标签:计算机性能 com wrapper sel 预测 lazy 结果 hot 技术
通过特定的统计方法(数学方法)将数据转换成算法要求的数据
数值行数据:标准缩放:
1.归一化
2.标准化
类别型数据:one-hot编码
时间类型:时间的切分
sklearn特征处理API:
sklearn.preprocessing
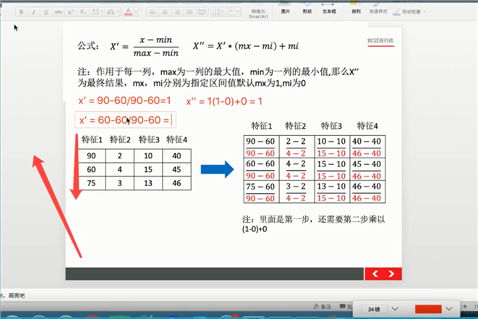
归一化:
特点:通过对原始数据进行变化把数据映射到(默认为【0,1】)之间
公式:X‘ = (x-mim)/max-min X‘‘ = X‘*(mx-mi)+ mi
注:作用与每一列,max为一列的最大值,min为一列的最小值,那么X‘‘为最终结果,mx,mi分别为指定区间值默认mx为1,mi为0
特征选择原因:
冗余:部分特征的相关度高,容易消耗计算机性能。
噪声:部分特征对预测结果有影响。
特征选择是什么:
特征选择就是单纯低从提取到的所有特征中选择部分特征作为训练集特征,特征在选择前和选择后可以改变值,也不该兰芝,但是选择后的特征维数肯定比选择前小,毕竟我盟只选择了其中的一部分特征。
主要方法(三个):filter(过滤式):VarianceThreshold; Embedded(嵌入式):正则化,决策树;Wrapper(包裹式)
特征选择API:
sklearn.feature_selection.VarianceThreshold
54
标签:计算机性能 com wrapper sel 预测 lazy 结果 hot 技术
原文地址:https://www.cnblogs.com/superSmall/p/14273261.html