标签:批量修改 orm 效果 保存数据 range 引擎 int pytho list()
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理
本文章来自腾讯云 作者:Python进阶者

准备数据
import pandas as pd from datetime import datetime, date df = pd.DataFrame({‘Date and time‘: [datetime(2015, 1, 1, 11, 30, 55), datetime(2015, 1, 2, 1, 20, 33), datetime(2015, 1, 3, 11, 10), datetime(2015, 1, 4, 16, 45, 35), datetime(2015, 1, 5, 12, 10, 15)], ‘Dates only‘: [date(2015, 2, 1), date(2015, 2, 2), date(2015, 2, 3), date(2015, 2, 4), date(2015, 2, 5)], ‘Numbers‘: [1010, 2020, 3030, 2020, 1515], ‘Percentage‘: [.1, .2, .33, .25, .5], }) df[‘final‘] = [f"=C{i}*D{i}" for i in range(2, df.shape[0]+2)] df
结果
Pandas直接保存数据
对于这个pandas对象,如果我们需要将其保存为excel,有那些操作方式呢?首先,最简单的,直接保存:
df.to_excel("demo1.xlsx", sheet_name=‘Sheet1‘, index=False)
效果如下:

这说明对于日期类型数据,都可以通过这两个参数指定特定的显示格式,那么我们采用以下方式才创建ExcelWriter,并保存结果:
writer = pd.ExcelWriter("demo1.xlsx", datetime_format=‘mmm d yyyy hh:mm:ss‘, date_format=‘mmmm dd yyyy‘) df.to_excel(writer, sheet_name=‘Sheet1‘, index=False) writer.save()
可以看到excel保存的结果中,格式已经确实的发生了改变:
Pandas的Styler对表格着色输出
如果我们想对指定的列的数据设置文字颜色或背景色,可以直接pandas.io.formats.style工具,该工具可以直接对指定列用指定的规则着色:
df_style = df.style.applymap(lambda x: ‘color:red‘, subset=["Date and time"]) .applymap(lambda x: ‘color:green‘, subset=["Dates only"]) .applymap(lambda x: ‘ color: rgb(153, 153, 153); font-variant-ligatures: normal !important; font-variant-numeric: normal !important; font-variant-east-asian: normal !important; font-stretch: normal !important; line-height: normal !important;">, subset=["Numbers"]) .background_gradient(cmap="PuBu", low=0, high=0.5, subset=["Percentage"]) df_style
显示效果: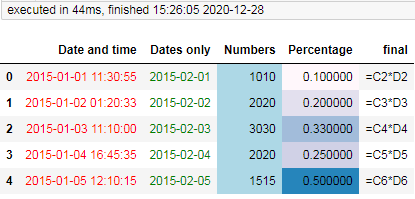
writer = pd.ExcelWriter("demo_style.xlsx", datetime_format=‘mmm d yyyy hh:mm:ss‘, date_format=‘mmmm dd yyyy‘) df_style.to_excel(writer, sheet_name=‘Sheet1‘, index=False) writer.save()
保存效果:
虽然Pandas的Styler样式还包括设置显示格式、条形图等功能,但写入到excel却无效,所以我们只能借助Pandas的Styler实现作色的功能,而且只能对数据着色,不能对表头作色。
Pandas使用xlsxwriter引擎保存数据
进一步的,我们需要将数值等其他类型的数据也修改一下显示格式,这时就需要从ExcelWriter拿出其中的workbook进行操作:
writer = pd.ExcelWriter("demo1.xlsx") workbook = writer.book workbook
结果:
<xlsxwriter.workbook.Workbook at 0x52fde10>
从返回的结果可以看到这是一个xlsxwriter对象,说明pandas默认的excel写出引擎是xlsxwriter,即上面的ExcelWriter创建代码其实等价于:
pd.ExcelWriter("demo1.xlsx", engine=‘xlsxwriter‘)
关于xlsxwriter可以参考官方文档:https://xlsxwriter.readthedocs.org/
下面的代码即可给数值列设置特定的格式:
writer = pd.ExcelWriter("demo1.xlsx", engine=‘xlsxwriter‘, datetime_format=‘mmm d yyyy hh:mm:ss‘, date_format=‘mmmm dd yyyy‘) df.to_excel(writer, sheet_name=‘Sheet1‘, index=False) workbook = writer.book worksheet = writer.sheets[‘Sheet1‘] worksheet.set_column(‘A:A‘, 19) worksheet.set_column(‘B:B‘, 17) format1 = workbook.add_format({‘num_format‘: ‘#,##0.00‘}) format2 = workbook.add_format({‘num_format‘: ‘0%‘}) worksheet.set_column(‘C:C‘, 8, format1) worksheet.set_column(‘D:D‘, 11, format2) worksheet.set_column(‘E:E‘, 6, format1) writer.save()

