标签:不为 优化 它的 with 梯度 最好 条件 前言 ofo

文 | 苏剑林(追一科技,人称苏神)
美 | 人美心细小谨思密达
前言
这篇文章简单介绍一个叫做AdaX的优化器,来自《AdaX: Adaptive Gradient Descent with Exponential Long Term Memory》。介绍这个优化器的原因是它再次印证了之前在《硬核推导Google AdaFactor:一个省显存的宝藏优化器》一文中提到的一个结论,两篇文章可以对比着阅读。
Adam & AdaX
AdaX的更新格式是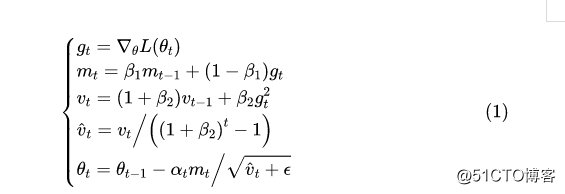
其中的默认值是0.0001。对了,顺便附上自己的Keras实现:https://github.com/bojone/adax 作为比较,Adam的更新格式是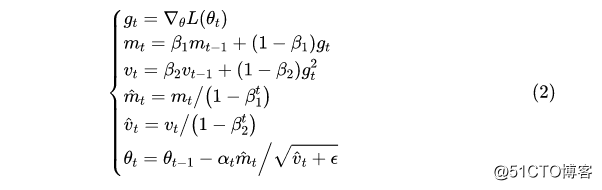
其中的默认值是0.999。
等价形式变换
可以看到,两者的第一个差别是AdaX去掉了动量的偏置校正(这一步),但这其实影响不大,AdaX最大的改动是在处,本来是滑动平均格式,而不像是滑动平均了,而且,似乎有指数爆炸的风险?
原论文称之为“with Exponential Long Term Memory”,就是指
β
导致历史累积梯度的比重不会越来越小,反而会越来越大,这就是它的长期记忆性。
事实上,学习率校正用的是,所以有没有爆炸我们要观察的是。对于Adam,我们有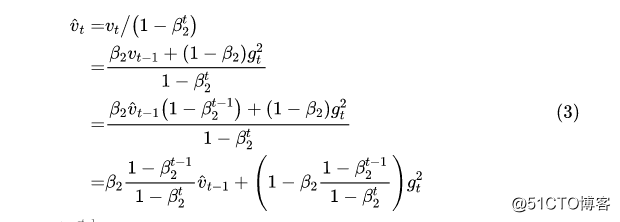
所以如果设,那么更新公式就是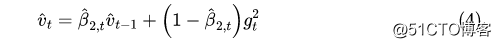
基于同样的道理,如果设,那么AdaX的的更新公式也可以写成上式。
衰减策略比较
所以,从真正用来校正梯度的来看,不管是Adam还是AdaX,其更新公式都是滑动平均的格式,只不过对应的衰减系数不一样。
对于Adam来说,当时t = 0,,这时候就是,也就是用实时梯度来校正学习率,这时候校正力度最大;当时,,这时候是累积梯度平方与当前梯度平方的加权平均,由于,所以意味着当前梯度的权重不为0,这可能导致训练不稳定,因为训练后期梯度变小,训练本身趋于稳定,校正学习率的意义就不大了,因此学习率的校正力度应该变小,并且,学习率最好恒定为常数(这时候相当于退化为SGD),这就要求时,。
对于AdaX来说,当t = 0时,当,,满足上述的理想性质,因此,从这个角度来看,AdaX确实是Adam的一个改进。在AdaFactor中使用的则是,它也是从这个角度设计的。至于AdaX和AdaFactor的策略孰优孰劣,笔者认为就很难从理论上解释清楚了,估计只能靠实验。
就这样结束了
嗯,文章就到这儿结束了。开头就说了,本文只是简单介绍一下AdaX,因为它再次印证了之前的一个结论——应当满足条件“”,这也许会成为日后优化器改进的基本条件之一。
标签:不为 优化 它的 with 梯度 最好 条件 前言 ofo
原文地址:https://blog.51cto.com/15061930/2570136