标签:情况 代码实现 head ade 展示 不能 tps 字节 lazy
压缩列表是 ZSET、HASH和 LIST 类型的其中一种编码的底层实现,是由一系列特殊编码的连续内存块组成的顺序型数据结构,其目的是节省内存。
下图展示了压缩列表的组成:
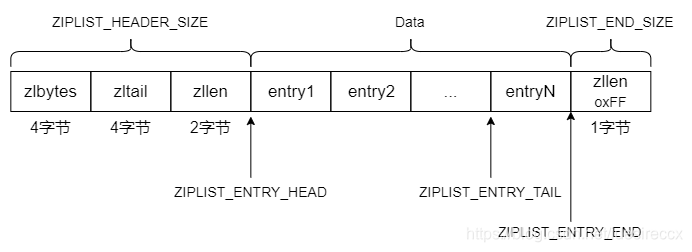
各个字段的含义如下:
zlbytes:是一个无符号 4 字节整数,保存着 ziplist 使用的内存数量。zlbytes,程序可以直接对 ziplist 的内存大小进行调整,无须为了计算 ziplist 的内存大小而遍历整个列表。zltail:压缩列表 最后一个 entry 距离起始地址的偏移量,占 4 个字节。pop 操作可以在无须遍历整个列表的情况下进行。zllen:压缩列表的节点 entry 数目,占 2 个字节。2^16 - 2 的时候,zllen 会设置为2^16-1,当程序查询到值为2^16-1,就需要遍历整个压缩列表才能获取到元素数目。所以 zllen 并不能替代 zltail。entryX:压缩列表存储数据的节点,可以为字节数组或者整数。zlend:压缩列表的结尾,占一个字节,恒为 0xFF。实现的代码 ziplist.c 中,ziplist 定义成了宏属性。
// 相当于 zlbytes,ziplist 使用的内存字节数
#define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl)))
// 相当于 zltail,最后一个 entry 距离 ziplist 起始位置的偏移量
#define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t))))
// 相当于 zllen,entry 的数量
#define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2)))
// zlbytes + zltail + zllen 的长度,也就是 4 + 4 + 2 = 10
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t))
// zlend 的长度,1 字节
#define ZIPLIST_END_SIZE (sizeof(uint8_t))
// 指向第一个 entry 起始位置的指针
#define ZIPLIST_ENTRY_HEAD(zl) ((zl)+ZIPLIST_HEADER_SIZE)
// 指向最后一个 entry 起始位置的指针
#define ZIPLIST_ENTRY_TAIL(zl) ((zl)+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl)))
// 相当于 zlend,指向 ziplist 最后一个字节
#define ZIPLIST_ENTRY_END(zl) ((zl)+intrev32ifbe(ZIPLIST_BYTES(zl))-1)
以下是重建新的空 ziplist 的代码实现,在 ziplist.c 中:
unsigned char *ziplistNew(void) {
// ziplist 头加上结尾标志字节数,就是 ziplist 使用内存的字节数了
unsigned int bytes = ZIPLIST_HEADER_SIZE+ZIPLIST_END_SIZE;
unsigned char *zl = zmalloc(bytes);
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
// 因为没有 entry 列表,所以尾部偏移量是 ZIPLIST_HEADER_SIZE
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
// entry 节点数量是 0
ZIPLIST_LENGTH(zl) = 0;
// 设置尾标识。
// #define ZIP_END 255
zl[bytes-1] = ZIP_END;
return zl;
}
节点的结构一般是:<prevlen> <encoding> <entry-data>
prevlen:前一个 entry 的大小,用于反向遍历。encoding:编码,由于 ziplist 就是用来节省空间的,所以 ziplist 有多种编码,用来表示不同长度的字符串或整数。data:用于存储 entry 真实的数据;节点的 prevlen 属性以字节为单位,记录了压缩列表中前一个节点的长度。编码长度可以是 1 字节或者 5 字节。
