标签:深度学习 方向 限制 判断 led 实体 文档 淘宝商品 empty
摘要:本篇博文从模型和算法的视角,分别介绍了基于统计方法的情感分析模型和基于深度学习的情感分析模型。
文本情感分析(Sentiment Analysis)是指利用自然语言处理和文本挖掘技术,对带有情感色彩的主观性文本进行分析、处理和抽取的过程。目前,文本情感分析研究涵盖了包括自然语言处理、文本挖掘、信息检索、信息抽取、机器学习和本体学等多个领域,得到了许多学者以及研究机构的关注,近几年持续成为自然语言处理和文本挖掘领域研究的热点问题之一。
从人的主观认知来讲,情感分析任务就是回答一个如下的问题“什么人?在什么时间?对什么东西?哪一个属性?表达了怎样的情感?”因此情感分析的一个形式化表达可以如下:(entity,aspect,opinion,holder,time)。比如以下文本“我觉得2.0T的XX汽车动力非常澎湃。”其中将其转换为形式化元组即为(XX汽车,动力,正面情感,我,/)。需要注意的是当前的大部分研究中一般都不考虑情感分析五要素中的观点持有者和时间。
情感分析问题可以划分为许多个细分的领域,下面的思维导图展示了情感分析任务的细分任务:
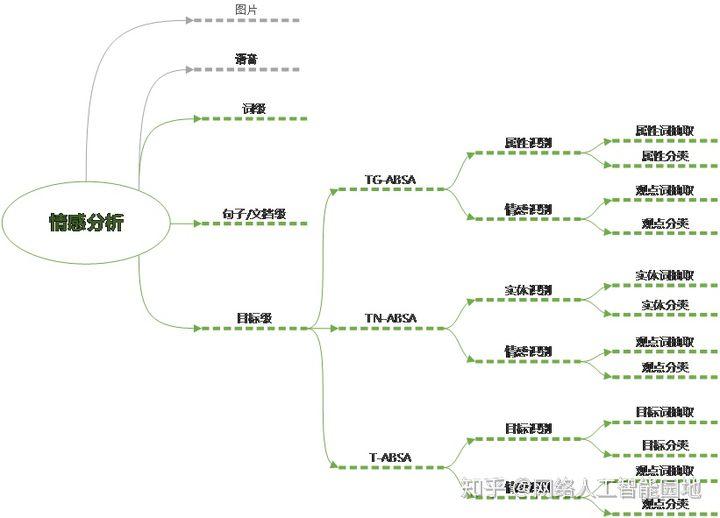
其中词级别和句子级别的分析对象分别是一个词和整个句子的情感正负向,不区分句子中具体的目标,如实体或属性,相当于忽略了五要素中的实体和属性这两个要素。词级别情感分析,即情感词典构建,研究的是如何给词赋予情感信息。句子级/文档级情感分析研究的是如何给整个句子或文档打情感标签。而目标级情感分析是考虑了具体的目标,该目标可以是实体、某个实体的属性或实体加属性的组合。具体可分为三种:Target-grounded aspect based sentiment analysis (TG-ABSA), Target no aspect based sentiment analysis (TN-ABSA), Target aspect based sentiment analysis (T-ABSA). 