标签:过滤 腾讯 公众号 平台 搜索 计算 统计 人民日报 解决
【导读】在给大家分享基础入门知识的同时,我们也会带领大家去阅读一些相关领域的书籍。以做阅读理解的态度为大家剖析书中知识点,相信你如果能够跟上我们的节奏一起学习,一定会有所收获。今天给大家分享的这本书是机械工业出版社出版的《数据挖掘概念与技术》(作者:Jiawei Han;Micheline Kamber;翻译:范明 / 孟小峰)。我们首先来看下本书的第一章。
关于第一章
关于第一章,我先说我的结论。我觉得第一章可读性不大。因为第一章主要是引论,太粗线条了, 本章涉及的概念太多, 对于初学者,很容易陷入纠结或沮丧,从而止步第一章, 再也没信心读下去。对于算法大神, 本章没有提供新的东西, 泛泛介绍而已。对于有些基础的半瓶子同学,概念都接触过,坚持读完本章没问题, 但收获不会很多, 我们的灰灰匠同学有一个精辟的总结:"看完标题兴致勃勃的进去了, 读完本章骂骂咧咧的出来了"。
不过呢,为了满足一些同学的好奇心,我将第一章涉及的内容汇总成了一份思维导图,供大家参考。
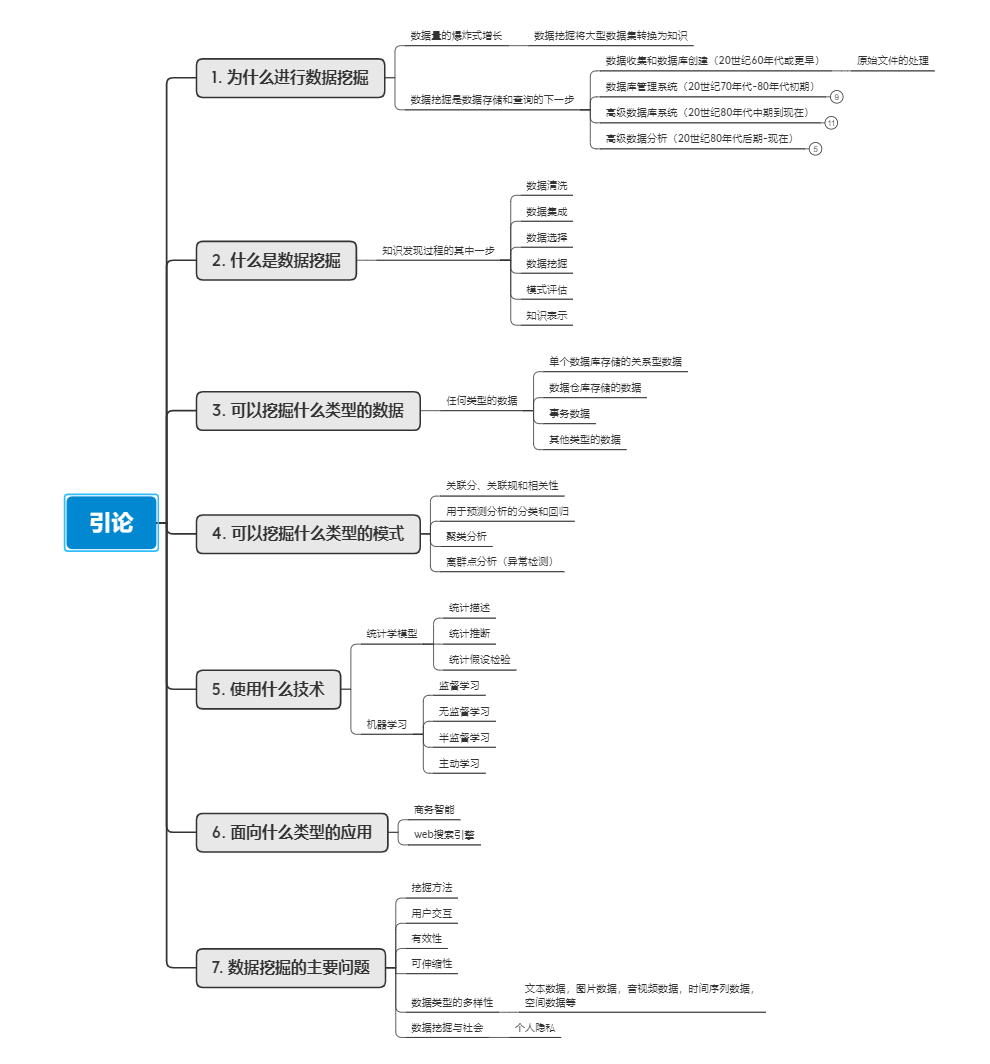
到这里,其实第一章就完结了。不过本章内容过于冗长而枯燥,我下面结合另外一本书:《机器学习实战 基于Scikit-Learn和TensorFlow》的综述内容,来跟大家聊聊到底什么是机器学习。
什么是机器学习
机器学习不是真的让机器像人类一样思考,也不是模仿人类的行为,更不会使机器拥有自己的感情。机器学习能够使机器在没有设定明确规则的情况下,通过数学计算得到特定的结论,看起来好像机器具备了学习能力。
比如垃圾邮件过滤器, 先将大量带有标签的垃圾邮件和正常邮件的文本内容做词频统计,通过不断优化机器学习算法的计算方式,能够让机器很精确的区分出哪些是垃圾邮件, 哪些是正常回邮件。
不断优化机器学习算法的过程称为训练机器学习。训练机器学习算法时使用的邮件文本称为训练集或训练样本。什么是垃圾邮件,怎样算好的分类结果,都需要人为设定,机器学习算法会不断修改参数,逐步逼近人类设定的目标。
为什么要使用机器学习
1.自动和快速
只要设定了好坏的标准,机器学习算法可以自动更新参数,以快速适应新的数据环境, 比如垃圾邮件识别中, 可以自动发现新出现的可以作为垃圾邮件预测因素的词汇组合。
2.识别未知因素
有时候机器学习可以识别未被人类发现的关键影响因素, 如垃圾邮件中某些特定单词同时出现预示着垃圾邮件,人类可能无法发现。
3.处理海量数据
分析海量高维数据时,已超出人类大脑的处理能力,机器学习可以轻松处理并获得知识洞见。
机器学习的种类
