标签:col 绑定 介绍 origin sock 反序 rpc avro 应用层
将内存对象转化为字节流的过程。相对的是反序列化,即将字节流转化为内存对象的过程。
将数据存入文件或者通过网络进行发送,就需要将数据对象转化为字节流。
而究竟如何进行序列化,则需要考虑各种因素,比如性能、占用空间、向前向后的兼容性、多语言支持等等。
优点是简单,缺点是不能表达嵌套格式、图片等二进制文件,数据结构变更可能导致读写代码的修改。
2. 使用特定语言的序列化模块,比如 Java Serialization 等。
这种方式可以表达复杂的对象,对于嵌套格式更是不在话下,但是由于与语言绑定,无法做到跨语言支持。
3. 使用通用的语言格式,比如 JSON、XML
这种方式存在重复的 key,并且对于二进制支持不够,需要 base64 等特殊处理。
4. 当上述 3 种方式的缺点严重阻碍你的应用时,则需要考虑自定义的序列化工具了。这个时候我们希望有一种方法,可以约束每个字段类型,并且提供数据的解析功能。这种带有 schema 的数据格式,常见的有 Thrift、Protobuf、Avro 等。此类序列化框架通常具有以下特征:
谈到序列化与反序列化,最大的应用便是在 RPC 中。
RPC(Remote Procedure Call Protocol)是一种通过网络从远程计算机程序上请求服务,就如同本地调用而不需要了解底层网络技术的协议。
第一层:物理层
第二层:数据链路层 802.2、802.3ATM、HDLC、FRAME RELAY
第三层:网络层 IP、IPX、APPLETALK、ICMP
第四层:传输层 TCP、UDP、SPX
第五层:会话层 RPC、SQL、NFS 、XWINDOWS、ASP
第六层:表示层 ASCLL、PICT、TIFF、JPEG、 MIDI、MPEG
第七层:应用层 HTTP、FTP、SNMP等
可以看到 RPC 位于 TCP/IP 之上的会话层。
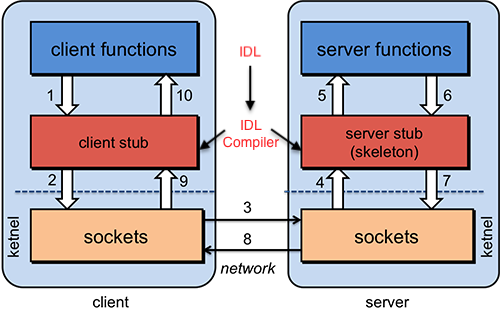
一个完整的 RPC 架构里面包含了四个核心的组件,分别是 Client,Client Stub,Server 以及 Server Stub,这个Stub 可以理解为存根。
其中序列化与反序列化就存在于 Client Stub 和 Server Stub 中,并利用 IDL 生成的代码,另外最底层通过 Sockets 进行传输。
常见的序列化框架有 Thrift、Protobuf、Avro,而由于 Thrift、Avro 可以生成 RPC 实现,所以当提到如 Thrift 服务这种说法时一般指的是 Thrift 实现的 RPC 服务端。而 Protobuf 没有 RPC 实现,所以指的就是序列化与反序列化操作,一般会结合 gRPC 来进行 RPC 实现。
以上介绍了序列化出现的原因,然后简单地介绍了 RPC 的架构,以及其中序列化所处的地位,最后提到一些容易混淆的概念。
标签:col 绑定 介绍 origin sock 反序 rpc avro 应用层
原文地址:https://www.cnblogs.com/fan9998/p/14258156.html