其中TG-ABSA的分析对象是给定某一个实体的情况下该实体给定属性集合下的各个属性的情感分析;TN-ABSA的分析对象是文本中出现的实体的情感正负向;T-ABSA的分析对象是文本中出现的实体和属性组合。下表例举了不同目标的情感分析任务:

基于统计方法的情感分析方法主要依赖于已经建立的“情感词典”,“情感词典”的建立是情感分类的前提和基础,目前在实际使用中,可将其归为4类:通用情感词、程度副词、否定词、领域词。英文方面主要是基于对英文词典WordNet[1] 的扩充,Hu和Liu[2]在已手工建立种子形容词词汇表的基础上,利用 WorldNet 中词间的同义和近义关系判断情感词的情感倾向,并以此来判断观点的情感极性。中文方面则主要是对知网Hownet[3] 的扩充,朱嫣岚[4]利用语义相似度计算方法计算词语与基准情感词集的语义相似度,以此推断该词语的情感倾向。此外,还可以建立专门的领域词典,以提高情感分类的准确性,比如建立新的网络词汇词典,来更准确的把握新词的情感倾向。
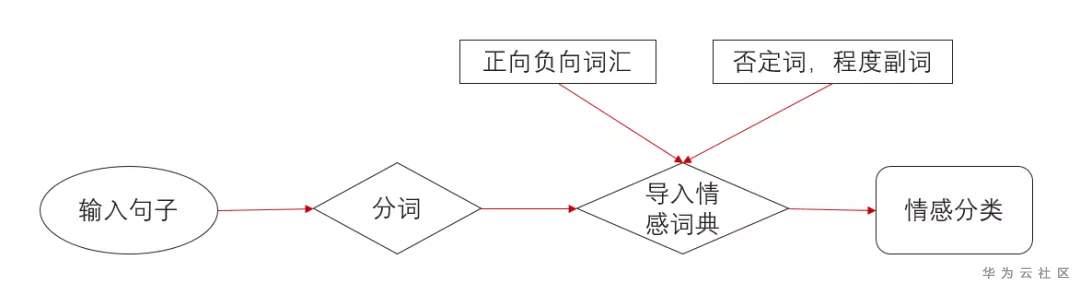
基于情感词典的方法,先对文本进行分词和停用词处理等预处理,再利用先构建好的情感词典,对文本进行字符串匹配,从而挖掘正面和负面信息。其大致流程如图所示:
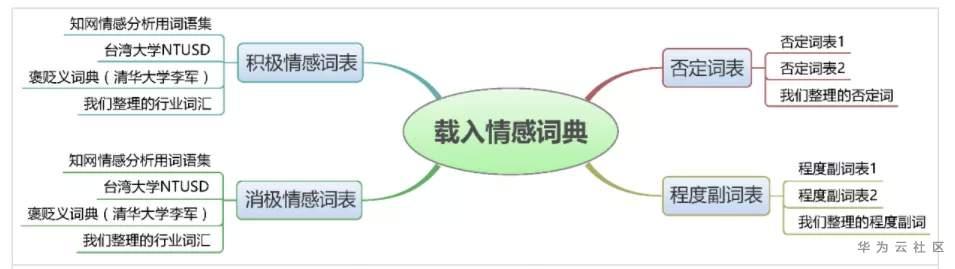
这里处理上述的词典外,下面[5]补充了现有的其它中文词典以供参考:
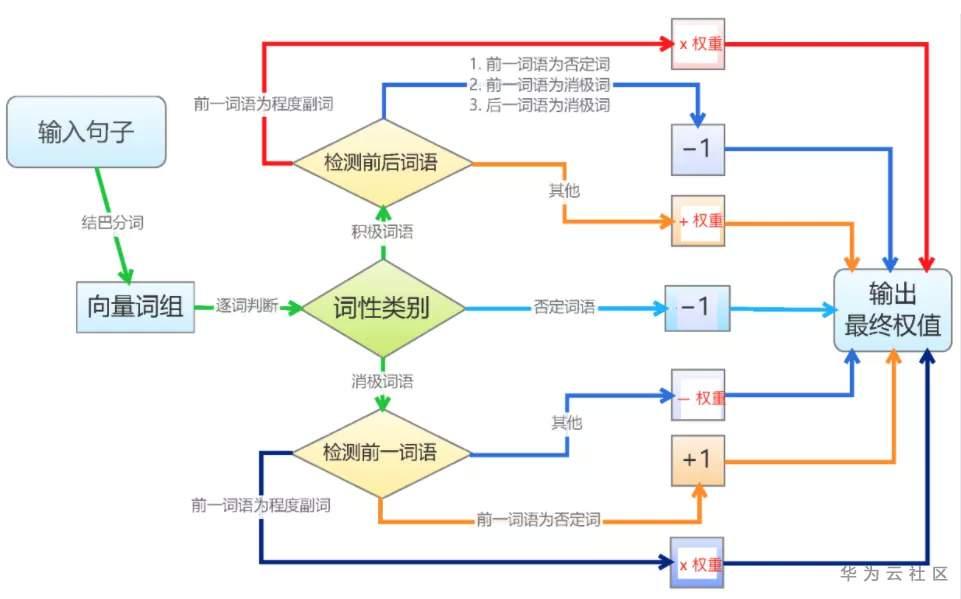