xlsxwriter按照指定样式写出Pandas对象的数据
假如,我现在希望能够定制excel表头的样式,并给数据添加边框。我翻遍了xlsxwriter的API文档发现,并没有一个可以修改指定范围样式的API,要修改样式只能通过set_column修改列,或者通过set_row修改行,这种形式的修改都是针对整行和整列,对于显示格式还能满足条件,但对于背景色和边框之类的样式就不行了,这点上确实不如openpyxl方便,但xlsxwriter还有个优势,就是写出数据时可以直接指定样式。
下面看看如何直接通过xlsxwriter保存指定样式的数据吧:
import xlsxwriter workbook = xlsxwriter.Workbook(‘demo2.xlsx‘) worksheet = workbook.add_worksheet(‘sheet1‘) # 创建列名的样式 header_format = workbook.add_format({ ‘bold‘: True, ‘text_wrap‘: True, ‘valign‘: ‘top‘, ‘fg_color‘: ‘#D7E4BC‘, ‘border‘: 1}) # 从A1单元格开始写出一行数据,指定样式为header_format worksheet.write_row(0, 0, df.columns, header_format) # 创建一批样式对象 format1 = workbook.add_format({‘border‘: 1, ‘num_format‘: ‘mmm d yyyy hh:mm:ss‘}) format2 = workbook.add_format({‘border‘: 1, ‘num_format‘: ‘mmmm dd yyyy‘}) format3 = workbook.add_format({‘border‘: 1, ‘num_format‘: ‘#,##0.00‘}) format4 = workbook.add_format({‘border‘: 1, ‘num_format‘: ‘0%‘}) # 从第2行(角标从0开始)开始,分别写出每列的数据,并指定特定的样式 worksheet.write_column(1, 0, df.iloc[:, 0], format1) worksheet.write_column(1, 1, df.iloc[:, 1], format2) worksheet.write_column(1, 2, df.iloc[:, 2], format3) worksheet.write_column(1, 3, df.iloc[:, 3], format4) worksheet.write_column(1, 4, df.iloc[:, 4], format3) # 设置对应列的列宽,单位是字符长度 worksheet.set_column(‘A:A‘, 19) worksheet.set_column(‘B:B‘, 17) worksheet.set_column(‘C:C‘, 8) worksheet.set_column(‘D:D‘, 12) worksheet.set_column(‘E:E‘, 6) workbook.close()

import itertools from openpyxl.styles import Alignment, Font, PatternFill, Border, Side, PatternFill font = Font(name="微软雅黑", bold=True) alignment = Alignment(vertical="top", wrap_text=True) pattern_fill = PatternFill(fill_type="solid", fgColor="D7E4BC") side = Side(style="thin") border = Border(left=side, right=side, top=side, bottom=side) for cell in itertools.chain(*worksheet["A1:E1"]): cell.font = font cell.alignment = alignment cell.fill = pattern_fill cell.border = border
上述代码引入的了itertools.chain方便迭代出每个单元格,而不用写多重for循环。
下面再修改数值列的格式:
for cell in itertools.chain(*worksheet["A2:E6"]): cell.border = border for cell in itertools.chain(*worksheet["C2:C6"], *worksheet["E2:E6"]): cell.number_format = ‘#,##0.00‘ for cell in itertools.chain(*worksheet["D2:D6"]): cell.number_format = ‘0%‘
最后给各列设置一下列宽:
worksheet.column_dimensions["A"].width = 20 worksheet.column_dimensions["B"].width = 17 worksheet.column_dimensions["C"].width = 10 worksheet.column_dimensions["D"].width = 12 worksheet.column_dimensions["E"].width = 8
最后保存即可:
writer.save()
整体完整代码:
from openpyxl.styles import Alignment, Font, PatternFill, Border, Side, PatternFill import itertools writer = pd.ExcelWriter("demo3.xlsx", engine=‘openpyxl‘, datetime_format=‘mmm d yyyy hh:mm:ss‘, date_format=‘mmmm dd yyyy‘) df.to_excel(writer, sheet_name=‘Sheet1‘, index=False) workbook = writer.book worksheet = writer.sheets[‘Sheet1‘] font = Font(name="微软雅黑", bold=True) alignment = Alignment(vertical="top", wrap_text=True) pattern_fill = PatternFill(fill_type="solid", fgColor="D7E4BC") side = Side(style="thin") border = Border(left=side, right=side, top=side, bottom=side) for cell in itertools.chain(*worksheet["A1:E1"]): cell.font = font cell.alignment = alignment cell.fill = pattern_fill cell.border = border for cell in itertools.chain(*worksheet["A2:E6"]): cell.border = border for cell in itertools.chain(*worksheet["C2:C6"], *worksheet["E2:E6"]): cell.number_format = ‘#,##0.00‘ for cell in itertools.chain(*worksheet["D2:D6"]): cell.number_format = ‘0%‘ worksheet.column_dimensions["A"].width = 20 worksheet.column_dimensions["B"].width = 17 worksheet.column_dimensions["C"].width = 10 worksheet.column_dimensions["D"].width = 12 worksheet.column_dimensions["E"].width = 8 writer.save()
最终效果:

