标签:min 没有 inf 功能 索引 legend 定义 mod 影响
一、sklearn中的决策树模块:sklearn.tree
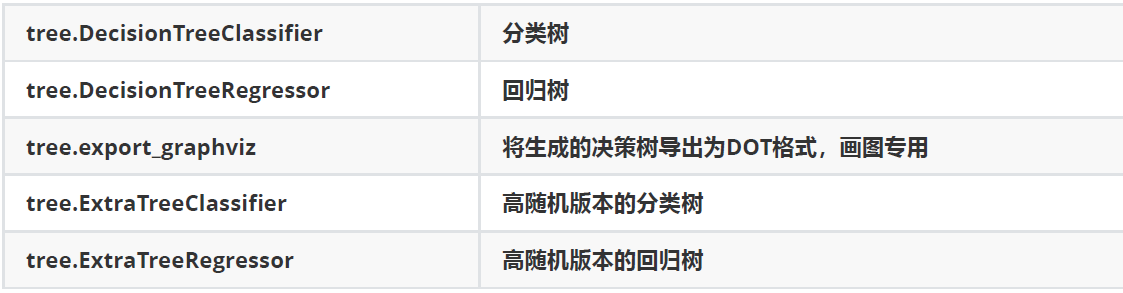
1、sklearn中决策树的类都在‘tree’这个模块之下。这个模块 总共包含五个类:
2、sklearn的基本建模流程
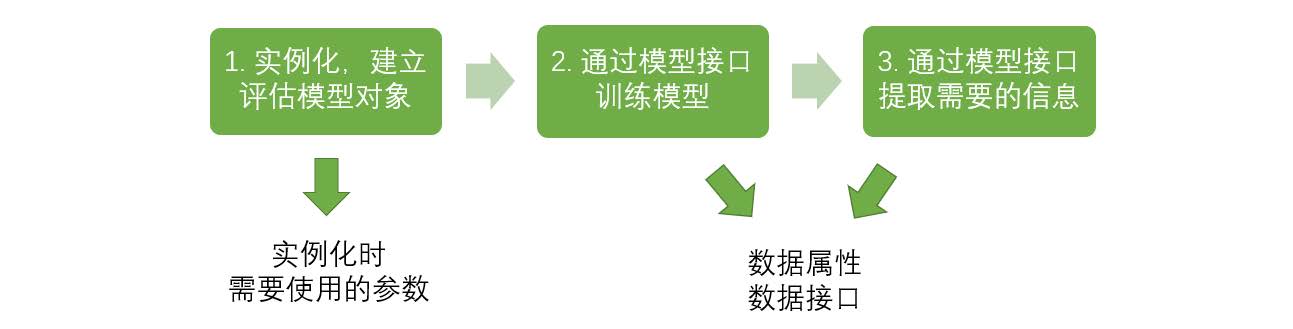
3、下面对sklearn.tree这个模块之下的决策树类进行逐个说明:
3.1、分类树:tree.DecisionTreeClassifier()
class sklearn.tree.DecisionTreeClassifier (criterion=’gini’, splitter=’best’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, class_weight=None, presort=False)
重要参数:
(1)criterion:
Criterion这个参数正是用来决定不纯度的计算方法的。sklearn提供了两种选择:
1)输入”entropy“,使用信息熵(Entropy)
2)输入”gini“,使用基尼系数(Gini Impurity)
(2)random_state & splitter:
random_state用来设置分枝中的随机模式的参数,默认为None,设置的话,是为了保证每次随机生成的数是一致的(即使是随机的);
如果不设置,那么每次生成的随机数都是不同的,也就是说决策树其实是随机的(可以通过多运行几次score测试下)。
splitter也是用来控制决策树中的随机选项的,有两种输入值:
1)输入”best",决策树在分枝时虽然随机,但是还是会优先选择更重要的特征进行分枝。重要性可以通过属性feature_importances_查看。
2)输入“random",决策树在分枝时会更加随机,树会因为含有更多的不必要信息而更深更大,并因这些不必要信息而降低对训练集的拟合。这也是防止过拟合的一种方式。
当你预测到你的模型会过拟合,用这两个参数来帮助你降低树建成之后过拟合的可能性。当然,树一旦建成,我们依然是使用剪枝参数来防止过拟合。
(3)剪枝参数:
注释:不加限制时,决策树会生长到没有更多的特征可用为止,但这样往往会造成过拟合,既训练集上表现很好,测试集上表现却很差。因此为了让模型有更好的泛化性,我们需要
对决策树进行剪枝。
1)剪枝参数1:max_depth
目的:限制树的最大深度,超过设定深度的树枝全部剪掉。在高纬度低样本量时非常有效,决策树每多生长一层,对样本的需求量会增加一倍。所以限制树的深度有利于防止过拟合。
建议:实际使用时,建议从=3开始尝试,看看拟合的效果在决定是否增加深度。
2)剪枝参数2:min_samples_leaf & min_samples_split
min_samples_leaf : 该参数限定,一个节点在分枝后的每个子节点都必须包含至少min_samples_leaf个训练样本,否则分支就不会发生。
建议:该参数设置的太小会引起过拟合,太大会阻止模型学习数据,一般搭配max_depth使用。
min_samples_split : 该参数限定,一个节点必须包含至少min_samples_split个训练样本,这个节点才允许被分枝,否则分支就不会发生。
3)剪枝参数3:max_features & min_impurity_decrease
max_features : 该参数限定,分枝时需考虑的特征个数,超过限制个数的特征都会被舍弃。该参数是用来限制高纬度数据的过拟合的剪枝参数。
min_impurity_decrease : 该参数限定信息增益的大小,信息增益小于设定数值的分枝不会发生。为0.19版本中更新的功能,0.19版本之前使用的时min_impurity_split。
4)确定最优的剪枝参数的时候,可以采取如下方式:
import matplotlib.pyplot as plt
test = []
for i in range(10):
clf = tree.DecisionTreeClassifier(max_depth=i+1