当然也可以通过语料来自己训练情感词典。导入情感词典后,我们需要利用情感词典文本匹配算法进行情感分析。基于词典的文本匹配算法相对简单。逐个遍历分词后的语句中的词语,如果词语命中词典,则进行相应权重的处理。正面词权重为加法,负面词权重为减法,否定词权重取相反数,程度副词权重则和它修饰的词语权重相乘。利用最终输出的权重值,就可以区分是正面、负面还是中性情感了。一个典型的利用情感词典文本匹配算法进行情感分析的算法流程如下[5]:
基于统计方法的情感分析模型简单易行,具有通用和泛化性,但是仍然存在如下三点主要的不足:
语言是一个高度复杂的东西,采用简单的线性叠加显然会造成很大的精度损失。词语权重同样不是一成不变的,而且也难以做到准确。
对于新的情感词,比如给力,牛逼等等,词典不一定能够覆盖。因此需要不断刷新词典来补充新词。在当下网络词汇不断出现的时代,如果词典的刷新速度跟不上新词出现的速度,那么情感分析在实际使用中会与预期相差较大的距离。比如淘宝商品评价,饿了么外卖评价等,如果无法捕捉新词,那么分析的情感将会偏离实际。
基于词典的情感分类,核心在于情感词典。而情感词典的构建需要有较强的背景知识,需要对语言有较深刻的理解,在分析外语方面会有很大限制。
在了解了基于统计方法的情感分析模型优缺点之后,我们看一下深度学习文本分类模型是如何进行文本情感分析分类的。深度学习的一个优势就是可以进行端到端的学习,而省略的中间每一步的人工干预步骤。基于预训练模型生成的词向量,深度学习首先可以解决的一个重要问题就是情感词典的构建。下面我们会以集中典型的文本分类模型为例,展示深度文本分类模型的演进方向和适用场景。
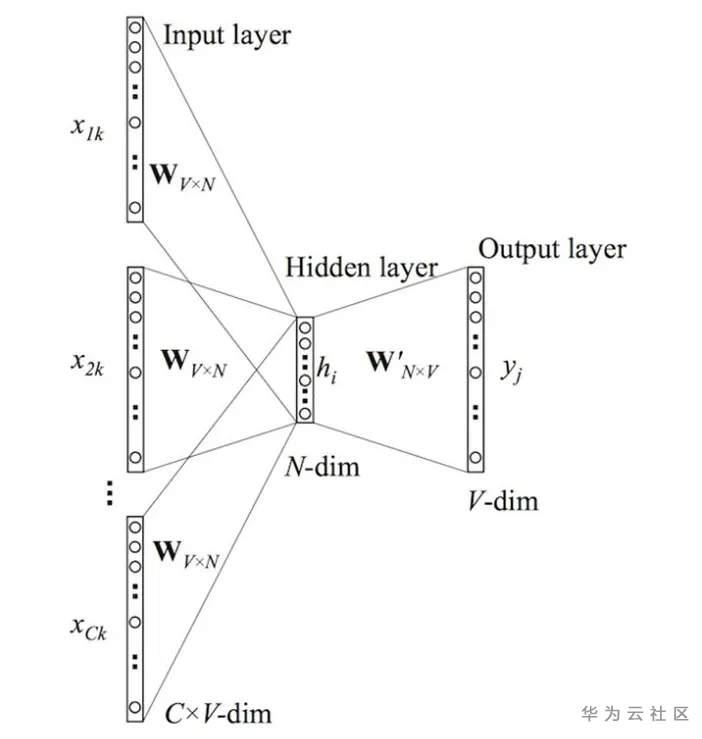
模型运行步骤:


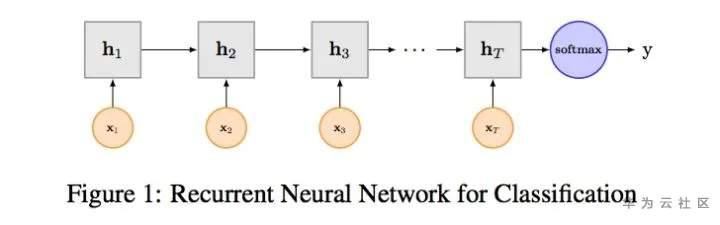
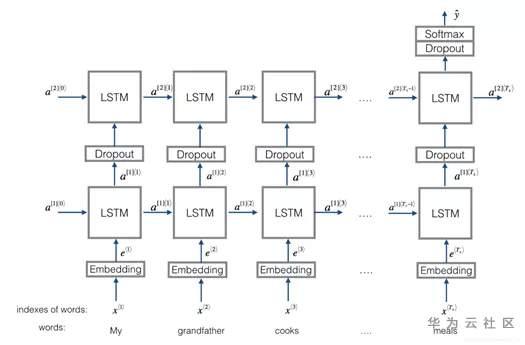

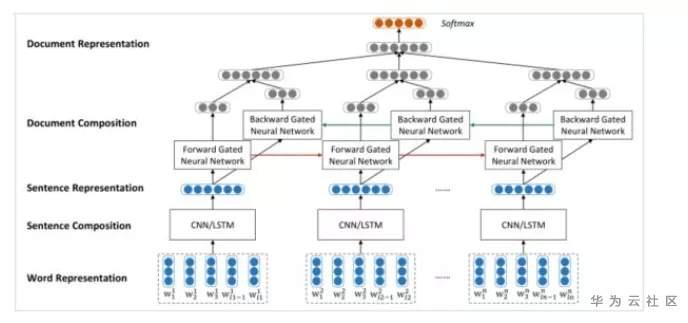
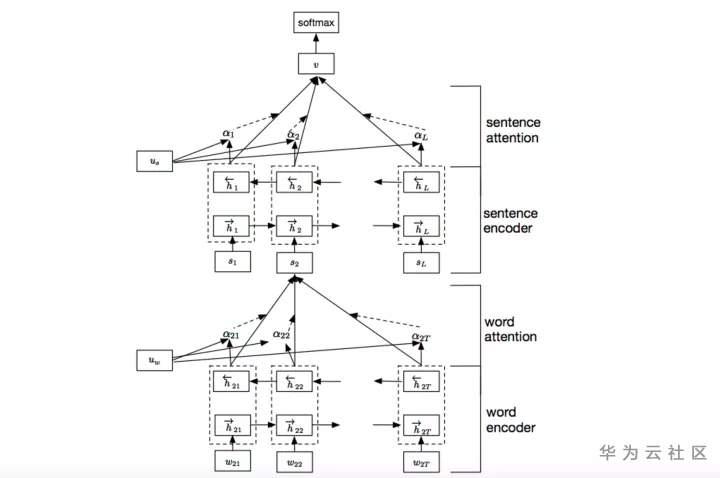
