标签:设计 and top ISE 成员 注意 utils cluster 过程
上次我们解释了KafkaProducer的初始化和metadata数据的获取,得到了metadata数据,大伙可能就想他应该发送了吧。
不,它还要讲数据放在accumulater中,然后再真正的发送。
[][https://blog-images-bucket.oss-cn-shanghai.aliyuncs.com/blog_img/image-20210107153854723.png]
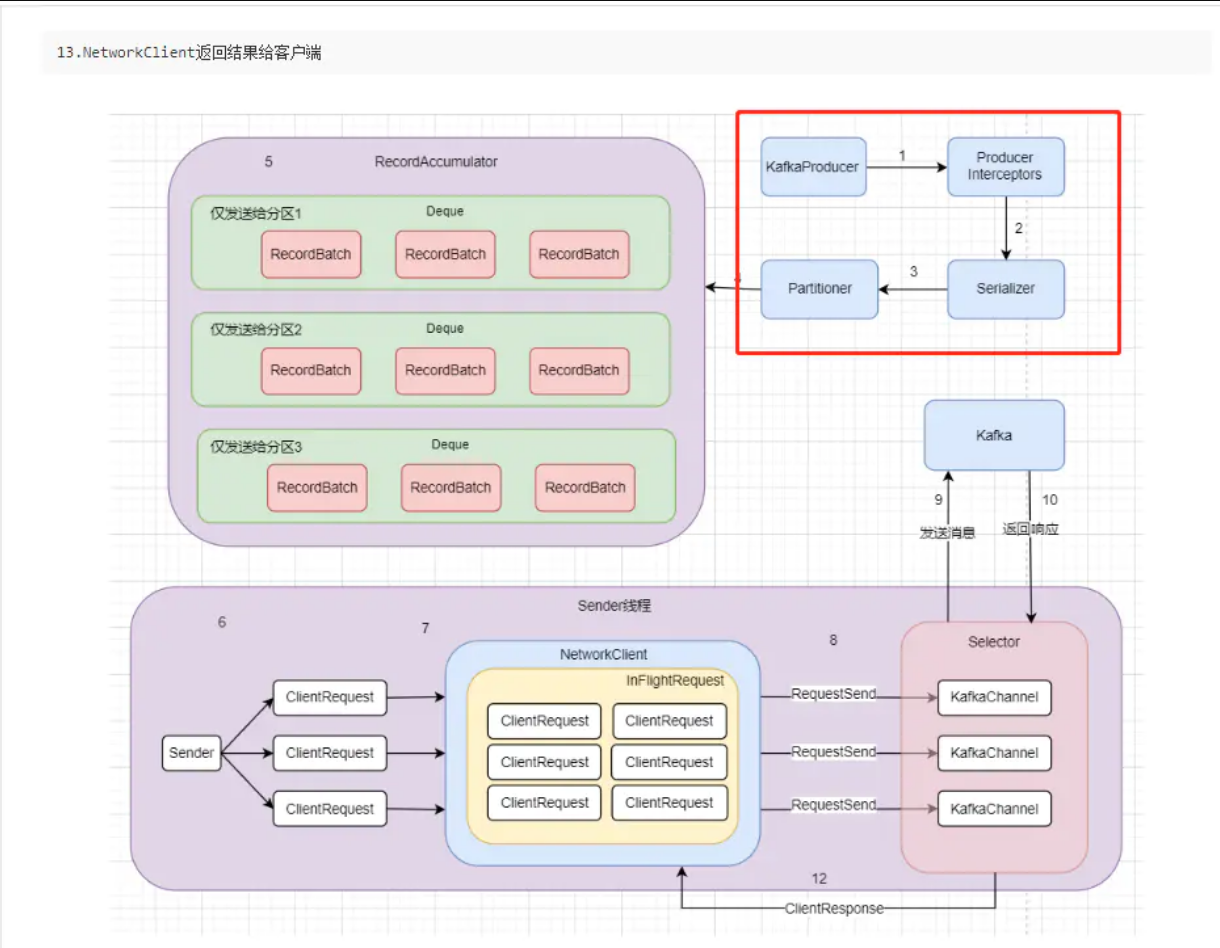
简单地注释下,主要核心的成员变量是batches
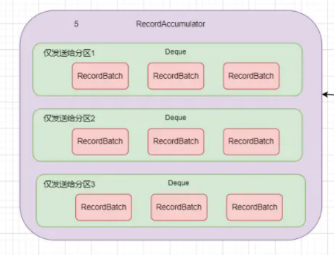
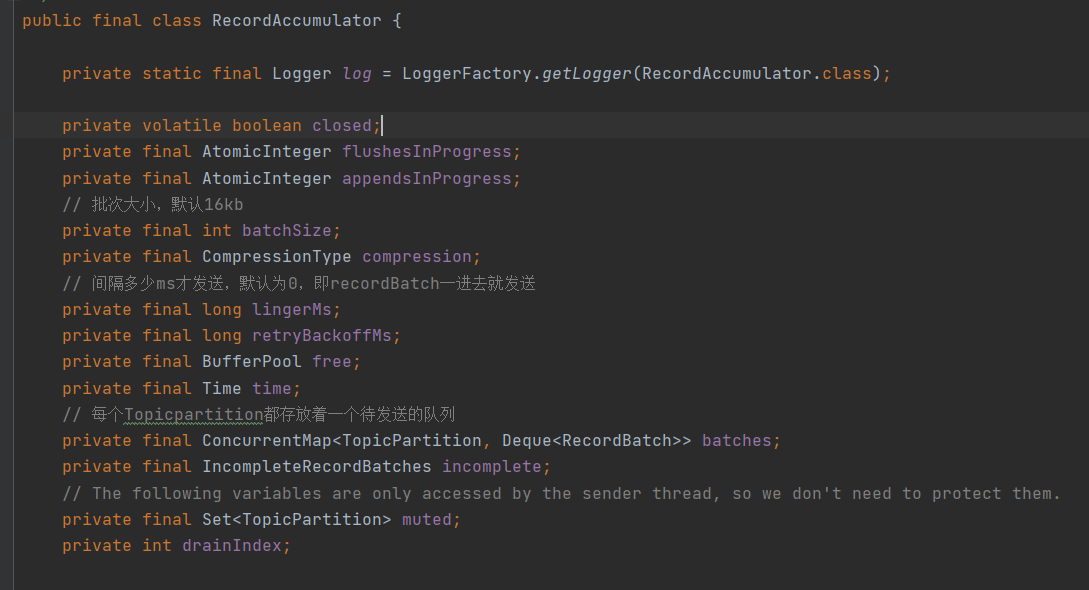
上图能很立体地体现该batches的结构。
我们回到kafkaProducer的doSend方法中。
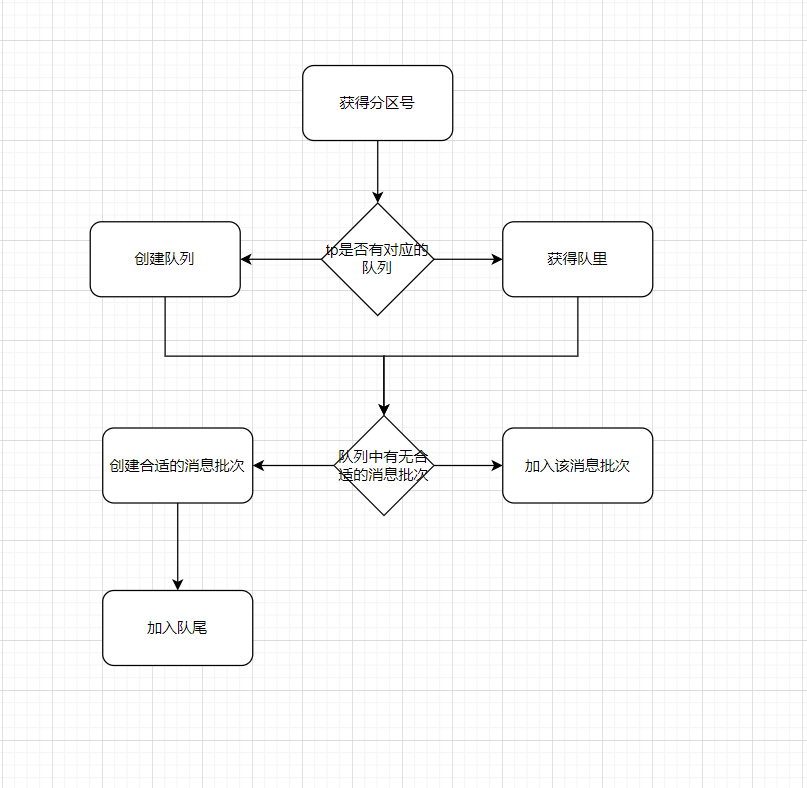
我们从上面对accumlator的成员变量中可知,每个topicParition有一个队列,那么想要发送,得或者其topic的partition。
// 用分区器获得对应的分区
int partition = partition(record, serializedKey, serializedValue, cluster);
这也是因为重试机制的问题,如果一条消息之前已经走过了这里,那就分配上分区号了,可是由于种种原因这条消息没发送成功,但因为Kafka的重试机制重新发送了,那这时我们就不再给它分配了,直接用上一次的分区号即可。
那么我们根据场景驱动,第一次进去肯定是parition肯定是null,所以肯定会触发下述情况。
partitioner.partition(