,criterion="entropy"
,random_state=30
,splitter="random"
)
clf = clf.fit(Xtrain, Ytrain)
score = clf.score(Xtest, Ytest)
test.append(score)
plt.plot(range(1,11),test,color="red",label="max_depth")
plt.legend()
plt.show()
(4)目标权重参数:
1)class_weight & min_weight_fraction_leaf
class_weight :
该参数默认为None,表示自动给数据集中所有标签相同的权重
该参数为‘blanced’时,每个类别的权重为该类别样本数的倒数。个人觉得惩罚项就用样本量的倒数未尝不可,因为乘以样本量都是1,相当于‘balanced‘这里是多乘以了一个常数.
也可手动输入权重,代码举例如下:
import numpy as np
y = [0,0,0,0,0,0,0,0,1,1,1,1,1,1,2,2] #标签值,一共16个样本
from sklearn.utils.class_weight import compute_class_weight
class_weight = {0:1,1:3,2:5} # {class_label_1:weight_1, class_label_2:weight_2, class_label_3:weight_3}
classes = np.array([0, 1, 2]) #标签类别
weight = compute_class_weight(class_weight, classes, y)
print(weight) # 输出:[1. 3. 5.],也就是字典中设置的值
min_weight_fraction_leaf : 有了权重之后,样本量就不再是单纯地记录数目,而是受输入的权重影响了,因此这时候剪枝,就需要搭配min_weight_fraction_leaf这个基于权重的剪枝参数来使用。
附::tree.DecisionTreeClassifier中的重要属性与接口如下:
#对数据进行拟合
clf.fit(Xtrain,Ytrain)
#求得测试集的准确率
clf.score(Xtest,Ytest)
#apply返回每个测试样本所在的叶子节点的索引
clf.apply(Xtest)
#predict返回每个测试样本的分类/回归结果
clf.predict(Xtest)
总结:分类树需要掌握的八个参数,一个属性,四个接口:
八个参数:Criterion,两个随机性相关的参数(random_state,splitter),五个剪枝参数(max_depth,
min_samples_split,min_samples_leaf,max_feature,min_impurity_decrease)
一个属性(该参数用于查看哪个特征对预测结果贡献最大):feature_importances_
四个接口:fit,score,apply,predict
3.2、tree.DecisionTreeRegressor
class sklearn.tree.DecisionTreeRegressor (criterion=’mse’, splitter=’best’, max_depth=None,
min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None,
random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, presort=False)
注释:几乎所有参数,属性及接口都和分类树一样,但要注意的是,回归树中没有标签分布是否均衡的问题,依次没有class_weight这样的参数。
3.2.1 重要参数属性及接口:
(1)criterion:
1)输入‘mse’ : 使用均方误差。mse的公式如下:
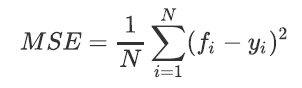
其中N是样本数量,i是每一个数据样本,fi是模型回归出的数值,yi是样本点i实际的数值标签。MSE的本质是样本真实数据与回归结果的差异。