HAN为Hierarchical Attention Networks,将待分类文本,分为一定数量的句子,分别在word level和sentence level进行encoder和attention操作,从而实现对较长文本的分类。相比于上述的算法模型,HAN的结构稍微复杂一些,具体可以分解为以下步骤。

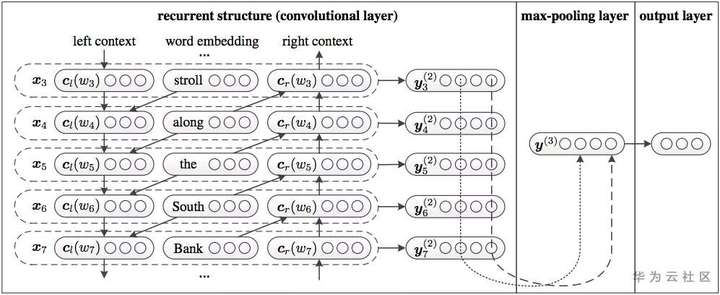
RCNN算法过程:首先,采用双向LSTM学习word的上下文,利用前向和后向RNN得到每个词的前向和后向上下文的表示:
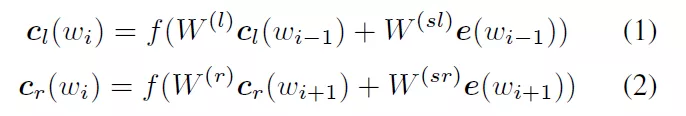
词的表示变成词向量和前向后向上下文向量连接起来的形式:
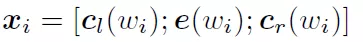
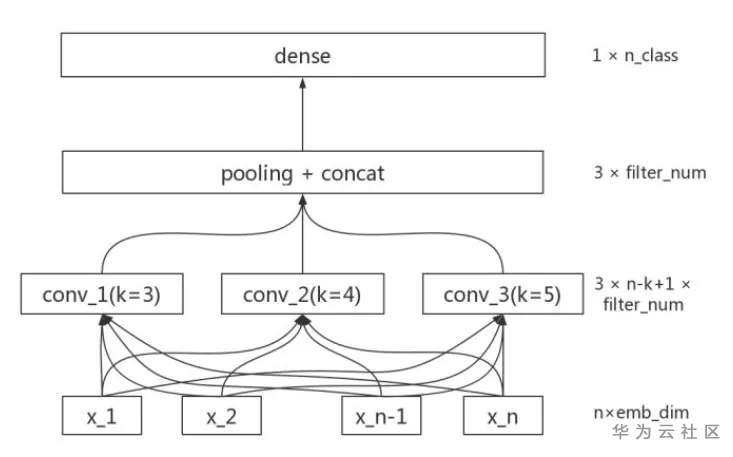
之后再接跟TextCNN相同卷积层,pooling层即可,在seq_length维度进行 max pooling,然后进行fc操作就可以进行分类了,可以将该网络看成是fasttext 的改进版本。
本篇博文从模型和算法的视角,分别介绍了基于统计方法的情感分析模型和基于深度学习的情感分析模型。基于统计方法的情感分析模型简单易用,但是在准确、灵活和泛化性上有较大的缺陷;基于深度学习的模型演进方向是不断通过更深和复杂的网络来捕捉上下文信息,同时借助于强大的预训练模型生成的词向量来训练神经网络来完成这项任务。下面的开源仓库[13]详细介绍了每一种模型的pytorch实现以及在相同的中文baseline上的对比;下面的两篇博文[11][12]也是对其他情感分析深度学习模型进行了详细介绍,可以作为进一步探索的指引。
[1]https://wordnet.princeton.edu/
