标签:获取 索引基础 放弃 分离 搜索 高性能 b-tree www 是你
数据行列的顺序十分重要,因为mysql只能高效的使用索引的最左前缀列最左前缀列就是KEY(id, name, sex),id在id、name、sex里面是写在左边的,这就叫最左前缀在存储引擎层而不是服务器层实现的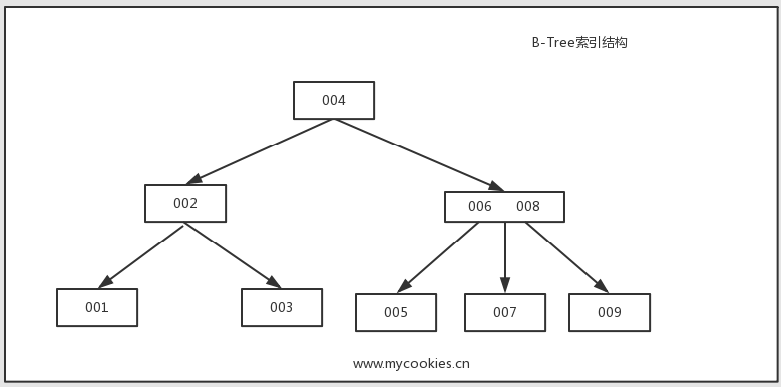
KEY(id, name, sex),先对id排序,再是name,最后是sex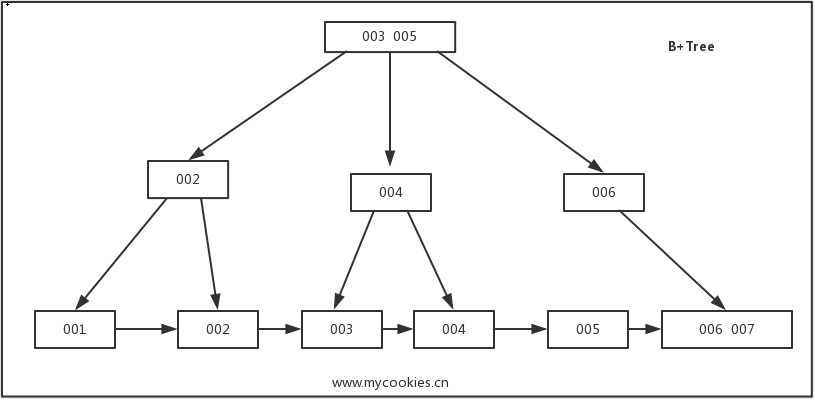
是B-Tree的改进版本,同时也是数据库索引索引所采用的存储结构。数据都在叶子节点上,并且增加了顺序访问指针,每个叶子节点都指向相邻的叶子节点的地址。相比B-Tree来说,进行范围查找时只需要查找两个节点,进行遍历即可。而B-Tree需要获取所有节点,相比之下B+Tree效率更高
当使用一下查询类型是可以使用B-Tree索引 假设有以下索引:KEY(id, name, sex)这个id不一定是唯一标识,例如班级编号等
最左前缀原则来查询的话,则无法使用索引:例如无法查找name=张三的人,也无法查找sex=女的人,因为他们都不是key里面最左边的。同理如果第一个索引不是id是name,无法查找名字中以“三”结尾的人,因为以**结尾不是最左原则有某个列的范围查询,则其右边的所有列都无法使用索引优化查询:例如查询id=5 and name like ‘李%’ and sex=女的人,因为name列使用了范围查询(like),所以sex无法使用,只会使用前两列索引只有精确匹配索引所有列的查询才有效。KEY USING HASH(name),哈希索引会计算所有name列的值(是值整体,不是值的某一部分),得到一个hash码存储在索引中,同时在哈希表中保存每个hash码指向的数据行的指针name=张三的时候,哈希索引会计算张三这个值,然后得到一个hash码,再根据这个hash码在哈希表中找到指定的行的指针,然后找到这行,取这行name的值计算hash看看是否等于“张三”,确保就是要查找的行。部分索引列匹配查找,因为哈希要计算全部值得hash码 只支持精确查找,无法用于部分查找和范围查找 无法用于排序与分组=、 IN>一类的查询自动创建哈希索引URL,有时候URL会很大,不适合B-Tree索引,可以使用哈希索引,通过计算URL的hash码,是比较快的方式先讲一下有哪些策略,再讲一下,一些索引的特点
索引的选择性是指:不重复的索引值和记录总数的比值。最大值为 1,此时每个记录都有唯一的索引与其对应。选择性越高,查询效率也越高。 对于数据量比较小的索引可以放到最左,例如dog在数据库中有100条记录,cat在数据库中有56231条记录,可以把dog放到最左。因为更小意味着速度更快(前提是你会查它)key最好是有顺序的,例如int型自增的idSELECT film_id, actor_ id FROM sakila.film_actor WHERE actor_id = 1 AND film_id = 1;
主键值,还需要再根据主键值去聚簇索引中查找数据行可以极大地提高性能覆盖查询到的所有字段,比如查询涉及到的字段为 a,b,c,那么就在这三个字段上设置索引,因为索引的本身包含了这些字段的值,因此也不需要进行磁盘操作。select id from user where id < 5;返回如下|------| | id | |------| | 2 | | 3 | | 4 | -------- ?
虽然只返回了2、3、4行的数据,但是实际上是获得了1~4行的排它锁(X锁),只有在查询结束后X锁才会被释放
标签:获取 索引基础 放弃 分离 搜索 高性能 b-tree www 是你
原文地址:https://www.cnblogs.com/tracydzf/p/14229869.html