record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster);
如果在配置的时候没有自己构造分区器,就是使用默认的分区器。
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
int nextValue = counter.getAndIncrement();
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// no partitions are available, give a non-available partition
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
// hash the keyBytes to choose a partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
简单概述这分区器就是:关于维持一个int,然后每次访问该partition方法就会++,然后获得该topic的可用partition的数目。
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
根据上述的算法,获得该topic的分区号。
对于单一topic的话,就是轮询可用的partition,这个record这第一个,那么下个record就会用第二个。
// 创建topicPartition
tp = new TopicPartition(record.topic(), partition);
long timestamp = record.timestamp() == null ? time.milliseconds() : record.timestamp();
log.trace("Sending record {} with callback {} to topic {} partition {}", record, callback, record.topic(), partition);
没啥好说的
我们来到本次的核心的地方,向RecordAccmulator加入信息。
// 将该消息加载到RecordAccumlator中去
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey, serializedValue, interceptCallback, remainingWaitMs);
不妨根据场景驱动一下,加入新的record信息无非就两种情况
这是情况一的场景,注意:合适的RecordBatch,是指由足够的空间的RecordBatch,默认大小是16KB,如果单一Record超过这个大小的话,会额外创建一个专属于它的ByteBuffer,否则就默认拿配套好的16KB的RecordBatch。
// 获得或创建队列
Deque<RecordBatch> dq = getOrCreateDeque(tp);
// 这部分主要是尝试去获取已经创建好的RecordBatch,撘一波顺风车
synchronized (dq) {
if (closed)
throw new IllegalStateException("Cannot send after the producer is closed.");
RecordAppendResult appendResult = tryAppend(timestamp, key, value, callback, dq);
if (appendResult != null)
return appendResult;
}
此外,稍微扩展下,在kafka里面也有池的概念,这个池指的是内存池。想想这样一个场景,如果每次向broker发送。因为底层是使用JAVA的NIO的,所以发送消息到broker都是靠载体Bytebuffer。如果每一次发送完该数据然后就扔给垃圾回收的话,容易造成full GC。
