标签:rgs ast 保留 core aaa 注释 干货 str ade

共享单车变共享垃圾,这个曾红极一时的新鲜玩意儿,终究日薄西山。
因随即取用的便利性,共享单车迅速占领市场,这也是这一产业的最大bug。无码头停放带来的管理成本和对城市公共资源的占用,搞垮了“共享经济”的鼻祖。
而国外的共享单车多数仍保留着停车桩或固定停放站点的租用模式,重点关注车辆的维护和管理,整体市场不温不火。

图片来源:Pexels
反观国内,小黄小蓝小绿五彩缤纷,各家激烈商战,模式照搬。疯狂“大炼钢铁”,导致市场供需比例失衡,最终落得个尸横遍野的下场。

对于单车区域投放而言,数量的合理分配对平衡供需关系及其重要。
本文将在C#,NET Core和ML.NET中构建一个线性回归模型,并在共享单车需求数据集上对其进行训练。
然后,就可以科学地预测出某天某时某地需要投放多少辆共享单车了。

图片来源:Pexels
ML.NET是微软的新机器学习库,可以运行线性回归,逻辑分类,聚类,深度学习和许多其他机器学习算法。
磊科是一个能在Windows中,OS / X和Linux上运行的微软多平台NET框架。这是跨平台NET发展的未来。
首先,需要一个有很多共享单车需求数字的数据文件。我们使用大都会特区Capital Bikeshare的UCI Bike Sharing Dataset。该数据集有17380辆单车记录,时间跨度为两年。
文件如下:
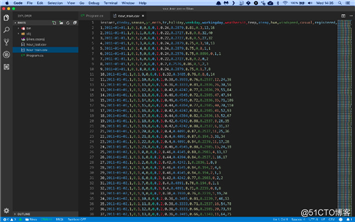
它含有17列的逗号分隔文件:
?即时:记录索引
?日期:观察日期
?季节:季节(1 =春季,2 =夏季,3 =秋季,4 =冬季)
?年份:观察年份(0 = 2011,1 = 2012)
?月:观察月份(1至12)
?小时:观察时间(0至23)
?假日:是否是节假日
?平日:观察的一周中的某一天
?WorkingDay:是否是工作日
?天气:观测期间的天气(1 =晴朗,2 =薄雾,3 =小雪/雨,4 =大雨)
?温度:标准温度(摄氏度)
?ATemperature:标准体感温度(摄氏度)
?湿度:标准湿度
?强风:标准风速
?休闲:当时空闲单车用户的数量
?注册:当时注册的单车用户数量
?计数:当时运行的租用单车总数
忽略记录索引,日期和空闲单车和注册单车的数量,并将其他所有内容用作输入特征。最后的列计数是试图预测的数字。
通过构建一个线性回归模型,读取所有的特征列,然后对运行中的出租自行车总数,每个日期,时间和天气条件进行预测。
以下是如何在NET Core中创建新的控制台项目:
$ dotnet new console -o Bikes
$ cd自行车接下来,安装ML.NET基本包:
$ dotnet add package Microsoft.ML安装名为BetterConsoleTables的包来显示模型运行结果:
$ dotnet add package BetterConsoleTables现在准备添加一些类。需要一个类来实现共享单车需求观察,一个类来实现模型的预测。
修改Program.cs的文件:
/// <summary>
/// DemandObservation类拥有一个单一的自行车需求观察记录。
/// </ summary>
公共类DemandObservation
{
[LoadColumn(2)] public float Season {get; 组; }
[LoadColumn(3)] public float Year {get; 组; }
[LoadColumn(4)] public float Month {get; 组; }
[LoadColumn(5)] public float Hour {get; 组; }
[LoadColumn(6)] public float Holiday {get; 组; }
[LoadColumn(7)] public float Weekday {get; 组; }
[LoadColumn(8)] public float WorkingDay {get; 组; }
[LoadColumn(9)] public float天气{get; 组; }
[LoadColumn(10)] public float Temperature {get; 组; }
[LoadColumn(11)] public float NormalizedTemperature {get; 组; }
[LoadColumn(12)] public float Humidity {get; 组; }
[LoadColumn(13)] public float Windspeed {get; 组; }
[LoadColumn(16)] [ColumnName(“Label”)] public float Count {get; 组; }
}
/// <summary>
/// DemandPrediction类包含一个单一的自行车需求预测。
/// </ summary>
公共类DemandPrediction
{
[的ColumnName( “分数”)]
public float PredictedCount;
}DemandObservation类可实现一次出租车出行。注意每个字段如何用一个列属性来修饰,该属性告诉CSV数据加载代码从哪个列导入数据。
我们还将使用一个DemandPrediction类,它将实现单车需求预测。
现在把训练数据载入内存:
/// <summary>
///主程序类。
/// </ summary>
静态类程序
{
//数据集的文件名
