标签:submit run listen 对象 ext 技术 may iter erro
? SparkContext对象包含有一个私有属性DAGScheduler阶段调度器,主要用于阶段的划分。在一个应用程序中,任务的提交都是从行动算子触发的。行动算子的方法内部会调用一个runJob方法,其中就有DAG调度器发挥运行Job的作用:
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
? runJob方法中,会执行submitJob方法:
val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties)
? 继续查看这个方法的源码,其内部的重点代码区域如下:
val waiter = new JobWaiter[U](this, jobId, partitions.size, resultHandler)
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
Utils.cloneProperties(properties)))
? 此处有一个JobSubmitted事件,这个事件作为post方法的参数,该post方法主要用于将事件放入到一个队列中,然后等待事件线程执行队列中的事件:
def post(event: E): Unit = {
if (!stopped.get) {
if (eventThread.isAlive) {
eventQueue.put(event)
} else {
onError(new IllegalStateException(s"$name has already been stopped accidentally."))
}
}
}
? 查看这个事件线程eventThread,当这个事件线程执行的时候,会运行run方法,在方法的内部会取出事件队列中的事件。
private[spark] val eventThread = new Thread(name) {
setDaemon(true)
override def run(): Unit = {
try {
while (!stopped.get) {
val event = eventQueue.take()
try {
onReceive(event)
} catch {
case NonFatal(e) =>
try {
onError(e)
} catch {
case NonFatal(e) => logError("Unexpected error in " + name, e)
}
}
}
} catch {
case ie: InterruptedException => // exit even if eventQueue is not empty
case NonFatal(e) => logError("Unexpected error in " + name, e)
}
}
}
? 事件取出之后,会将事件传给一个onReceive方法,继续查看该方法的源码,直接点进去会看到显示的是一个抽象的方法,这个抽象方法是位于EventLoop这个抽象类中的,真正执行的onReceive方法是实现这个抽象类的DAGSchedulerEventProcessLoop类中的onReceive方法。
override def onReceive(event: DAGSchedulerEvent): Unit = {
val timerContext = timer.time()
try {
doOnReceive(event)
} finally {
timerContext.stop()
}
}
? 这是阶段调度器的主要事件循环。该方法又将事件传给了doOnReceive方法,
private def doOnReceive(event: DAGSchedulerEvent): Unit = event match {
case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) =>
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)
……
}
? 该方法中包含模式匹配,JobSubmitted事件正好可以匹配到第一项,说白了就是DAGScheduler类会向事件队列发送一个消息,消息中包含的是事件,然后事件线程收到消息之后会对消息进行匹配。此处会执行handleJobSubmitted方法,查看其源码,其中
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties): Unit = {
var finalStage: ResultStage = null
try {
// New stage creation may throw an exception if, for example, jobs are run on a
// HadoopRDD whose underlying HDFS files have been deleted.
finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
……
? 这部分区域是对阶段进行划分。createResultStage方法用于ResultStage阶段。
private def createResultStage(
rdd: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
jobId: Int,
callSite: CallSite): ResultStage = {
checkBarrierStageWithDynamicAllocation(rdd)
checkBarrierStageWithNumSlots(rdd)
checkBarrierStageWithRDDChainPattern(rdd, partitions.toSet.size)
val parents = getOrCreateParentStages(rdd, jobId)
val id = nextStageId.getAndIncrement()
val stage = new ResultStage(id, rdd, func, partitions, parents, jobId, callSite)
stageIdToStage(id) = stage
updateJobIdStageIdMaps(jobId, stage)
stage
}
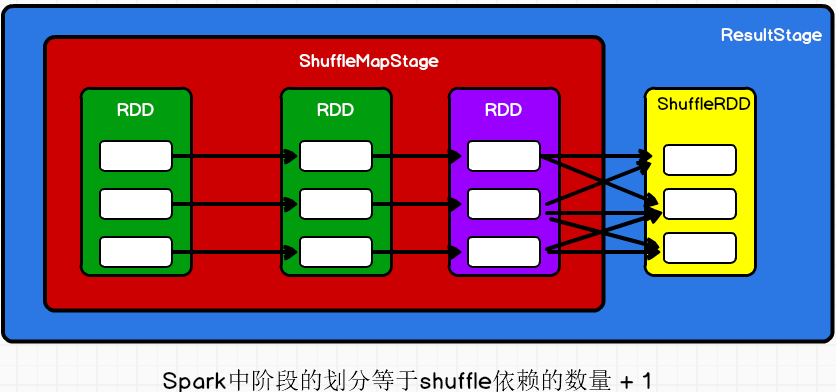
? ResultStage中包含的rdd就是执行行动算子的那个rdd(下图中黄色表示的那个),也就是最后的那个rdd(下图中黄色图表示的rdd)。parents是ResultStage的上一级阶段,parents是getOrCreateParentStages方法的返回值。getOrCreateParentStages用于获取或者创建给定RDD的父阶段列表。
private def getOrCreateParentStages(rdd: RDD[_], firstJobId: Int): List[Stage] = {
getShuffleDependencies(rdd).map { shuffleDep =>
getOrCreateShuffleMapStage(shuffleDep, firstJobId)
}.toList
}
? getShuffleDependencies方法用于获取给定rdd的shuffle依赖,其核心代码如下:
private[scheduler] def getShuffleDependencies(
rdd: RDD[_]): HashSet[ShuffleDependency[_, _, _]] = {
……
while (waitingForVisit.nonEmpty) {
val toVisit = waitingForVisit.remove(0)
if (!visited(toVisit)) {
visited += toVisit
toVisit.dependencies.foreach {
case shuffleDep: ShuffleDependency[_, _, _] =>
parents += shuffleDep
case dependency =>
waitingForVisit.prepend(dependency.rdd)
}
}
}
parents
}
? 核心代码用于判断给定rdd的依赖关系是不是shuffle依赖,如果是则加入结果列表。最终返回的结果列表,会通过map方法将列表中的每一个元素执行getOrCreateShuffleMapStage方法,该方法用于获取或者创建ShuffleMap阶段(写磁盘之前的阶段)。
? getOrCreateShuffleMapStage(shuffleDep, firstJobId) => createShuffleMapStage(shuffleDep, firstJobId)
? createShuffleMapStage方法中会创建ShuffleMapStage对象,并当前rdd(调用行动算子的那个)依赖的rdd(下图紫色那个rdd)传给这个对象。
def createShuffleMapStage[K, V, C](
shuffleDep: ShuffleDependency[K, V, C], jobId: Int): ShuffleMapStage = {
val rdd = shuffleDep.rdd
……
val numTasks = rdd.partitions.length
val parents = getOrCreateParentStages(rdd, jobId)
val id = nextStageId.getAndIncrement()
val stage = new ShuffleMapStage(
id, rdd, numTasks, parents, jobId, rdd.creationSite, shuffleDep, mapOutputTracker)
……
? 此时,ShuffleMap阶段(下图红色区域)就是Result阶段(蓝色区域)的上一级阶段。在上面的代码中,我们还可以看到,如果当前ShuffleMap阶段还有上一级阶段,那么getOrCreateParentStages(rdd, jobId)方法还是会获取它的上一级阶段的,此时这个方法中的rdd就不再是最后一个rdd,而是最后一个rdd的前一个rdd,也就是紫色表示的那个rdd。也就是说,阶段的寻找是一个不断往前的过程,只要含有shuffle过程,那么就会有新的阶段。
标签:submit run listen 对象 ext 技术 may iter erro
原文地址:https://www.cnblogs.com/yxym2016/p/14243673.html