标签:字符 方式 class 平台 响应 -- mamicode img text

对代码、编程感兴趣的可以关注老K玩代码和我交流!
“声明:本文旨在技术分享,谢绝以此投机取巧~!出于好奇,我花了点本钱,把软件买了一下,然后研究了一下它背后的代码逻辑。

from selenium.webdriver import Chromedr = Chrome()
dr.implicitly_wait(5)
dr.maximize_window()from selenium.webdriver.chrome.options import Options
options = Options()
options.add_argument(‘--headless‘)
dr = Chrome(options=options)
dr.implicitly_wait(5)
dr.maximize_window()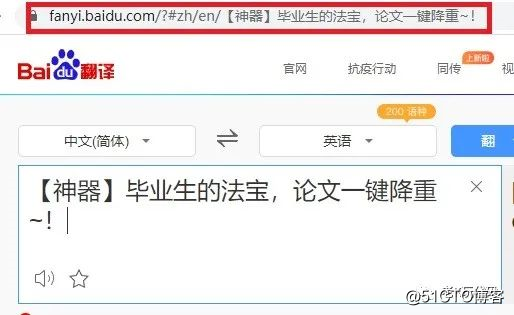
从上述截图,我们可以看出,百度翻译的借口非常简洁,使用get方式写成的。图中zh就是输入语言名,en就是输出语言名,url链接最后就是需要翻译的文本内容。于是我们的请求代码就可以写成这样
url = f"https://fanyi.baidu.com/#{input_lang}/{output_lang}/{text}"
dr.get(url)发出请求后,等待几秒,等页面打开后,将相应的翻译文本保存到变量中
text = dr.find_element_by_class_name("target-output").text.strip()
不同的翻译工具,借口和解析路径不同。还是需要一些前端的选择器知识才行。
这一步其实就是之前内容的重复,唯一区别就是把输入语言和输出语言进行对换。这里就不再重复展示代码了。
以上提及的代码内容,仅用于展示和分享作业思路。完整代码如下:
# encoding: utf-8
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
def do_repetition(text):
options = Options()
options.add_argument(‘--headless‘)
dr = Chrome(options=options)
dr.implicitly_wait(5)
dr.maximize_window()
for i in range(2):
if i == 0:
input_lang = ‘zh‘
output_lang = ‘en‘
else:
input_lang = ‘en‘
output_lang = ‘zh‘
url = f"https://fanyi.baidu.com/#{input_lang}/{output_lang}/{text}"
dr.get(url)
text = dr.find_element_by_class_name("target-output").text.strip()
dr.close()
return text如果想要真正实现文本降重的功能,可能还需要在细节上打磨一下,诸如:

标签:字符 方式 class 平台 响应 -- mamicode img text
原文地址:https://blog.51cto.com/15069443/2576236