private static string trainDataPath = Path.Combine(Environment.CurrentDirectory,“hour_train.csv”);
private static string testDataPath = Path.Combine(Environment.CurrentDirectory,“hour_test.csv”);
static void Main(string [] args)
{
//创建机器学习环境
var context = new MLContext();
// load training and test data
Console.WriteLine("Loading data…");
var trainingData = context.Data.LoadFromTextFile<DemandObservation>(
path: trainDataPath,
hasHeader:true,
separatorChar: ‘,‘);
var testData = context.Data.LoadFromTextFile<DemandObservation>(
path: testDataPath,
hasHeader:true,
separatorChar: ‘,‘);
// the rest of the code goes here…
}
}此代码使用LoadFromTextFile方法将训练和测试数据直接载入内存中。类字段注释会告诉方法如何将加载的数据存储在DemandObservation类中。
现在,开始构建机器学习管道:
// build a training pipeline
// step 1: concatenate all feature columns
var pipeline = context.Transforms.Concatenate(
DefaultColumnNames.Features,
nameof(DemandObservation.Season),
nameof(DemandObservation.Year),
nameof(DemandObservation.Month),
nameof(DemandObservation.Hour),
nameof(DemandObservation.Holiday),
nameof(DemandObservation.Weekday),
nameof(DemandObservation.WorkingDay),
nameof(DemandObservation.Weather),
nameof(DemandObservation.Temperature),
nameof(DemandObservation.NormalizedTemperature),
nameof(DemandObservation.Humidity),
nameof(DemandObservation.Windspeed))
//第2步:缓存数据以加快培训速度
.AppendCacheCheckpoint(上下文);
//剩下的代码就在这里......ML.NET中的机器学习模型是通过管道构建的,管道是数据加载,转换和学习组件的序列。
管道包含以下组件:
?串联,它将所有输入数据列合并为一个称为“特征”的列。这个步骤必不可少,因为ML.NET只能在单个输入列上进行训练。
?AppendCacheCheckpoint,用于缓存此时的所有训练数据。这是一个加速学习算法的优化步骤。
应该使用哪种训练算法来建立模型?
或许可以尝试FastTree,或StochasticDualCoordinateAscent,或泊松回归?
我们来尝试四种算法,看看哪种算法产生的结果最低。
均方根误差(RMSE):SDCA,PoissonRegression,FastTree,和FastTreeTweedie
以下是如何使用该四种算法训练模型:
//设置一系列学习者尝试
(string Name, IEstimator<ITransformer> Learner)[] regressionLearners =
{
("SDCA", context.Regression.Trainers.StochasticDualCoordinateAscent()),
("Poisson", context.Regression.Trainers.PoissonRegression()),
("FastTree", context.Regression.Trainers.FastTree()),
("FastTreeTweedie", context.Regression.Trainers.FastTreeTweedie())
};
// prepare a console table to hold the results
var results = new Table(TableConfiguration.Unicode(), "Learner", "RMSE", "L1", "L2", "Prediction");
// train the model on each learner
foreach (var learner in regressionLearners)
{
Console.WriteLine($"Training and evaluating model using {learner.Name} learner…");
// add the learner to the training pipeline
var fullPipeline = pipeline.Append(learner.Learner);
//训练模型
