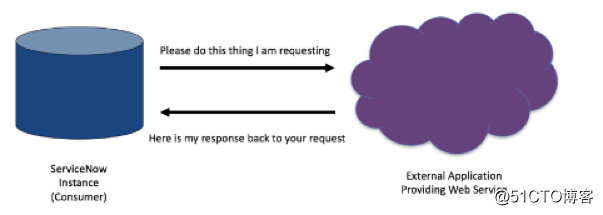
在本例中,利用Rest网络服务让API网关启动端点url,并使用发行票单时运行的JavaScript获取了该url。
发行票单时,可以使用JavaScript,该程序可以将事件描述发送至我们安装在AWS的模型。随后,模型将执行机器学习运算并将预测类型和可能性发回。

编译组:苏英豪、伍颖欣
相关链接:
https://towardsdatascience.com/it-support-ticket-classification-and-deployment-using-machine-learning-and-aws-lambda-8ef8b82643b6
如需转载,请后台留言,遵守转载规范ACL2018论文集50篇解读
EMNLP2017论文集28篇论文解读
2018年AI三大顶会中国学术成果全链接
ACL2017 论文集:34篇解读干货全在这里
10篇AAAI2017经典论文回顾
标签:类型 网络模型 预测 扩大 不用 文件上传 编译 表示 安全
原文地址:https://blog.51cto.com/15057819/2567743