标签:iss sda 日常 作家 自动 图片 elf fda 必须


不黑不火,越黑越火。蔡徐坤,被各种高科技黑得五彩斑斓。
蔡徐坤,近年顶级流量鲜肉,于《偶像练习生》C位出道。因其剑眉星目、生性温柔、发量惊人,斩获大波重度迷妹。
原本饭圈和直男界两不相干,自从NBA授予蔡徐坤形象大使的荣誉称号后,一大波女粉速速集合撑起了NBA在中国的商业版图。而虎扑直男们则不买账!通过技术调侃蔡徐坤,以保卫他们的“理想国”。
于是有人挖出蔡徐坤出道时打篮球的视频进行AI技术实践。

在各路大神手里,蔡徐坤被换成李云龙、苏大强、马云、华农兄弟、杨幂等一众话题人物的姣好容貌,鬼畜到不忍直视。
然鹅,换在六老师身上毫不违和,为我们的齐天大圣赋予了当代偶像的精神风貌。

图片来源:B站《【ai换脸】如果六老师模仿蔡徐坤打篮球》UP主 :deepfake
此外,还有大神用Python爬虫,扒蔡徐坤条条转发量100万+背后流量造假的事实。
直男们换脸P图搞创作,粉丝们刷榜控评做推广。各自张力十足,不亦乐乎。
然而只需要一个导火索,圈地自嗨的各个阵营,就会短兵相接,口水铺天盖地,走向网络暴力。
在蔡徐坤的粉丝量突破700万大关的那天,微博表示染个黑发作为粉丝福利。原本只是迎合粉丝的日常举动,不小心引来一位不知名耿直boy的随口吐槽:
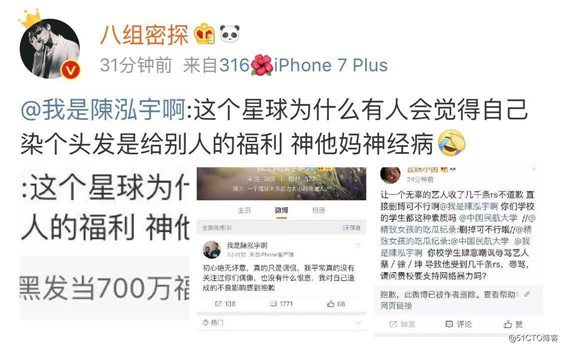
随后,这条微博引发不少大V共鸣转发,这个关注量仅200多的透明屁民的微博瞬间就炸了。
蔡徐坤可能根本没care这条微博,他的粉丝,包括各种看热闹的”黑粉“纷纷抱起了键盘。

他们视这条微博为一起严重的网络暴力事件,理直气壮“维权”。据不完全消息,当日该网友收到三千多条言语侮辱、亲人问候、被人肉、挂照片、人身***、p遗照……
最令人哭笑不得的是,和蔡徐坤仿佛身处不同次元的潘长江老师,微博沦陷,被逼道歉。原因竟只是因为在某综艺节目直言不认识蔡徐坤。

这可能是潘老师62岁以来最“受宠若惊”的一次。
蔡徐坤本人也很懵逼啊,粉丝真假参半,惹是生非,自己处处背锅。他只是一个被资本和流量选择、包装起来的”商品“,某种意义上,他只是一个符号一般的存在。
真正应该负责是只顾情绪宣泄的喷子和网络本身。

以某博为代表的开放式社交媒体,以及各家新闻客户端,已经成了网友们的泄粪(愤)场。这个打字不需要负责的年代,“键盘侠”群雄四起。
言语激战和事件发酵正为各平台所喜闻乐见。为了话题和流量,相关平台对于买粉、控评等虚假产业链缺乏监管,在话题推荐和评论控制上甚至有引导争端之嫌。
作为舆论的载体和控制中心,平台的公信力早已被流量踩在脚下。美国《纽约时报》早在十多年前发文表示:如果没有任何秩序,博客圈最终将变成一个令人生厌的场所。

原本有能力控制舆论发酵的平台坐视不管,才是最大的网络暴力。
监督控制辱骂和***性言论,原本是几行代码就可以轻松解决的事情。
本文介绍一个自动检测仇恨言论系统——使用scikit-learn构建,并通过Heroku上的Docker进行部署。作为线上留言板或评论区的监管员,在网上评论开始出现***性、和辱骂性言语时能得到快速提醒。及时采取控制措施。
用scikit-learn训练并坚持使用一个预测模型
使用 firefly 创建API端点
为此服务创建Docker容器
项目代码:https://github.com/dhaitz/python-sklearn-firefly-docker-heroku