下图展示了 1 字节 和 5 字节 prevlen 的示意图(来源)
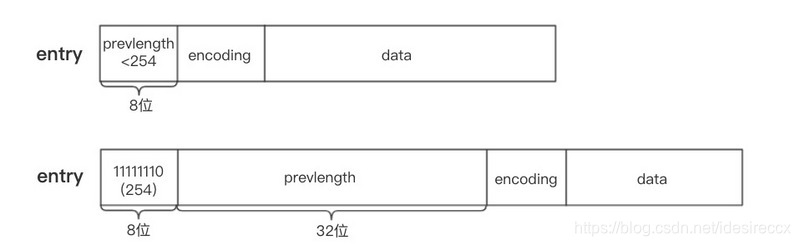
prevlen 属性主要的作用是反向遍历。通过 ziplist 的 zltail,我们可以得到最后一个节点的位置,接着可以获取到前一个节点的长度 len,指针向前移动 len,就是指向倒数第二个节点的位置了。以此类推,可以一直往前遍历。
encoding 记录了节点的 data 属性所保存数据的类型和长度。类型主要有两种:字符串和整数。
如果 encoding 以 00、01 或者 10 开头,就表示数据类型是字符串。
#define ZIP_STR_06B (0 << 6)
#define ZIP_STR_14B (1 << 6)
#define ZIP_STR_32B (2 << 6)
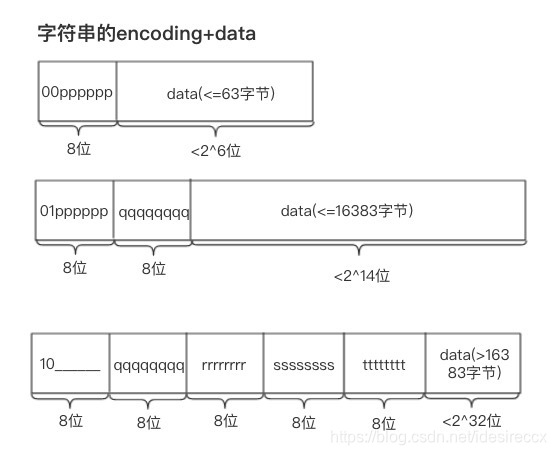
字符串有三种编码:
长度 < 2^6 时,以 00 开头,后 6 位表示 data 的长度,。2^6 <= 长度 < 2^14 时,以 01 开头,后续 6 位 + 下一个字节的 8 位 = 14 位表示 data 的长度。2^14 <= 长度 < 2^32 字节时,以 10 开头,后续 6 位不用,从下一字节起连续 32 位表示 data 的长度。下图为字符串三种长度结构的示意图(来源):
如果 encoding 以 11 开头,就表示数据类型是整数。
#define ZIP_INT_16B (0xc0 | 0<<4)
#define ZIP_INT_32B (0xc0 | 1<<4)
#define ZIP_INT_64B (0xc0 | 2<<4)
#define ZIP_INT_24B (0xc0 | 3<<4)
#define ZIP_INT_8B 0xfe
#define ZIP_INT_IMM_MIN 0xf1 /* 11110001 */
#define ZIP_INT_IMM_MAX 0xfd /* 11111101 */
整数一共有 6 种编码,说起来麻烦,看图吧(来源)。
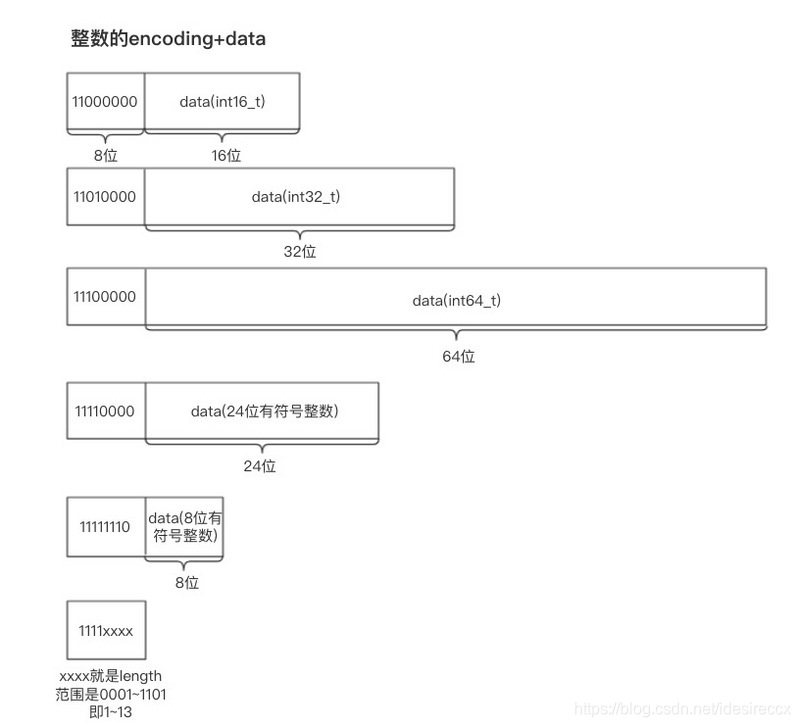
看了上图的最后一个类型,可能有小伙伴就有疑问:为啥没有 11111111 ?
答:因为 11111111 表示 zlend (十进制的 255,十六进制的 oxff)
data 表示真实存的数据,可以是字符串或者整数,从编码可以得知类型和长度。知道长度,就知道 data 的起始位置了。
比较特殊的是,整数 1 ~ 13 (0001 ~ 1101),因为比较短,刚好可以塞在 encoding 字段里面,所以就没有 data。
通过上面的分析,我们知道:
prevlenprevlen现在我们来考虑一种情况:假设一个压缩列表中,有多个长度 250 ~ 253 的节点,假设是 entry1 ~ entryN。
因为都是小于 254,所以都是用 1 个字节保存 prevlen。
如果此时,在压缩列表最前面,插入一个 254 长度的节点,此时它的长度需要 5 个字节。
也就是说 entry1.prevlen 会从 1 个字节变为 5 个字节,因为 prevlen 变长,entry1 的长度超过 254 了。
这下就糟糕了,entry2.prevlen 也会因为 entry1 而变长,entry2 长度也会超过 254 了。
然后接着 entry3 也会连锁更新。。。直到节点不超过 254, 噩梦终止。。。
这种由于一个节点的增删,后续节点变长而导致的连续重新分配内存的现象,就是连锁更新。最坏情况下,会导致整个压缩列表的所有节点都重新分配内存。
每次分配空间的最坏时间复杂度是 \(O(n)\),所以连锁更新的最坏时间复杂度高达 \(O(n^2)\) !
虽然说,连锁更新的时间复杂度高,但是它造成大的性能影响的概率很低,原因如下:
因此,压缩列表插入操作,平均复杂度还是 \(O(n)\).
本文的分析没有特殊说明都是基于 Redis 6.0 版本源码
redis 6.0 源码:https://github.com/redis/redis/tree/6.0
标签:情况 代码实现 head ade 展示 不能 tps 字节 lazy
原文地址:https://www.cnblogs.com/chenchuxin/p/14199444.html