机器学习可以根据是否在人类监督下训练分为监督学习,无监督学习,半监督学习和强化学习。根据是否可以动态学习分为在线学习和批量学习。另外还有基于实例的学习和基于模型的学习。
监督学习
分类和回归是典型的监督学习, 一些重要的监督学习算法有:K近邻算法,线性回归,逻辑回归,支持向量机,决策树和随机森林
无监督学习
对没有标签的数据进行学习,并得出结论。
一些重要的无监督学习算法:K-Means, 分层聚类分析, 最大期望算法,主成分分析, 关联规则学习等
其中,异常检测是无监督学习的一个重要应用场景,如信用卡欺诈交易的识别
半监督学习
有些算法可以处理部分标记的训练数据——通常是大量未标记数据和少量的标记数据。这称为半监督式学习
强化学习
强化学习能够观察环境,做出选择,执行操作,并获得奖励或者惩罚,所以它必须自行学习什么是最好的策略。例如,许多机器人通过强化学习算法来学习如何行走,DeepMind的AlphaGo项目也是一个强化学习的好例。
批量学习和在线学习
在线学习可以从传入的数据流中进行增量学习,可以将循序渐进的给系统提供训练数据逐步积累学习成果。批量学习大多是离线完成的, 它必须使用所有的数据进行训练,先训练再投入生产系统。
基于实例的学习和基于模型的学习
基于实例的学习, 如k近邻, 首先记住训练集每个样本的标签, 来了新的数据首先计算新样本与哪些已知标签的样本最相似,根据已知样本的标签预测新样本的标签。
基于模型的学习,首先根据训练集训练出一个模型, 新的数据进来后, 根据模型给出预测结果
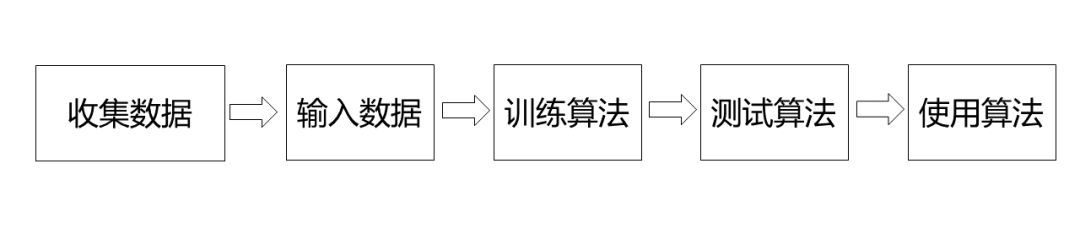
开发机器学习程序的步骤
步骤:收集数据→准备输入数据→训练算法→测试算法→使用算法
机器学习主要的挑战
1.训练数据不足
通常是带有的标签的数据不足,如要训练一个识别图片中猫的模型, 图片可以很轻松的下载到,但带有是否包含猫的标签的图片很难大批量的下载到。信用卡套现交易识别中, 最难获取到底哪些交易是真的套现交易,因为,即使通过一些算法识别出某些用户在套现,但无法证实或证实的成本太高,即使打电话询问,用户也不会承认自己在套现。
2.训练数据不具有代表性
如腾讯在用于搜索引擎的自然语言模型训练时,刚开始使用的语料库为人民日报语料库,模型上线后效果很不理想, 后来使用随机抓取的网页数据作为训练模型的语料库,模型效果显著提升,原因是网页搜索词的口语化严重,而人民日报用词非常正式和规范,训练数据无法代表实际应用场景。
3.数据质量差
训练集中包含太多的错误数据,异常值, 缺失值,噪声数据等, 将严重阻碍模型的精度,因为模型只能发现规律,学习规律并将学习到的模式应用于新的样本,训练数据的数据质量将直接决定模型表现的上限。