此方法是基于戴维森、沃姆斯利、梅西和韦伯联合撰写的论文《自动化仇恨言论检测以及***性语言的问题》而建立,文章结果基于超过20000条已标记的推文所得。
详情:https://github.com/t-davidson/hate-speech-and-offensive-language
将csv文件作为数据帧加载:
import pandas as pd
import re
df = pd.read_csv(‘labeled_data.csv‘, usecols=[‘class‘, ‘tweet‘])
df[‘tweet‘] = df[‘tweet‘].apply(lambda tweet: re.sub(‘[^A-Za-z]+‘, ‘ ‘, tweet.lower()))最后一行通过将所有文本转换为小写并删除非字母字符来清除推文列。
结果:
rt kxrxsxb all i want for my birffday is a big booty hoe she gotta
big booty so i call her big booty lyricsyouliketoscream
crangrape gt good pussy
rt burgerking chicken fries oreo shake perfection http t co pdiglrbhjz
just remember when having standards becomes cool again im gonna call a lot of you out for staying quiet like a bitch all this time
despite the zebra red rocket special portland beats those jersey shore floppers
my favorite dc restaurant is charlie palmers sweet me lissa sassylibrarian taotao salupa tingtingbabyyyy
now i seperate from niggas i don t trust niggas that ain t starve wit me and all the bitches i didn t fuc
bixxhmakemerich if u ask me every bitch gay or bi
lmaooo rt handsomeesco she a tranny if she can open a jar of pickles by herself
rt hitmanholla rt ayeverb ok i m watching mook vs lux neither of them was good but mook won this wasn t close to me vs hitm 这里类属性可以假设为三个类别值:仇恨言论为0,***性语言为1,两者均无为2。
训练机器学习分类器之前,应先将推文文本转换为数字。可以使用scikit-learn中的TfidfVectorizer来完成这项任务,它将文本转换为术语频率乘以逆文档频率(tf-idf)值的矩阵,此方法适用于机器学习。另外,在这个过程中可以删除停用词(一些常用词例如:the,is等)。
对于文本分类而言,支持向量机(SVM)是一个可靠的选择。由于它们是二元分类器,我们将使用One-Vs-Rest策略,其中对于每个类别,SVM都会将其单独区分开。
通过使用scikit-learn的Pipeline功能并定义相应的步骤可以在一个命令中执行文本向量化和SVM训练:
from sklearn.pipeline import make_pipeline
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.multiclass import OneVsRestClassifier
from sklearn.svm import SVC
from stop_words import get_stop_words
clf = make_pipeline(
TfidfVectorizer(stop_words=get_stop_words(‘en‘)),
OneVsRestClassifier(SVC(kernel=‘linear‘, probability=True)))
clf = clf.fit(X=df[‘tweet‘], y=df[‘class‘]这时,应该评估模型的性能,例如使用交叉验证方法计算分类指标。但是由于本教程侧重于模型部署,我们将跳过此步骤(但在实际项目中请不要这样操作)。原文中描述的参数调整或自然语言处理的其他技术也需要这样做。
详情:https://arxiv.org/abs/1703.04009
现在可以尝试一个测试文本,并让模型预测概率:
text = "I hate you, please die!"
clf.predict_proba([text.lower()])
# Output:
array([0.64, 0.14, 0.22]数组中的数字对应于三个类别的概率(仇恨言论,***性语言,两者均无)。
使用joblib模块,可以将模型作为二进制对象保存到磁盘里,这样就可以在应用程序中加载和使用该模型。
from sklearn import externals
model_filename = ‘hatespeech.joblib.z‘
externals.joblib.dump(clf, model_filename)
Python文件app.py会加载模型并定义一个简单的模块级函数,该函数会对模型的predict_proba函数进行调用:
from sklearn import externals
model_filename = ‘hatespeech.joblib.z‘
clf = externals.joblib.load(model_filename)
def predict(text):
probas = clf.predict_proba([text.lower()])[0]
return {‘hate speech‘: probas[0],
‘offensive language‘: probas[1],
‘neither‘: probas[2]}现在,使用firefly,一个用作服务的轻量级的python模块。对于高级配置或在生产环境中使用而言,Flask或Falcon可能是更好的选择,因为它们已经与大型社区建立了良好的关系,所以在快速原型的制作中,我们经常会使用firefly。
在命令行上使用firefly将predict函数绑定到localhost上的端口5000上:
$ firefly app.predict --bind 127.0.0.1:5000通过curl,可以向创建的端点发出POST请求并获得预测:
$ curl -d ‘{"text": "Please respect each other."}‘ \ http://127.0.0.1:5000/predict
# Output:
{"hate speech": 0.04, "offensive language": 0.31, "neither": 0.65}当然,成熟的实际应用程序中会有很多的附加功能(日志记录,输入和输出验证,异常处理...)及工作步骤(文档,版本控制,测试,监控...),但在这里我们只部署一个简单的原型。