2)输入‘friedman_mse’ : 使用费尔德曼均方误差。
3)输入‘mae’ : 使用绝对平均误差MAE(mean absolute error)
(2)重要属性:最重要的依然是feature_importances_
(3)重要接口:依然是apply,fit,pridect,score最核心。
3.2.2 接口score
回归树的接口score返回的是R平方,并不是MSE。R平方被定义如下:
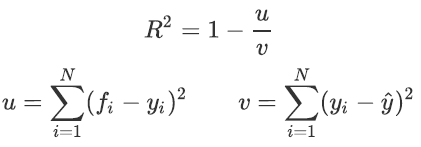
其中u是残差平方和(MSE*N),v是总平方和,N是样本数量,i是每一个数据样本,fi是模型回归出的数值,yi是样本点i实际的数值标签,y帽是真实数值标签
的平均数。R平方可以为正也可为负,当模型的残差平方和远远大于模型的总平方和,模型非常糟糕,R平方就会为负,而均方误差永远为正。但在sklearn中,
虽然均方误差永远为正,但是sklearn当中使用军方误差作为评判标准时,却是计算的‘负均方误差’,这是因为sklearn在计算模型评估指标的时候,会考虑指标本身的性质,
均方误差本身是一种误差,所以被sklearn划分为模型的一种损失(loss),因此在sklearn当中,都以负数表示。真正的均方误差MSE的数值,其实就是neg_mean_squared_error
去掉负号的数字。
实例:
from sklearn.datasets import load_boston
from sklearn.model_selection import cross_val_score
from sklearn.tree import DecisionTreeRegressor
boston = load_boston()
regressor = DecisionTreeRegressor(random_state=0)
cross_val_score(regressor, boston.data, boston.target, cv=10,
scoring = "neg_mean_squared_error")
3.3、tree.export_graphviz()
目的:绘图专用,将生成的决策树转化为dot格式,方便可视化。
实例:
例1:
feature_name = [‘酒精‘,‘苹果酸‘,‘灰‘,‘灰的碱性‘,‘镁‘,‘总酚‘,‘类黄酮‘,‘非黄烷类酚类‘,‘花青素‘,‘颜色强度‘,‘色调‘,‘od280/od315稀释葡萄酒‘,‘脯氨酸‘]
import graphviz
dot_data = tree.export_graphviz(clf
,feature_names= feature_name
,class_names=["琴酒","雪莉","贝尔摩德"] # 标签名字
,filled=True # 到底填不填充颜色,颜色越深,代表不纯度越低,且叶子节点的每个颜色代表一个类别。
,rounded=True # 框的形状
,out_file=None
)
graph = graphviz.Source(dot_data) # 将我们画的树给导出来
graph
例2:
dot_data = tree.export_graphviz(clf
,out_file=None,
,feature_names=iris.feature_names
,class_names=iris.target_names
,filled=True
,rounded=True
,special_characters=True
)
graph = graphviz.Source(dot_data)
graph
其中,out_file为dot输出的目录;
feature_names为特征的名字;
class_names为标签的名字;
filled=True,到底填补填充颜色,颜色越深,代表不纯度越低,且叶子节点的每个颜色代表一个类别。
rounded=True,为框的形状。
高随机版本的分类树和回归树暂时先不记笔记。
标签:min 没有 inf 功能 索引 legend 定义 mod 影响
原文地址:https://www.cnblogs.com/wdkblog/p/14175449.html