标签:replace 处理 知识 pre png 作业 dao 构建 yarn
1.为什么安装Impala一定要先安装Hive?
Impala是基于Hive的大数据实时分析查询引擎,直接使用Hive的元数据库Metadata,意味着impala元数据都存储在Hive的metastore中。
2.Impala与Hive的关系?
Impala 与Hive都是构建在Hadoop之上的数据查询工具各有不同的侧重适应面,但从客户端使用来看Impala与Hive有很多的共同之处,如数据表元数 据、ODBC/JDBC驱动、SQL语法、灵活的文件格式、存储资源池等。Impala与Hive在Hadoop中的关系如下图所示。Hive适合于长时间的批处理查询分析,而Impala适合于实时交互式SQL查询,Impala给数据分析人员提供了快速实验、验证想法的大数 据分析工具。可以先使用hive进行数据转换处理,之后使用Impala在Hive处理后的结果数据集上进行快速的数据分析。
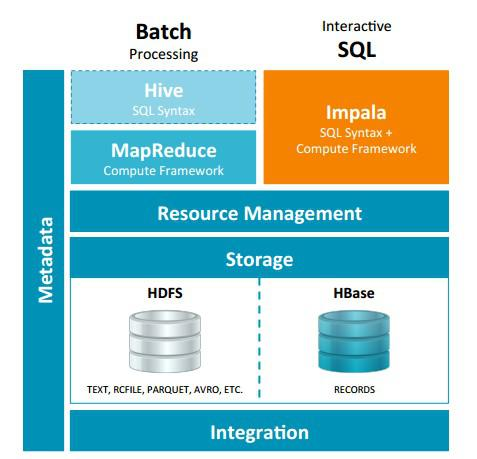
3.Impala为什么计算速度快?
最大使用内存,中间结果不写磁盘。(还有其他的特点)
4.Impala需不需要用到Yarn调度?
Impala和Hive都是提供对HDFS/Hbase数据进行SQL查询的工具,Hive会转换成MapReduce,借助于YARN进行调度从而实现对HDFS的数据的访问,而Impala直接对HDFS进行数据查询。
5.Impala和Hive的由来
Apache Hive是MapReduce的高级抽象,使用HiveQL,Hive可以生成运行在Hadoop集群的MapReduce或Spark作业。Hive最初由Facebook大约在2007年开发,现在是Apache的开源项目。
Apache Impala是高性能的专用SQL引擎,使用Impala SQL,因为Impala无需借助任何的框架,直接实现对数据块的查询,所以查询延迟毫秒级。Impala受到Google的Dremel项目启发,2012年由Cloudera开发,现在是Apache开源项目。
6.Impala有什么不足?
①内存限制;
②不支持UDF,能处理的问题域有一定的限制,与Hive配合使用,对Hive的结果数据集进行实时分析。
7.Impala一般用在什么场景?
实时数据分析。
我目前用来查询Kudu中的数据,速度还比较快。
更多内容访问:https://www.cnblogs.com/zlslch/p/6785207.html?utm_source=itdadao&utm_medium=referral
标签:replace 处理 知识 pre png 作业 dao 构建 yarn
原文地址:https://www.cnblogs.com/beihang09/p/14224781.html