为何选择Docker?这是因为Docker容器可在隔离的环境中运行应用程序,它包含所有从属项,并且可以作为映像发布,从而简化服务设置和扩展。
必须在名为Dockerfile的文件中配置容器的内容以及启动操作:
FROM python:3.6
RUN pip install scikit-learn==0.20.2 firefly-python==0.1.15
COPY app.py hatespeech.joblib.z ./
CMD firefly app.predict --bind 0.0.0.0:5000
EXPOSE 5000前三行是将python:3.6作为基本图像,另外安装scikit-learn和firefly(与开发环境中的版本相同)并复制内部的应用和模型文件。后两行则是Docker在启动容器时应执行的命令以及其应该显示的端口5000。
创建图像hatespeechdetect的构建过程通过以下方式启动:
$ docker build . -t hatespeechdetectrun命令启动一个从图像派生的容器。另外,通过-poption将容器的端口5000绑定到主机的端口3000:
$ docker run -p 3000:5000 -d hatespeechdetect现在,可以发送请求并获得预测:
$ curl -d ‘{"text": "You are fake news media! Crooked!"}‘ \ http://127.0.0.1:3000/predict
# Output:
{"hate speech": 0.08, "offensive language": 0.76, "neither": 0.16}在此示例中,容器是在本地运行。当然,实际目的是使其在永久位置运行,并可能通过在企业集群中启动多个容器来扩展服务。

让应用程序公开可用的一种方法是使用平台作为服务,例如Heroku,它支持Docker并提供免费的基本会员资格。要使用它,必须注册一个帐户并安装Heroku CLI。
Heroku的应用程序容器公开了一个动态端口,需要在我们的Dockerfile中进行编辑:必须将端口5000更改为环境变量PORT:
CMD firefly app.predict --bind 0.0.0.0:$PORT在此更改之后,我们已准备好进行部署。在命令行中,登录到heroku(这将提示我们在浏览器中输入凭据)并创建一个名为hate-speech-detector的应用程序:
$ heroku login
$ heroku create hate-speech-detector然后登录到容器注册表。heroku容器:push 将根据当前目录中的Dockerfile构建一个映像,并将其发送到Heroku Container注册表。之后,可以将图像发布到应用程序:
$ heroku container:login
$ heroku container:push web --app hate-speech-detector
$ heroku container:release web --app hate-speech-detector和以往一样,API可以通过curl来解决。但是,这一次,该服务不是在本地运行,而是可供全世界使用!
$ curl -d ‘{“text”: “You dumb idiot!”}’
https://hate-speech-detector.herokuapp.com/predict
# Output:
{"hate speech": 0.26, "offensive language": 0.68, "neither": 0.06}现在,缩放应用程序只需点击几下即可。此外,需要将服务连接到留言板,而且需要设置触发阈值并实施警报。

蔡徐坤本身人畜无害,粉丝们的喜爱也无可厚非。不过粉丝们的集体控评、强制安利的群众运动却会大大煽动情绪。最终会演变为言语暴力、道德绑架威胁甚至人身伤害。

比如某ikun粉以割腕威胁某博主:”再黑蔡徐坤,我就自杀“。花季少女直播割腕鲜血直流。
粉丝和idol的“命运共同体”,不应该是伤害和被伤害的命运。不吹不黑,理性追星。
网上的热搜就像气球,时时爆炸。不是明星出轨就是小三被打。评论区也是三教九流,一片繁荣。
看到美女自拍就在言语上情色意淫,一有地震洪水就质问明星捐款几何,还有各种阶级黑,城市看不起乡村,中产瞧不上贫农。这两天,作家编剧六六竟公然地域尬黑,网上唏嘘一片。

网络时代提供的技术和渠道,应该是平等的。不应允许少数人的专横,也不应鼓吹多数人的暴政。
人言可畏。
网络环境,是时候该管管了。

编译组:余欣桐、胡婷
相关链接:
https://towardsdatascience.com/creating-and-deploying-a-python-machine-learning-service-a06c341f020f
如需转载,请后台留言,遵守转载规范ACL2018论文集50篇解读
EMNLP2017论文集28篇论文解读
2018年AI三大顶会中国学术成果全链接
ACL2017 论文集:34篇解读干货全在这里
10篇AAAI2017经典论文回顾
标签:iss sda 日常 作家 自动 图片 elf fda 必须
原文地址:https://blog.51cto.com/15057819/2567722