4.无关特征
只有训练集中包含足够的相关特征,系统才能完成学习, 一个成功的机器学习项目,关键部分是提取出一组好的用来训练的特征集,这个过程叫特征工程。包括以下几点:
① 特征选择
② 特征提取:使用现有特征衍生出新的特征组合
③ 收集新的数据源,得到新的特征
5.训练数据过拟合
比如:我小时候就觉得世界其他地方绝大部分是广袤的平原,电视里的大山,大海,沙漠只是很远的地方才有的少数现象,但实际上,平原才是少数现象,我只观察到了眼前的有限天地,对世界的认知存在严重的过拟合了。解决过拟合的方法:
① 简化模型
② 收集更多的训练样本
③ 减少训练集中的噪声(如删除错误数据,消除异常值等)
6.训练数据拟合不足
模型表现太差, 在训练集上不能正确的预测出数据的标签,解决的办法是,选择更强大的模型,找到更多更好的特征变量,减少模型约束(如减少正则化)
机器学习测试与验证
一般将数据分成两部分:训练集和测试集, 训练集用来训练模型,测试集用来测试模型的好坏。因为训练模型时只使用了训练集,模型并没有见过测试集中的样本, 使用训练好的模型预测测试集样本的标签,将能够测试模型的在新样本中的泛化效果。其中衡量模型效果好坏的有很多指标,如回归预测中的均方误差(MSE),分类问题的 准确率,召回率,roc,ks等
机器学习编程语言
机器学习本质是数据的计算,迭代优化和对结果的评价,它可以使用任何编程语言, 很多机器学习库都是C语言或C++语言实现的, 但提起机器学习,人们第一个想到的应该是python, 主要因为python语言下有丰富的第三方库可以直接调用,也有最多的机器学习博客,书籍,视频教程,在机器学习领域,相比其他语言python有最大广度和深度的生态环境。
最后要说的话
后续我们会以《数据挖掘概念与技术》为主线发布系列文章,希望与对数据挖掘感兴趣的同学一起学习,但一本书的作用总是有局限,本系列文章会综合其它书的内容(大概十几本)以及kaggle中别人的代码,博采众长将书中提到的内容学透彻。如何利用kaggle学习,可以参考我们公众号的另一篇文章"kaggle新手如何在平台学习大神的代码"
在公众号"数据臭皮匠" 回复 "机器学习实战"获取电子版《机器学习实战 基于Scikit-Learn和TensorFlow》吧
觉得本文对你有帮助,请分享给更多的人
长按二维码关注我们的公众号哦

标签:过滤 腾讯 公众号 平台 搜索 计算 统计 人民日报 解决
原文地址:https://www.cnblogs.com/shujuchoupijiang/p/14204330.html