[2]HU M,LIU B. Mining and summarizing customer reviews[C]. NY,USA:Proceedings of Knowledge Discoveryand Da-ta Mining,2004:168 - 177.
[3]https://languageresources.github.io/2018/03/07/
%E9%87%91%E5%A4%A9%E5%8D%8E_Hownet/
[4]朱嫣岚,闵锦,周雅倩,等. 基于 How Net 的词汇语义倾向计算[J]. 中文信息学报,2006,20(1):14 - 20
[5]https://blog.csdn.net/weixin_41657760/article/
details/93163519
[6]https://arxiv.org/abs/1612.03651
[7]https://arxiv.org/abs/1408.5882
[8]https://www.ijcai.org/Proceedings/16/Papers/408.pdf
[9]https://www.aclweb.org/anthology/P16-2034/
[10]http://zhengyima.com/my/pdfs/Textrcnn.pdf
[11]https://zhuanlan.zhihu.com/p/76003775
[12]https://zhuanlan.zhihu.com/p/73176084
[13]https://github.com/649453932/Chinese-Text-Classification-Pytorch
本文分享自华为云社区《NLP专栏丨情感分析方法入门下》,原文作者:就挺突然 。
标签:深度学习 方向 限制 判断 led 实体 文档 淘宝商品 empty
原文地址:https://www.cnblogs.com/huaweiyun/p/14260896.html