from openpyxl import load_workbook workbook = load_workbook(‘template.xlsx‘) worksheet = workbook["Sheet1"] # 添加数据列,i表示当前的行号,用于后续格式设置 for i, row in enumerate(df.values, 2): worksheet.append(row.tolist()) # 批量修改给写入的数据的单元格范围加边框 side = Side(style="thin") border = Border(left=side, right=side, top=side, bottom=side) for cell in itertools.chain(*worksheet[f"A2:E{i}"]): cell.border = border # 批量给各列设置指定的自定义格式 for cell in itertools.chain(*worksheet[f"A2:A{i}"]): cell.number_format = ‘mmm d yyyy hh:mm:ss‘ for cell in itertools.chain(*worksheet[f"B2:B{i}"]): cell.number_format = ‘mmmm dd yyyy‘ for cell in itertools.chain(*worksheet[f"C2:C{i}"], *worksheet[f"E2:E{i}"]): cell.number_format = ‘#,##0.00‘ for cell in itertools.chain(*worksheet[f"D2:D{i}"]): cell.number_format = ‘0%‘ workbook.save(filename="demo4.xlsx")
最终效果:
可以明显的看到openpyxl在加载模板后,可以省掉表头设置和列宽设置的代码。
Pandas自适应列宽保存数据
大多数时候我们并不需要设置自定义样式,也不需要写出公式字符串,而是直接写出最终的结果文本,这时我们就可以使用pandas计算一下各列的列宽再保存excel数据。
例如我们有如下数据:
df = pd.DataFrame({ ‘Region‘: [‘East‘, ‘East‘, ‘South‘, ‘North‘, ‘West‘, ‘South‘, ‘North‘, ‘West‘, ‘West‘, ‘South‘, ‘West‘, ‘South‘], ‘Item‘: [‘Apple‘, ‘Apple‘, ‘Orange‘, ‘Apple‘, ‘Apple‘, ‘Pear‘, ‘Pear‘, ‘Orange‘, ‘Grape‘, ‘Pear‘, ‘Grape‘, ‘Orange‘], ‘Volume‘: [9000, 5000, 9000, 2000, 9000, 7000, 9000, 1000, 1000, 10000, 6000, 3000], ‘Month‘: [‘July‘, ‘July‘, ‘September‘, ‘November‘, ‘November‘, ‘October‘, ‘August‘, ‘December‘, ‘November‘, ‘April‘, ‘January‘, ‘May‘] }) df

# 计算表头的字符宽度 column_widths = ( df.columns.to_series() .apply(lambda x: len(x.encode(‘gbk‘))).values ) # 计算每列的最大字符宽度 max_widths = ( df.astype(str) .applymap(lambda x: len(x.encode(‘gbk‘))) .agg(max).values ) # 计算整体最大宽度 widths = np.max([column_widths, max_widths], axis=0) widths
结果:
array([6, 6, 6, 9], dtype=int64)
下面将改造一下前面的代码。
首先,使用xlsxwriter引擎自适应列宽保存数据:
writer = pd.ExcelWriter("auto_column_width1.xlsx", engine=‘xlsxwriter‘) df.to_excel(writer, sheet_name=‘Sheet1‘, index=False) worksheet = writer.sheets[‘Sheet1‘] for i, width in enumerate(widths): worksheet.set_column(i, i, width) writer.save()
然后,使用openpyxl引擎自适应列宽保存数据(openpyxl引擎设置字符宽度时会缩水0.5左右个字符,所以干脆+1):
from openpyxl.utils import get_column_letter writer = pd.ExcelWriter("auto_column_width2.xlsx", engine=‘openpyxl‘) df.to_excel(writer, sheet_name=‘Sheet1‘, index=False) worksheet = writer.sheets[‘Sheet1‘] for i, width in enumerate(widths, 1): worksheet.column_dimensions[get_column_letter(i)].width = width+1 writer.save()

可以看到列宽设置的都比较准确。




Pandas专家总结:指定样式保存excel数据的 “N种” 姿势!
标签:批量修改 orm 效果 保存数据 range 引擎 int pytho list()
原文地址:https://www.cnblogs.com/aa3935919/p/14277271.html