所以,kafkaProducer会维护一个内存池,当发送的record小于。RecordBatch的默认大小的话,就会从内存池中掏一个默认大小的RecordBatch给它,若大于,则会挤挤内存池的容量,尽量挤出一个同样大小的byteBuffer。
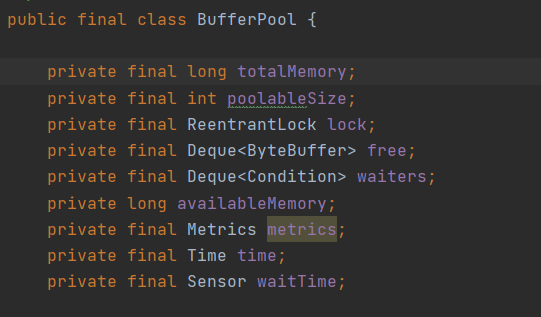
上图,中的free就是内存池的核心。
这是情况二的场景
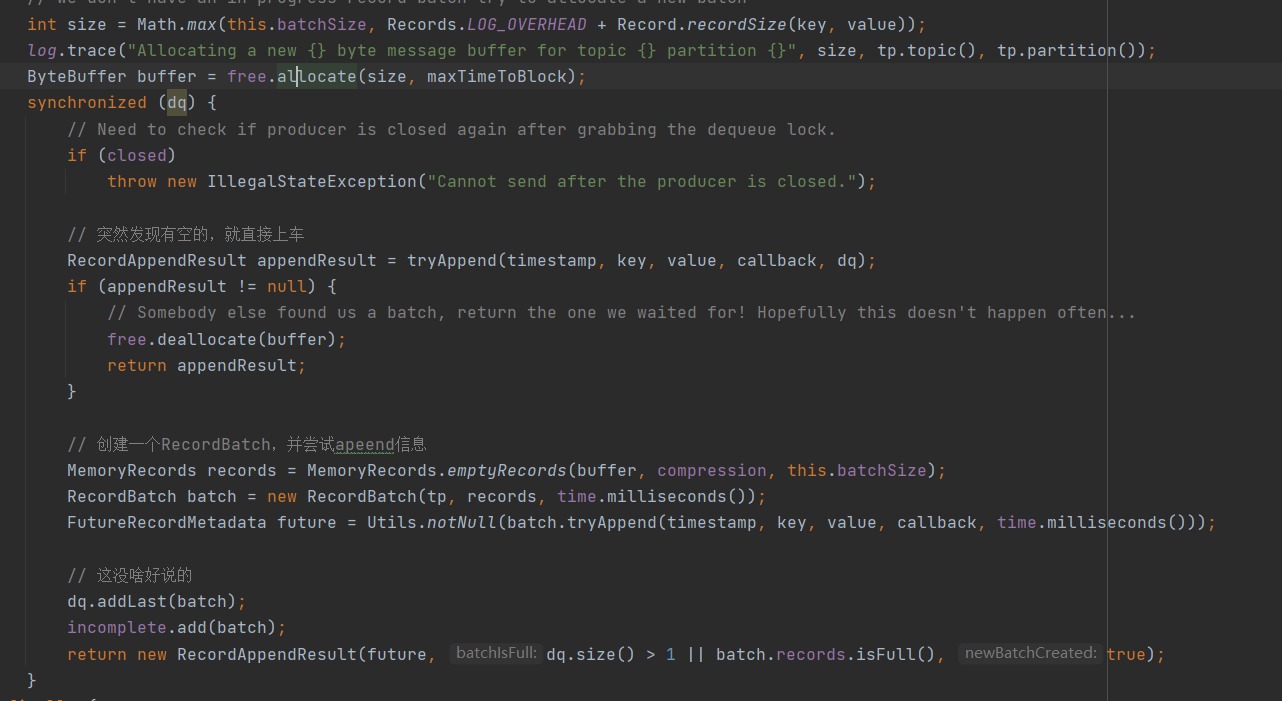
kafkaProducer的设计很精妙,它没有过度依赖同步块。在同步块的外面给内存赋值,然后后面如果发现自己不用创建RecordBatch。就释放该内存。
ByteBuffer buffer = free.allocate(size, maxTimeToBlock);
在创建batch的时候,如果有配置压缩的话,会压缩,然后再创建RecordBatch,最后放在队列的最后面。
总的来说,本章节主要讲的是kafkaProducer将消息放到Accumulator的过程呢。
那怎么存放呢,首先按照轮询的方式或者分区号,然后去accumaltor中创建或者获取对应TopicPartition的队列,然后查看队列中是否有合适的RecordBatch,有直接撘顺风车,没有就创建RecordBatch,然后把Record放进去。
https://juejin.cn/post/6844904039499448328 Kafka源码篇 --- 可能是你看过最详细的RecordAccumulator解读
标签:设计 and top ISE 成员 注意 utils cluster 过程
原文地址:https://www.cnblogs.com/zhoujianyi/p/14262186.html