var trainedModel = fullPipeline.Fit(trainingData);
//剩下的代码就在这里......
}
//显示结果
Console.WriteLine(results.ToString());这段代码建立了一个包含各个训练算法名称和类的元组数组。接着,用一个简单的用于循环将每个算法附加到管道中,并调用飞度(...)来训练模型从而测试每个算法。
同时请注意在循环开始之前,如何在结果变量中设置控制台,并在循环结束时显示结果。表是BetterConsoleTables包中的一个助手类,它将以非常好的表格格式显示最终结果。
现在,有了一个已受训练的模型接下来,需要获取测试数据,预测每个数据记录的单车需求,并将其与实际值进行比较:
//评估模型
var predictions = trainedModel.Transform(testData);
var metrics = context.Regression.Evaluate(
数据:预测,
标签:DefaultColumnNames.Label,
得分:DefaultColumnNames.Score);
//剩下的代码就在这里......此代码调用变换(...)为文件中的每个单车需求记录设置预测(值)。然后,评估(...)将这些预测值与实际单车需求(量)进行比较,并自动计算三个非常便于使用的指标:
?metrics.Rms:这是均方根误差或RMSE值在机器学习领域中,评估模型并对其准确性进行评级是一种重要的度量方法.RMSE表示一个向量在?维空间中的长度,由每个预测中的误差组成。
?metrics.L1:这是平均绝对预测误差,以单车数量表示。
?metrics.L2:这是均方预测误差,或MSE值。注意,RMSE和MSE是相关的:RMSE只是MSE的平方根。
下面让我们使用模型进行预测。
// set up a sample observation
var sample = new DemandObservation()
{
Season = 3,
Year = 1,
Month = 8,
Hour = 10,
Holiday = 0,
Weekday = 4,
WorkingDay = 1,
Weather = 1,
Temperature = 0.8f,
NormalizedTemperature = 0.7576f,
Humidity = 0.55f,
Windspeed = 0.2239f
};
// create a prediction engine
var engine = trainedModel.CreatePredictionEngine<DemandObservation, DemandPrediction>(context);
// make the prediction
var prediction = engine.Predict(sample);
// the rest of the code goes here…创建一个2012年秋季的新自行车纪录,在8月的一个周四上午10点,天气晴朗。
CreatePredictionEngine方法设置预测引擎。两个类型参数是输入数据类和用于保存预测的类。然后只需调用Predict(...)进行单一预测。
需要做的最后一件事是收集控制台表中的所有结果:
// store all results in the console table
results.AddRow(
learner.Name,
metrics.Rms.ToString("0.##"),
metrics.L1.ToString( “0。##”),
metrics.L2.ToString( “0。##”),
prediction.PredictedCount.ToString( “0”)AddRow()方法将新行添加到控制台表。训练算法放在第1列,然后是RMSE,L1得分,L2得分和样本的需求预测。
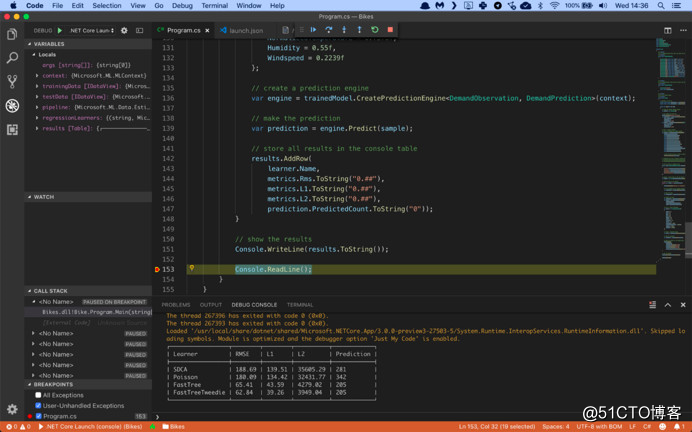
看看模型是多么准确。这是在Mac上的Visual Studio Code调试器中运行的代码:
应用程序再次在zsh shell中运行:
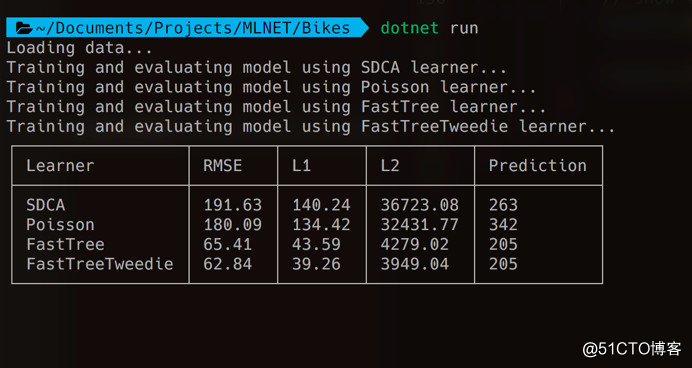
SDCA的表现最差,RMSE为191.63.Poisson回归只是略微好一点。赢家显然是运用了是快速树算法的FastTreeTweedie,RMSE仅为62.84。
L1分数表示每个预测中的平均误差。看看FastTreeTweedie,这意味着模型平均只有39辆自行车。
在本样本中,模型预测我们将需要205辆自行车来满足需求,在8月的星期四上午10点清晨。鉴于L1得分,应该添加39辆自行车才能安全并且总共分配244辆。
精确到点的预测,你还不mark一下?说不定这是拯救摩拜和哈罗的唯一机会了!

编译组:高亚晶,柯梓瑜
相关链接:
https://medium.com/machinelearningadvantage/predict-bike-sharing-demand-in-washington-dc-with-c-and-ml-net-machine-learning-5550ca26c6df
如需转载,请后台留言,遵守转载规范ACL2018论文集50篇解读
EMNLP2017论文集28篇论文解读
2018年AI三大顶会中国学术成果全链接
ACL2017论文集:34篇解读干货全在这里
10篇AAAI2017经典论文回顾
标签:rgs ast 保留 core aaa 注释 干货 str ade
原文地址:https://blog.51cto.com/15057819/2567710